 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021
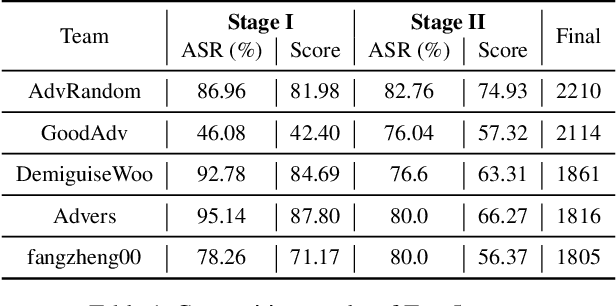
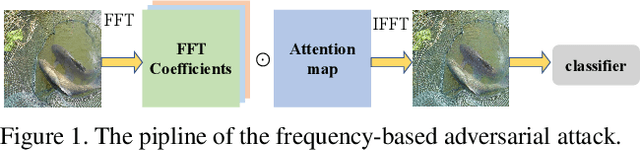
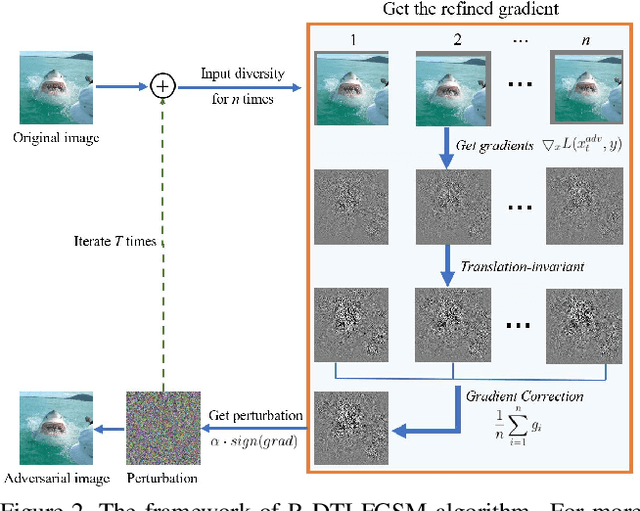
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
UAV-based Crowd Surveillance in Post COVID-19 Era
Nov 28, 2021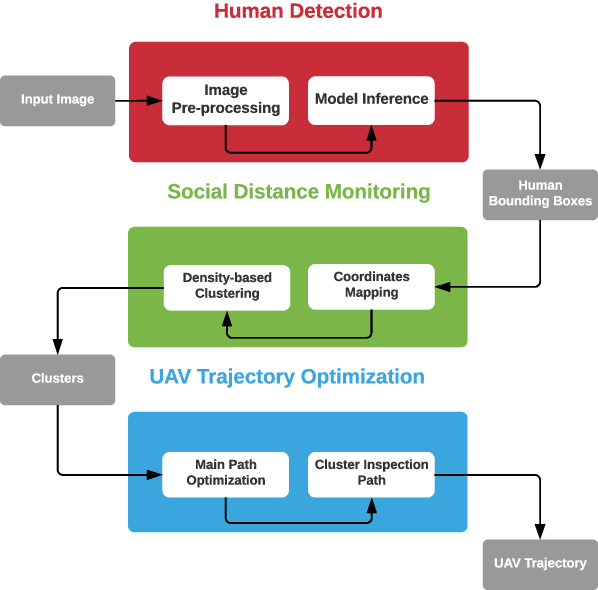
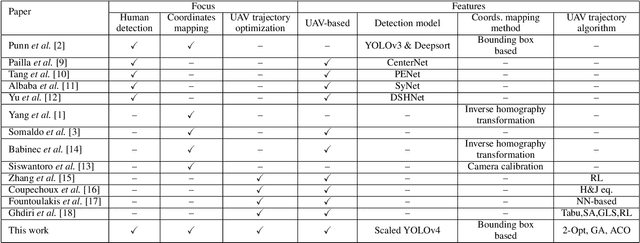


To cope with the current pandemic situation and reinstate pseudo-normal daily life, several measures have been deployed and maintained, such as mask wearing, social distancing, hands sanitizing, etc. Since outdoor cultural events, concerts, and picnics, are gradually allowed, a close monitoring of the crowd activity is needed to avoid undesired contact and disease transmission. In this context, intelligent unmanned aerial vehicles (UAVs) can be occasionally deployed to ensure the surveillance of these activities, that health restriction measures are applied, and to trigger alerts when the latter are not respected. Consequently, we propose in this paper a complete UAV framework for intelligent monitoring of post COVID-19 outdoor activities. Specifically, we propose a three steps approach. In the first step, captured images by a UAV are analyzed using machine learning to detect and locate individuals. The second step consists of a novel coordinates mapping approach to evaluate distances among individuals, then cluster them, while the third step provides an energy-efficient and/or reliable UAV trajectory to inspect clusters for restrictions violation such as mask wearing. Obtained results provide the following insights: 1) Efficient detection of individuals depends on the angle from which the image was captured, 2) coordinates mapping is very sensitive to the estimation error in individuals' bounding boxes, and 3) UAV trajectory design algorithm 2-Opt is recommended for practical real-time deployments due to its low-complexity and near-optimal performance.
Image Deconvolution via Noise-Tolerant Self-Supervised Inversion
Jun 11, 2020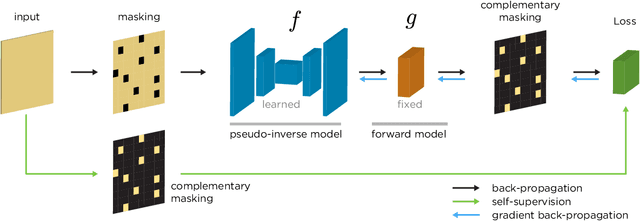
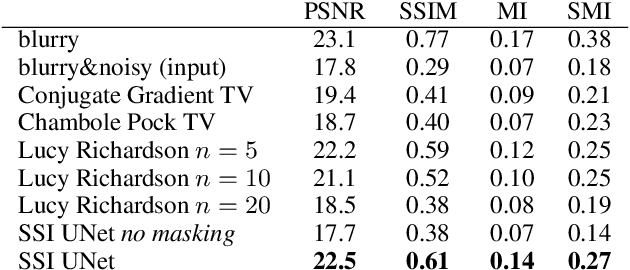
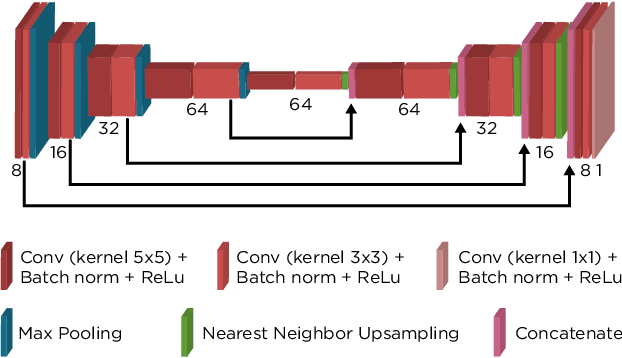
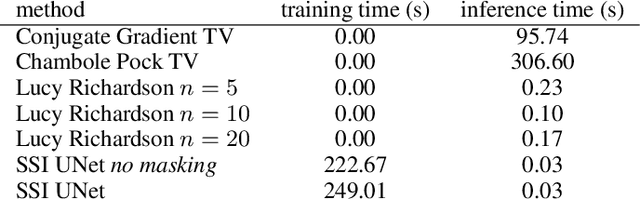
We propose a general framework for solving inverse problems in the presence of noise that requires no signal prior, no noise estimate, and no clean training data. We only require that the forward model be available and that the noise be statistically independent across measurement dimensions. We build upon the theory of $\mathcal{J}$-invariant functions (Batson & Royer 2019, arXiv:1901.11365) and show how self-supervised denoising \emph{\`a la} Noise2Self is a special case of learning a noise-tolerant pseudo-inverse of the identity. We demonstrate our approach by showing how a convolutional neural network can be taught in a self-supervised manner to deconvolve images and surpass in image quality classical inversion schemes such as Lucy-Richardson deconvolution.
Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Aug 19, 2021
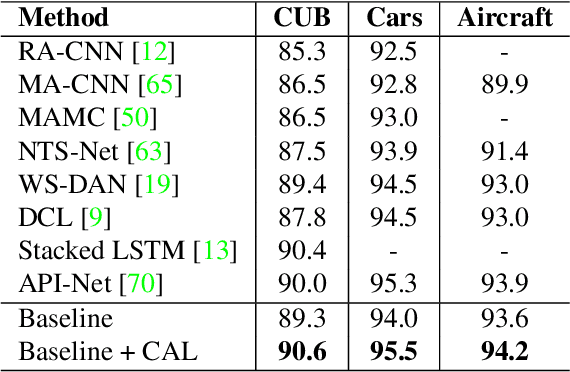
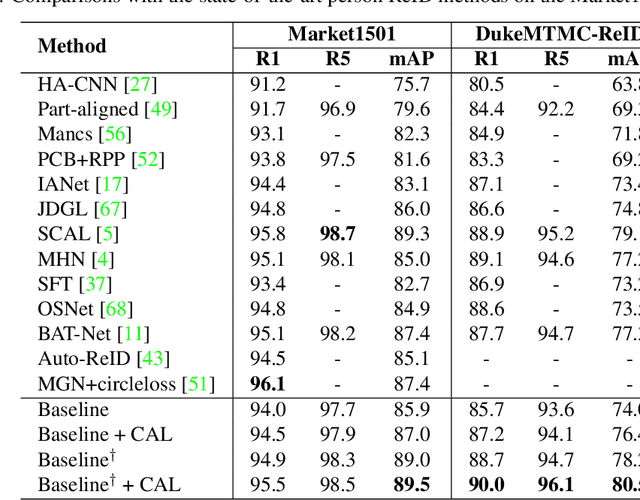
Attention mechanism has demonstrated great potential in fine-grained visual recognition tasks. In this paper, we present a counterfactual attention learning method to learn more effective attention based on causal inference. Unlike most existing methods that learn visual attention based on conventional likelihood, we propose to learn the attention with counterfactual causality, which provides a tool to measure the attention quality and a powerful supervisory signal to guide the learning process. Specifically, we analyze the effect of the learned visual attention on network prediction through counterfactual intervention and maximize the effect to encourage the network to learn more useful attention for fine-grained image recognition. Empirically, we evaluate our method on a wide range of fine-grained recognition tasks where attention plays a crucial role, including fine-grained image categorization, person re-identification, and vehicle re-identification. The consistent improvement on all benchmarks demonstrates the effectiveness of our method. Code is available at https://github.com/raoyongming/CAL
A deep learned nanowire segmentation model using synthetic data augmentation
Sep 09, 2021
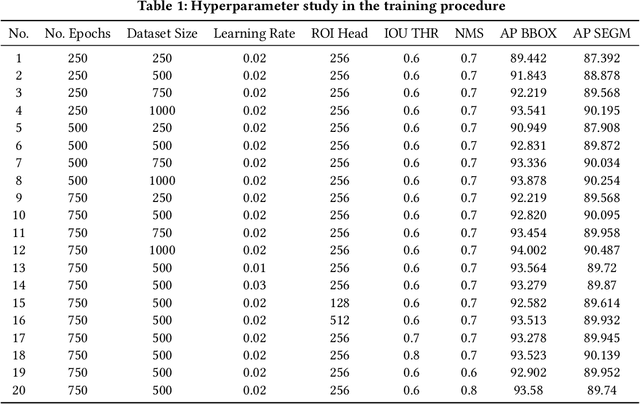
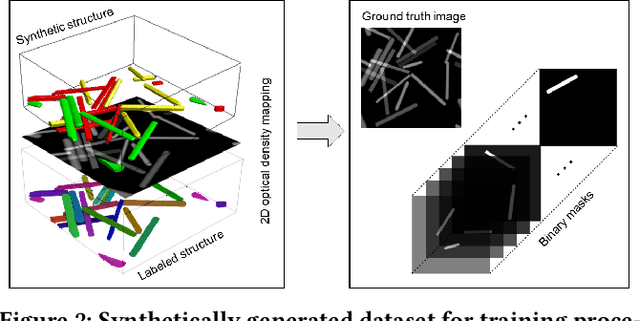
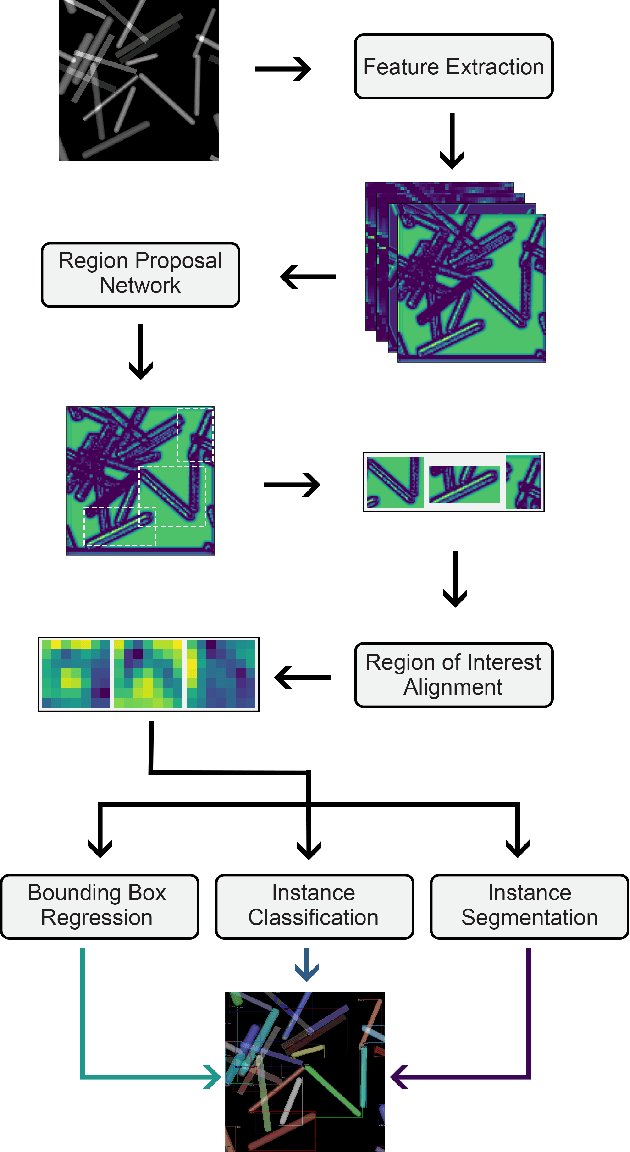
Automatized object identification and feature analysis of experimental image data are indispensable for data-driven material science; deep-learning-based segmentation algorithms have been shown to be a promising technique to achieve this goal. However, acquiring high-resolution experimental images and assigning labels in order to train such algorithms is challenging and costly in terms of both time and labor. In the present work, we apply synthetic images, which resemble the experimental image data in terms of geometrical and visual features, to train state-of-art deep learning-based Mask R-CNN algorithms to segment vanadium pentoxide (V2O5) nanowires, a canonical cathode material, within optical intensity-based images from spectromicroscopy. The performance evaluation demonstrates that even though the deep learning model is trained on pure synthetically generated structures, it can segment real optical intensity-based spectromicroscopy images of complex V2O5 nanowire structures in overlapped particle networks, thus providing reliable statistical information. The model can further be used to segment nanowires in scanning electron microscopy (SEM) images, which are fundamentally different from the training dataset known to the model. The proposed methodology of using a purely synthetic dataset to train the deep learning model can be extended to any optical intensity-based images of variable particle morphology, extent of agglomeration, material class, and beyond.
OpenHI2 -- Open source histopathological image platform
Jan 15, 2020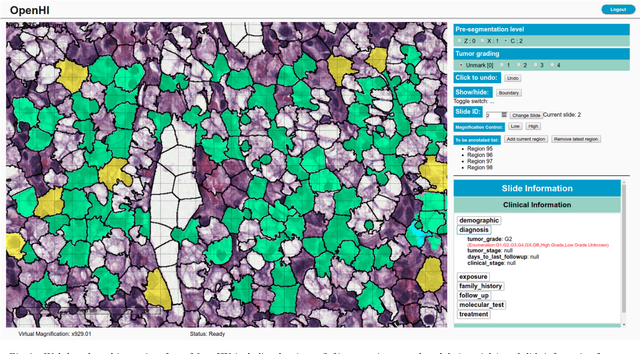
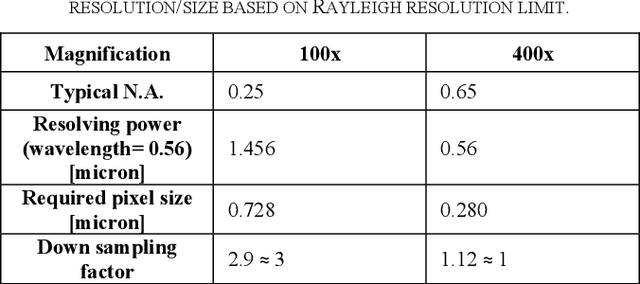
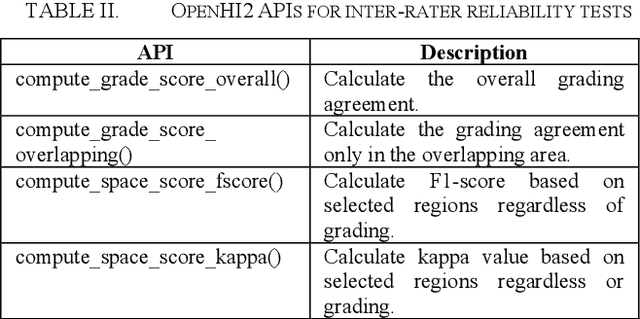
Transition from conventional to digital pathology requires a new category of biomedical informatic infrastructure which could facilitate delicate pathological routine. Pathological diagnoses are sensitive to many external factors and is known to be subjective. Only systems that can meet strict requirements in pathology would be able to run along pathological routines and eventually digitized the study area, and the developed platform should comply with existing pathological routines and international standards. Currently, there are a number of available software tools which can perform histopathological tasks including virtual slide viewing, annotating, and basic image analysis, however, none of them can serve as a digital platform for pathology. Here we describe OpenHI2, an enhanced version Open Histopathological Image platform which is capable of supporting all basic pathological tasks and file formats; ready to be deployed in medical institutions on a standard server environment or cloud computing infrastructure. In this paper, we also describe the development decisions for the platform and propose solutions to overcome technical challenges so that OpenHI2 could be used as a platform for histopathological images. Further addition can be made to the platform since each component is modularized and fully documented. OpenHI2 is free, open-source, and available at https://gitlab.com/BioAI/OpenHI.
Batch Curation for Unsupervised Contrastive Representation Learning
Aug 19, 2021
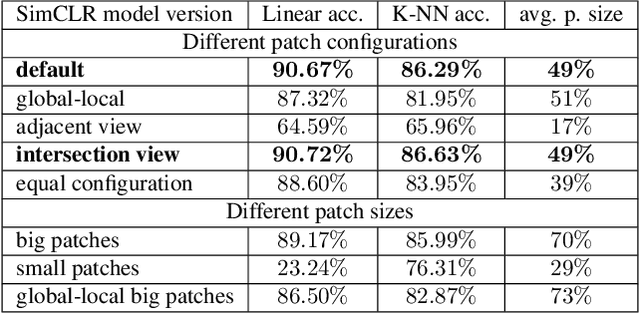
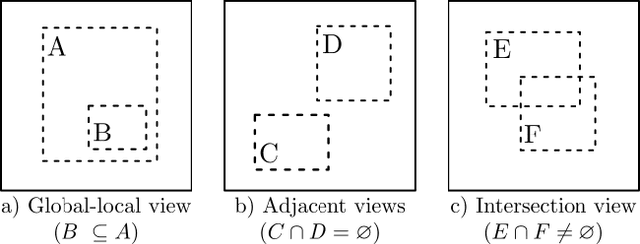

The state-of-the-art unsupervised contrastive visual representation learning methods that have emerged recently (SimCLR, MoCo, SwAV) all make use of data augmentations in order to construct a pretext task of instant discrimination consisting of similar and dissimilar pairs of images. Similar pairs are constructed by randomly extracting patches from the same image and applying several other transformations such as color jittering or blurring, while transformed patches from different image instances in a given batch are regarded as dissimilar pairs. We argue that this approach can result similar pairs that are \textit{semantically} dissimilar. In this work, we address this problem by introducing a \textit{batch curation} scheme that selects batches during the training process that are more inline with the underlying contrastive objective. We provide insights into what constitutes beneficial similar and dissimilar pairs as well as validate \textit{batch curation} on CIFAR10 by integrating it in the SimCLR model.
Separate from Observation: Unsupervised Single Image Layer Separation
Jun 03, 2019
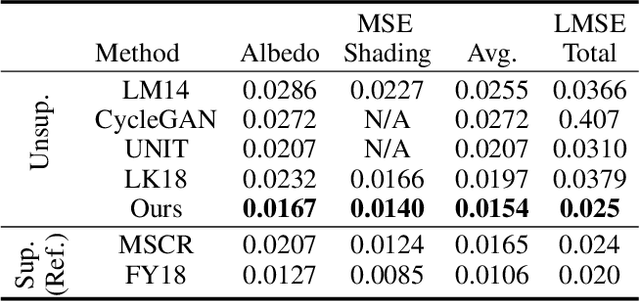
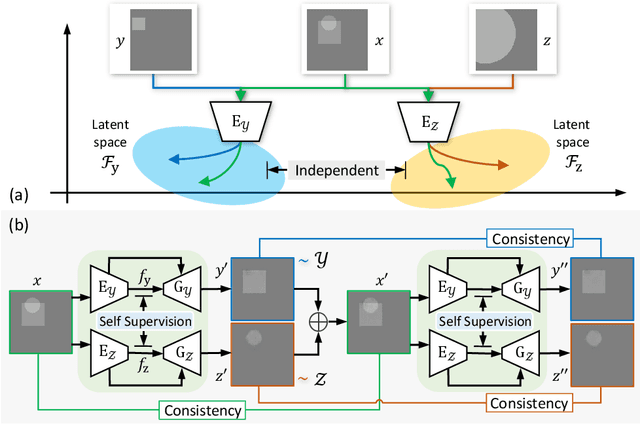
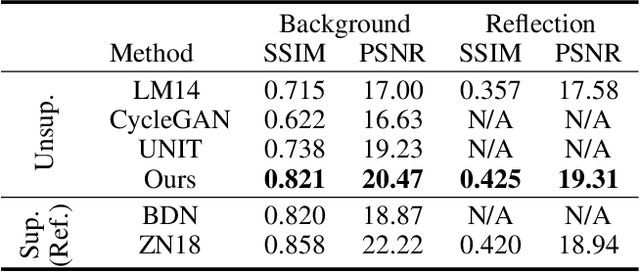
Unsupervised single image layer separation aims at extracting two layers from an input image where these layers follow different distributions. This problem arises most notably in reflection inference removal and intrinsic image decomposition. Since there exist an infinite set of combinations that can construct the given input image, one could infer nothing about the solutions without additional assumptions. To address the problem, we make the shared information consistency assumption and separated layer independence assumption to constrain the solutions. In this end, we propose an unsupervised single image separation framework based on cycle GANs and self-supervised learning. The proposed framework is applied for the reflection removal and intrinsic image problems. Numerical and visual results show that the proposed method achieves the state-of-the-art performance among unsupervised methods which require single image as input. Based on the slightly modified version of the presented framework, we also demonstrate the promising results of decomposing an image into three layer.
Brain Programming is Immune to Adversarial Attacks: Towards Accurate and Robust Image Classification using Symbolic Learning
Mar 01, 2021



In recent years, the security concerns about the vulnerability of Deep Convolutional Neural Networks (DCNN) to Adversarial Attacks (AA) in the form of small modifications to the input image almost invisible to human vision make their predictions untrustworthy. Therefore, it is necessary to provide robustness to adversarial examples in addition to an accurate score when developing a new classifier. In this work, we perform a comparative study of the effects of AA on the complex problem of art media categorization, which involves a sophisticated analysis of features to classify a fine collection of artworks. We tested a prevailing bag of visual words approach from computer vision, four state-of-the-art DCNN models (AlexNet, VGG, ResNet, ResNet101), and the Brain Programming (BP) algorithm. In this study, we analyze the algorithms' performance using accuracy. Besides, we use the accuracy ratio between adversarial examples and clean images to measure robustness. Moreover, we propose a statistical analysis of each classifier's predictions' confidence to corroborate the results. We confirm that BP predictions' change was below 2\% using adversarial examples computed with the fast gradient sign method. Also, considering the multiple pixel attack, BP obtained four out of seven classes without changes and the rest with a maximum error of 4\% in the predictions. Finally, BP also gets four categories using adversarial patches without changes and for the remaining three classes with a variation of 1\%. Additionally, the statistical analysis showed that the predictions' confidence of BP were not significantly different for each pair of clean and perturbed images in every experiment. These results prove BP's robustness against adversarial examples compared to DCNN and handcrafted features methods, whose performance on the art media classification was compromised with the proposed perturbations.
Clean Images are Hard to Reblur: A New Clue for Deblurring
Apr 26, 2021
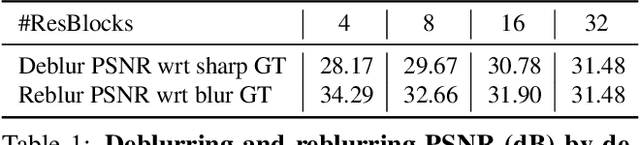

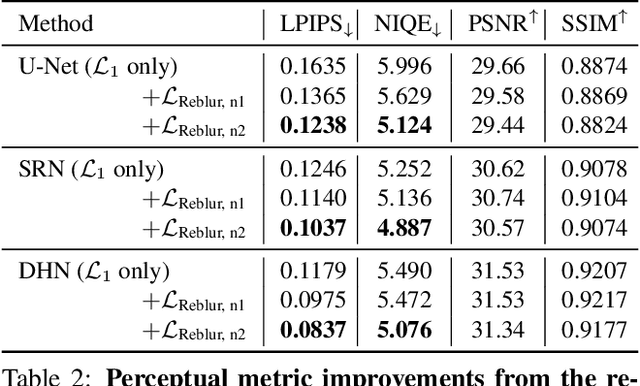
The goal of dynamic scene deblurring is to remove the motion blur present in a given image. Most learning-based approaches implement their solutions by minimizing the L1 or L2 distance between the output and reference sharp image. Recent attempts improve the perceptual quality of the deblurred image by using features learned from visual recognition tasks. However, those features are originally designed to capture the high-level contexts rather than the low-level structures of the given image, such as blurriness. We propose a novel low-level perceptual loss to make image sharper. To better focus on image blurriness, we train a reblurring module amplifying the unremoved motion blur. Motivated that a well-deblurred clean image should contain zero-magnitude motion blur that is hard to be amplified, we design two types of reblurring loss functions. The supervised reblurring loss at training stage compares the amplified blur between the deblurred image and the reference sharp image. The self-supervised reblurring loss at inference stage inspects if the deblurred image still contains noticeable blur to be amplified. Our experimental results demonstrate the proposed reblurring losses improve the perceptual quality of the deblurred images in terms of NIQE and LPIPS scores as well as visual sharpness.