 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemPrivacy: Privacy-Preserving Personalized Memory Management for Edge-Cloud Agents
May 10, 2026As LLM-powered agents are increasingly deployed in edge-cloud environments, personalized memory has become a key enabler of long-term adaptation and user-centric interaction. However, cloud-assisted memory management exposes sensitive user information, while existing privacy protection methods typically rely on aggressive masking that removes task-relevant semantics and consequently degrades memory utility and personalization quality. To address this challenge, We propose MemPrivacy, which identifies privacy-sensitive spans on edge devices, replaces them with semantically structured type-aware placeholders for cloud-side memory processing, and restores the original values locally when needed. By decoupling privacy protection from semantic destruction, MemPrivacy minimizes sensitive data exposure while retaining the information required for effective memory formation and retrieval. We also construct MemPrivacy-Bench for systematic evaluation, a dataset covering 200 users and over 52k privacy instances, and introduce a four-level privacy taxonomy for configurable protection policies. Experiments show that MemPrivacy achieves strong performance in privacy information extraction, substantially surpassing strong general-purpose models such as GPT-5.2 and Gemini-3.1-Pro, while also reducing inference latency. Across multiple widely used memory systems, MemPrivacy limits utility loss to within 1.6%, outperforming baseline masking strategies. Overall, MemPrivacy offers an effective balance between privacy protection and personalized memory utility for edge-cloud agents, enabling secure, practical, and user-transparent deployment.
Language-Agnostic Visual Embeddings for Cross-Script Handwriting Retrieval
Jan 16, 2026Handwritten word retrieval is vital for digital archives but remains challenging due to large handwriting variability and cross-lingual semantic gaps. While large vision-language models offer potential solutions, their prohibitive computational costs hinder practical edge deployment. To address this, we propose a lightweight asymmetric dual-encoder framework that learns unified, style-invariant visual embeddings. By jointly optimizing instance-level alignment and class-level semantic consistency, our approach anchors visual embeddings to language-agnostic semantic prototypes, enforcing invariance across scripts and writing styles. Experiments show that our method outperforms 28 baselines and achieves state-of-the-art accuracy on within-language retrieval benchmarks. We further conduct explicit cross-lingual retrieval, where the query language differs from the target language, to validate the effectiveness of the learned cross-lingual representations. Achieving strong performance with only a fraction of the parameters required by existing models, our framework enables accurate and resource-efficient cross-script handwriting retrieval.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Deep Learning and Large Language Models for Audio and Text Analysis in Predicting Suicidal Acts in Chinese Psychological Support Hotlines
Sep 10, 2024



Suicide is a pressing global issue, demanding urgent and effective preventive interventions. Among the various strategies in place, psychological support hotlines had proved as a potent intervention method. Approximately two million people in China attempt suicide annually, with many individuals making multiple attempts. Prompt identification and intervention for high-risk individuals are crucial to preventing tragedies. With the rapid advancement of artificial intelligence (AI), especially the development of large-scale language models (LLMs), new technological tools have been introduced to the field of mental health. This study included 1284 subjects, and was designed to validate whether deep learning models and LLMs, using audio and transcribed text from support hotlines, can effectively predict suicide risk. We proposed a simple LLM-based pipeline that first summarizes transcribed text from approximately one hour of speech to extract key features, and then predict suicidial bahaviours in the future. We compared our LLM-based method with the traditional manual scale approach in a clinical setting and with five advanced deep learning models. Surprisingly, the proposed simple LLM pipeline achieved strong performance on a test set of 46 subjects, with an F1 score of 76\% when combined with manual scale rating. This is 7\% higher than the best speech-based deep learning models and represents a 27.82\% point improvement in F1 score compared to using the manual scale apporach alone. Our study explores new applications of LLMs and demonstrates their potential for future use in suicide prevention efforts.
An Exploratory Deep Learning Approach for Predicting Subsequent Suicidal Acts in Chinese Psychological Support Hotlines
Aug 29, 2024



Psychological support hotlines are an effective suicide prevention measure that typically relies on professionals using suicide risk assessment scales to predict individual risk scores. However, the accuracy of scale-based predictive methods for suicide risk assessment can vary widely depending on the expertise of the operator. This limitation underscores the need for more reliable methods, prompting this research's innovative exploration of the use of artificial intelligence to improve the accuracy and efficiency of suicide risk prediction within the context of psychological support hotlines. The study included data from 1,549 subjects from 2015-2017 in China who contacted a psychological support hotline. Each participant was followed for 12 months to identify instances of suicidal behavior. We proposed a novel multi-task learning method that uses the large-scale pre-trained model Whisper for feature extraction and fits psychological scales while predicting the risk of suicide. The proposed method yields a 2.4\% points improvement in F1-score compared to the traditional manual approach based on the psychological scales. Our model demonstrated superior performance compared to the other eight popular models. To our knowledge, this study is the first to apply deep learning to long-term speech data to predict suicide risk in China, indicating grate potential for clinical applications. The source code is publicly available at: \url{https://github.com/songchangwei/Suicide-Risk-Prediction}.
Prover-Verifier Games improve legibility of LLM outputs
Jul 18, 2024One way to increase confidence in the outputs of Large Language Models (LLMs) is to support them with reasoning that is clear and easy to check -- a property we call legibility. We study legibility in the context of solving grade-school math problems and show that optimizing chain-of-thought solutions only for answer correctness can make them less legible. To mitigate the loss in legibility, we propose a training algorithm inspired by Prover-Verifier Game from Anil et al. (2021). Our algorithm iteratively trains small verifiers to predict solution correctness, "helpful" provers to produce correct solutions that the verifier accepts, and "sneaky" provers to produce incorrect solutions that fool the verifier. We find that the helpful prover's accuracy and the verifier's robustness to adversarial attacks increase over the course of training. Furthermore, we show that legibility training transfers to time-constrained humans tasked with verifying solution correctness. Over course of LLM training human accuracy increases when checking the helpful prover's solutions, and decreases when checking the sneaky prover's solutions. Hence, training for checkability by small verifiers is a plausible technique for increasing output legibility. Our results suggest legibility training against small verifiers as a practical avenue for increasing legibility of large LLMs to humans, and thus could help with alignment of superhuman models.
Fine-grained Speech Sentiment Analysis in Chinese Psychological Support Hotlines Based on Large-scale Pre-trained Model
May 07, 2024



Suicide and suicidal behaviors remain significant challenges for public policy and healthcare. In response, psychological support hotlines have been established worldwide to provide immediate help to individuals in mental crises. The effectiveness of these hotlines largely depends on accurately identifying callers' emotional states, particularly underlying negative emotions indicative of increased suicide risk. However, the high demand for psychological interventions often results in a shortage of professional operators, highlighting the need for an effective speech emotion recognition model. This model would automatically detect and analyze callers' emotions, facilitating integration into hotline services. Additionally, it would enable large-scale data analysis of psychological support hotline interactions to explore psychological phenomena and behaviors across populations. Our study utilizes data from the Beijing psychological support hotline, the largest suicide hotline in China. We analyzed speech data from 105 callers containing 20,630 segments and categorized them into 11 types of negative emotions. We developed a negative emotion recognition model and a fine-grained multi-label classification model using a large-scale pre-trained model. Our experiments indicate that the negative emotion recognition model achieves a maximum F1-score of 76.96%. However, it shows limited efficacy in the fine-grained multi-label classification task, with the best model achieving only a 41.74% weighted F1-score. We conducted an error analysis for this task, discussed potential future improvements, and considered the clinical application possibilities of our study. All the codes are public available.
Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision
Dec 14, 2023



Widely used alignment techniques, such as reinforcement learning from human feedback (RLHF), rely on the ability of humans to supervise model behavior - for example, to evaluate whether a model faithfully followed instructions or generated safe outputs. However, future superhuman models will behave in complex ways too difficult for humans to reliably evaluate; humans will only be able to weakly supervise superhuman models. We study an analogy to this problem: can weak model supervision elicit the full capabilities of a much stronger model? We test this using a range of pretrained language models in the GPT-4 family on natural language processing (NLP), chess, and reward modeling tasks. We find that when we naively finetune strong pretrained models on labels generated by a weak model, they consistently perform better than their weak supervisors, a phenomenon we call weak-to-strong generalization. However, we are still far from recovering the full capabilities of strong models with naive finetuning alone, suggesting that techniques like RLHF may scale poorly to superhuman models without further work. We find that simple methods can often significantly improve weak-to-strong generalization: for example, when finetuning GPT-4 with a GPT-2-level supervisor and an auxiliary confidence loss, we can recover close to GPT-3.5-level performance on NLP tasks. Our results suggest that it is feasible to make empirical progress today on a fundamental challenge of aligning superhuman models.
Zero-shot causal learning
Jan 28, 2023Predicting how different interventions will causally affect a specific individual is important in a variety of domains such as personalized medicine, public policy, and online marketing. However, most existing causal methods cannot generalize to predicting the effects of previously unseen interventions (e.g., a newly invented drug), because they require data for individuals who received the intervention. Here, we consider zero-shot causal learning: predicting the personalized effects of novel, previously unseen interventions. To tackle this problem, we propose CaML, a causal meta-learning framework which formulates the personalized prediction of each intervention's effect as a task. Rather than training a separate model for each intervention, CaML trains as a single meta-model across thousands of tasks, each constructed by sampling an intervention and individuals who either did or did not receive it. By leveraging both intervention information (e.g., a drug's attributes) and individual features (e.g., a patient's history), CaML is able to predict the personalized effects of unseen interventions. Experimental results on real world datasets in large-scale medical claims and cell-line perturbations demonstrate the effectiveness of our approach. Most strikingly, CaML zero-shot predictions outperform even strong baselines which have direct access to data of considered target interventions.
Stylized Knowledge-Grounded Dialogue Generation via Disentangled Template Rewriting
Apr 12, 2022
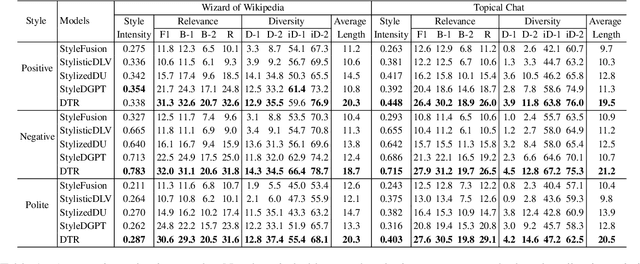
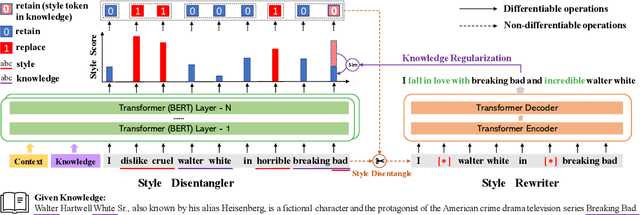
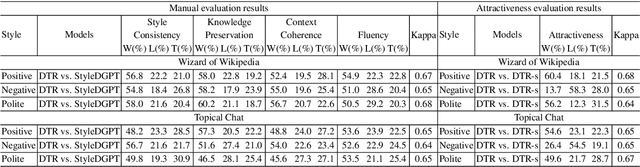
Current Knowledge-Grounded Dialogue Generation (KDG) models specialize in producing rational and factual responses. However, to establish long-term relationships with users, the KDG model needs the capability to generate responses in a desired style or attribute. Thus, we study a new problem: Stylized Knowledge-Grounded Dialogue Generation (SKDG). It presents two challenges: (1) How to train a SKDG model where no <context, knowledge, stylized response> triples are available. (2) How to cohere with context and preserve the knowledge when generating a stylized response. In this paper, we propose a novel disentangled template rewriting (DTR) method which generates responses via combing disentangled style templates (from monolingual stylized corpus) and content templates (from KDG corpus). The entire framework is end-to-end differentiable and learned without supervision. Extensive experiments on two benchmarks indicate that DTR achieves a significant improvement on all evaluation metrics compared with previous state-of-the-art stylized dialogue generation methods. Besides, DTR achieves comparable performance with the state-of-the-art KDG methods in standard KDG evaluation setting.