 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Emulator Design and Training for Modal Aerosol Microphysics Parameterizations in E3SMv2
Apr 23, 2026Toward the goal of using Scientific Machine Learning (SciML) emulators to improve the numerical representation of aerosol processes in global atmospheric models, we explore the emulation of aerosol microphysics processes under cloud-free conditions in the 4-mode Modal Aerosol Module (MAM4) within the Energy Exascale Earth System Model version 2 (E3SMv2). To develop an in-depth understanding of the challenges and opportunities in applying SciML to aerosol processes, we begin with a simple feedforward neural network architecture that has been used in earlier studies, but we systematically examine key emulator design choices, including architecture complexity and variable normalization, while closely monitoring training convergence behavior. Our results show that optimization convergence, scaling strategy, and network complexity strongly influence emulation accuracy. When effective scaling is applied and convergence is achieved, the relatively simple architecture, used together with a moderate network size, can reproduce key features of the microphysics-induced aerosol concentration changes with promising accuracy. These findings provide practical clues for the next stages of emulator development; they also provide general insights that are likely applicable to the emulation of other aerosol processes, as well as other atmospheric physics involving multi-scale variability.
DCAU-Net: Differential Cross Attention and Channel-Spatial Feature Fusion for Medical Image Segmentation
Mar 10, 2026Accurate medical image segmentation requires effective modeling of both long-range dependencies and fine-grained boundary details. While transformers mitigate the issue of insufficient semantic information arising from the limited receptive field inherent in convolutional neural networks, they introduce new challenges: standard self-attention incurs quadratic computational complexity and often assigns non-negligible attention weights to irrelevant regions, diluting focus on discriminative structures and ultimately compromising segmentation accuracy. Existing attention variants, although effective in reducing computational complexity, fail to suppress redundant computation and inadvertently impair global context modeling. Furthermore, conventional fusion strategies in encoder-decoder architectures, typically based on simple concatenation or summation, can not adaptively integrate high-level semantic information with low-level spatial details. To address these limitations, we propose DCAU-Net, a novel yet efficient segmentation framework with two key ideas. First, a new Differential Cross Attention (DCA) is designed to compute the difference between two independent softmax attention maps to adaptively highlight discriminative structures. By replacing pixel-wise key and value tokens with window-level summary tokens, DCA dramatically reduces computational complexity without sacrificing precision. Second, a Channel-Spatial Feature Fusion (CSFF) strategy is introduced to adaptively recalibrate features from skip connections and up-sampling paths through using sequential channel and spatial attention, effectively suppressing redundant information and amplifying salient cues. Experiments on two public benchmarks demonstrate that DCAU-Net achieves competitive performance with enhanced segmentation accuracy and robustness.
TAP-SLF: Parameter-Efficient Adaptation of Vision Foundation Models for Multi-Task Ultrasound Image Analysis
Feb 28, 2026Executing multiple tasks simultaneously in medical image analysis, including segmentation, classification, detection, and regression, often introduces significant challenges regarding model generalizability and the optimization of shared feature representations. While Vision Foundation Models (VFMs) provide powerful general representations, full fine-tuning on limited medical data is prone to overfitting and incurs high computational costs. Moreover, existing parameter-efficient fine-tuning approaches typically adopt task-agnostic adaptation protocols, overlooking both task-specific mechanisms and the varying sensitivity of model layers during fine-tuning. In this work, we propose Task-Aware Prompting and Selective Layer Fine-Tuning (TAP-SLF), a unified framework for multi-task ultrasound image analysis. TAP-SLF incorporates task-aware soft prompts to encode task-specific priors into the input token sequence and applies LoRA to selected specific top layers of the encoder. This strategy updates only a small fraction of the VFM parameters while keeping the pre-trained backbone frozen. By combining task-aware prompts with selective high-layer fine-tuning, TAP-SLF enables efficient VFM adaptation to diverse medical tasks within a shared backbone. Results on the FMC_UIA 2026 Challenge test set, where TAP-SLF wins fifth place, combined with evaluations on the officially released training dataset using an 8:2 train-test split, demonstrate that task-aware prompting and selective layer tuning are effective strategies for efficient VFM adaptation.
Stabilizing PDE--ML Coupled System
Jun 24, 2025A long-standing obstacle in the use of machine-learnt surrogates with larger PDE systems is the onset of instabilities when solved numerically. Efforts towards ameliorating these have mostly concentrated on improving the accuracy of the surrogates or imbuing them with additional structure, and have garnered limited success. In this article, we study a prototype problem and draw insights that can help with more complex systems. In particular, we focus on a viscous Burgers'-ML system and, after identifying the cause of the instabilities, prescribe strategies to stabilize the coupled system. To improve the accuracy of the stabilized system, we next explore methods based on the Mori--Zwanzig formalism.
Evaluating Robustness of Dialogue Summarization Models in the Presence of Naturally Occurring Variations
Nov 15, 2023



Dialogue summarization task involves summarizing long conversations while preserving the most salient information. Real-life dialogues often involve naturally occurring variations (e.g., repetitions, hesitations) and existing dialogue summarization models suffer from performance drop on such conversations. In this study, we systematically investigate the impact of such variations on state-of-the-art dialogue summarization models using publicly available datasets. To simulate real-life variations, we introduce two types of perturbations: utterance-level perturbations that modify individual utterances with errors and language variations, and dialogue-level perturbations that add non-informative exchanges (e.g., repetitions, greetings). We conduct our analysis along three dimensions of robustness: consistency, saliency, and faithfulness, which capture different aspects of the summarization model's performance. We find that both fine-tuned and instruction-tuned models are affected by input variations, with the latter being more susceptible, particularly to dialogue-level perturbations. We also validate our findings via human evaluation. Finally, we investigate if the robustness of fine-tuned models can be improved by training them with a fraction of perturbed data and observe that this approach is insufficient to address robustness challenges with current models and thus warrants a more thorough investigation to identify better solutions. Overall, our work highlights robustness challenges in dialogue summarization and provides insights for future research.
How Can Context Help? Exploring Joint Retrieval of Passage and Personalized Context
Aug 26, 2023



The integration of external personalized context information into document-grounded conversational systems has significant potential business value, but has not been well-studied. Motivated by the concept of personalized context-aware document-grounded conversational systems, we introduce the task of context-aware passage retrieval. We also construct a dataset specifically curated for this purpose. We describe multiple baseline systems to address this task, and propose a novel approach, Personalized Context-Aware Search (PCAS), that effectively harnesses contextual information during passage retrieval. Experimental evaluations conducted on multiple popular dense retrieval systems demonstrate that our proposed approach not only outperforms the baselines in retrieving the most relevant passage but also excels at identifying the pertinent context among all the available contexts. We envision that our contributions will serve as a catalyst for inspiring future research endeavors in this promising direction.
Semi-Structured Object Sequence Encoders
Jan 10, 2023



In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.
Fast and Light-Weight Answer Text Retrieval in Dialogue Systems
May 31, 2022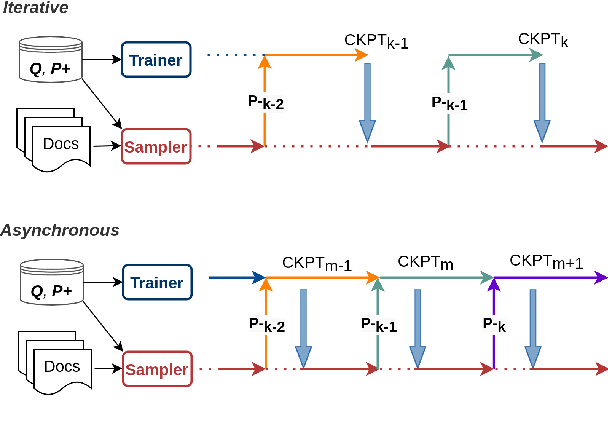
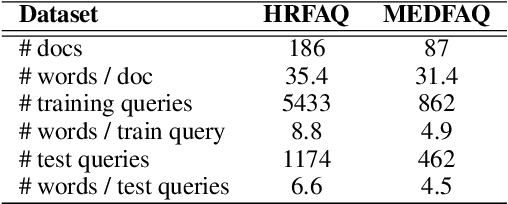
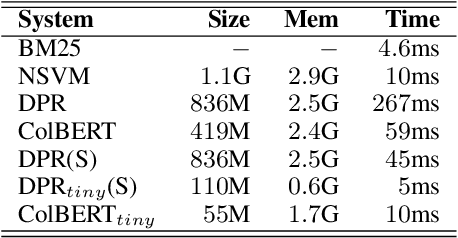
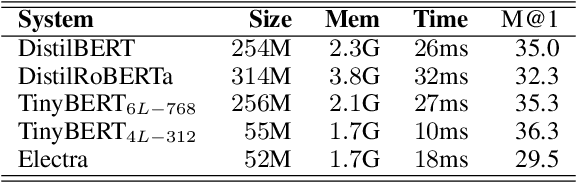
Dialogue systems can benefit from being able to search through a corpus of text to find information relevant to user requests, especially when encountering a request for which no manually curated response is available. The state-of-the-art technology for neural dense retrieval or re-ranking involves deep learning models with hundreds of millions of parameters. However, it is difficult and expensive to get such models to operate at an industrial scale, especially for cloud services that often need to support a big number of individually customized dialogue systems, each with its own text corpus. We report our work on enabling advanced neural dense retrieval systems to operate effectively at scale on relatively inexpensive hardware. We compare with leading alternative industrial solutions and show that we can provide a solution that is effective, fast, and cost-efficient.
Learning as Conversation: Dialogue Systems Reinforced for Information Acquisition
May 29, 2022



We propose novel AI-empowered chat bots for learning as conversation where a user does not read a passage but gains information and knowledge through conversation with a teacher bot. Our information-acquisition-oriented dialogue system employs a novel adaptation of reinforced self-play so that the system can be transferred to various domains without in-domain dialogue data, and can carry out conversations both informative and attentive to users. Our extensive subjective and objective evaluations on three large public data corpora demonstrate the effectiveness of our system to deliver knowledge-intensive and attentive conversations and help end users substantially gain knowledge without reading passages. Our code and datasets are publicly available for follow-up research.
MultiDoc2Dial: Modeling Dialogues Grounded in Multiple Documents
Sep 26, 2021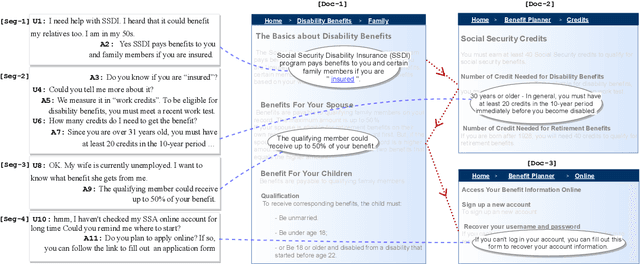
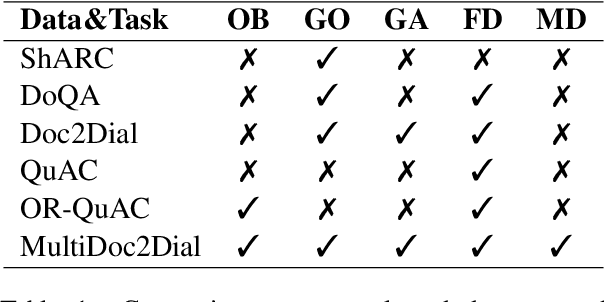
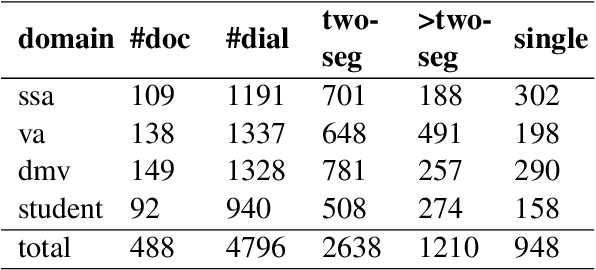
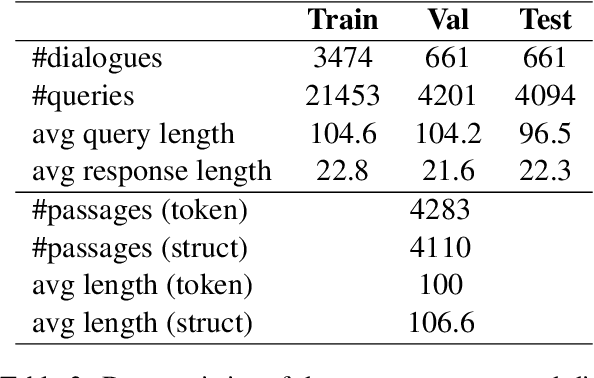
We propose MultiDoc2Dial, a new task and dataset on modeling goal-oriented dialogues grounded in multiple documents. Most previous works treat document-grounded dialogue modeling as a machine reading comprehension task based on a single given document or passage. In this work, we aim to address more realistic scenarios where a goal-oriented information-seeking conversation involves multiple topics, and hence is grounded on different documents. To facilitate such a task, we introduce a new dataset that contains dialogues grounded in multiple documents from four different domains. We also explore modeling the dialogue-based and document-based context in the dataset. We present strong baseline approaches and various experimental results, aiming to support further research efforts on such a task.