 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CLIP2Scene: Towards Label-efficient 3D Scene Understanding by CLIP
Jan 12, 2023
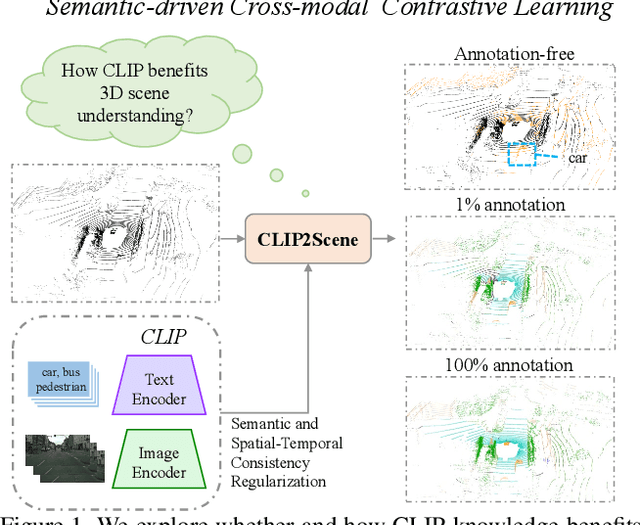
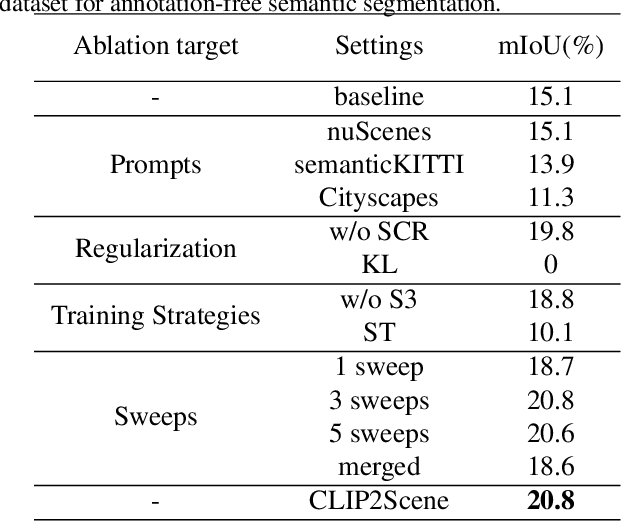
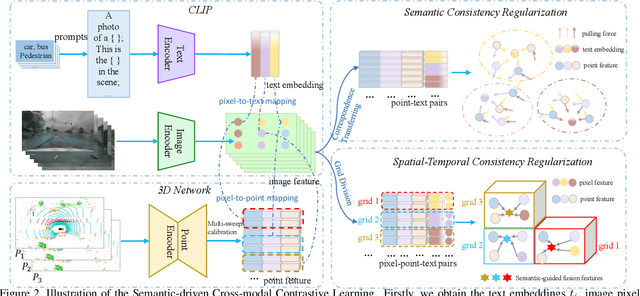
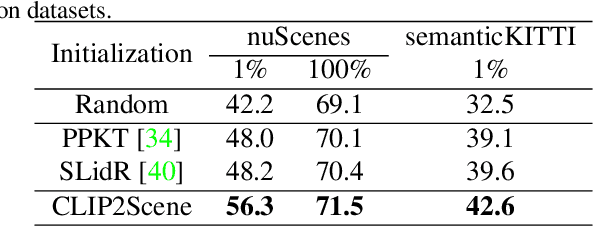
Contrastive language-image pre-training (CLIP) achieves promising results in 2D zero-shot and few-shot learning. Despite the impressive performance in 2D tasks, applying CLIP to help the learning in 3D scene understanding has yet to be explored. In this paper, we make the first attempt to investigate how CLIP knowledge benefits 3D scene understanding. To this end, we propose CLIP2Scene, a simple yet effective framework that transfers CLIP knowledge from 2D image-text pre-trained models to a 3D point cloud network. We show that the pre-trained 3D network yields impressive performance on various downstream tasks, i.e., annotation-free and fine-tuning with labelled data for semantic segmentation. Specifically, built upon CLIP, we design a Semantic-driven Cross-modal Contrastive Learning framework that pre-trains a 3D network via semantic and spatial-temporal consistency regularization. For semantic consistency regularization, we first leverage CLIP's text semantics to select the positive and negative point samples and then employ the contrastive loss to train the 3D network. In terms of spatial-temporal consistency regularization, we force the consistency between the temporally coherent point cloud features and their corresponding image features. We conduct experiments on the nuScenes and SemanticKITTI datasets. For the first time, our pre-trained network achieves annotation-free 3D semantic segmentation with 20.8\% mIoU. When fine-tuned with 1\% or 100\% labelled data, our method significantly outperforms other self-supervised methods, with improvements of 8\% and 1\% mIoU, respectively. Furthermore, we demonstrate its generalization capability for handling cross-domain datasets.
SufrinNet: Toward Sufficient Cross-View Interaction for Stereo Image Enhancement in The Dark
Nov 04, 2022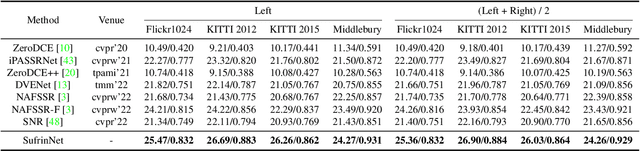
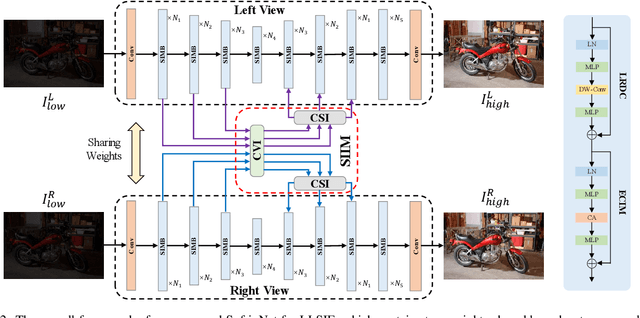
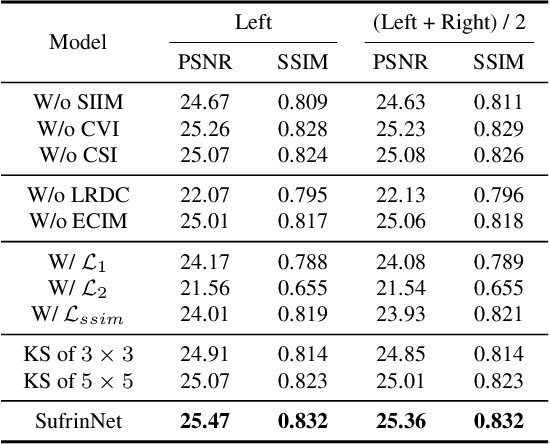
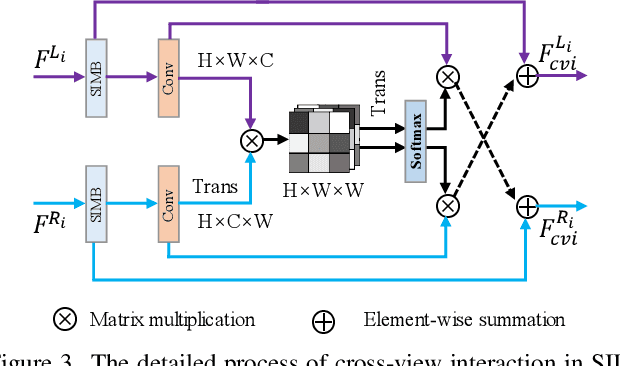
Low-light stereo image enhancement (LLSIE) is a relatively new task to enhance the quality of visually unpleasant stereo images captured in dark conditions. So far, very few studies on deep LLSIE have been explored due to certain challenging issues, i.e., the task has not been well addressed, and current methods clearly suffer from two shortages: 1) insufficient cross-view interaction; 2) lacking long-range dependency for intra-view learning. In this paper, we therefore propose a novel LLSIE model, termed \underline{Suf}ficient C\underline{r}oss-View \underline{In}teraction Network (SufrinNet). To be specific, we present sufficient inter-view interaction module (SIIM) to enhance the information exchange across views. SIIM not only discovers the cross-view correlations at different scales, but also explores the cross-scale information interaction. Besides, we present a spatial-channel information mining block (SIMB) for intra-view feature extraction, and the benefits are twofold. One is the long-range dependency capture to build spatial long-range relationship, and the other is expanded channel information refinement that enhances information flow in channel dimension. Extensive experiments on Flickr1024, KITTI 2012, KITTI 2015 and Middlebury datasets show that our method obtains better illumination adjustment and detail recovery, and achieves SOTA performance compared to other related methods. Our codes, datasets and models will be publicly available.
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
Feb 18, 2023
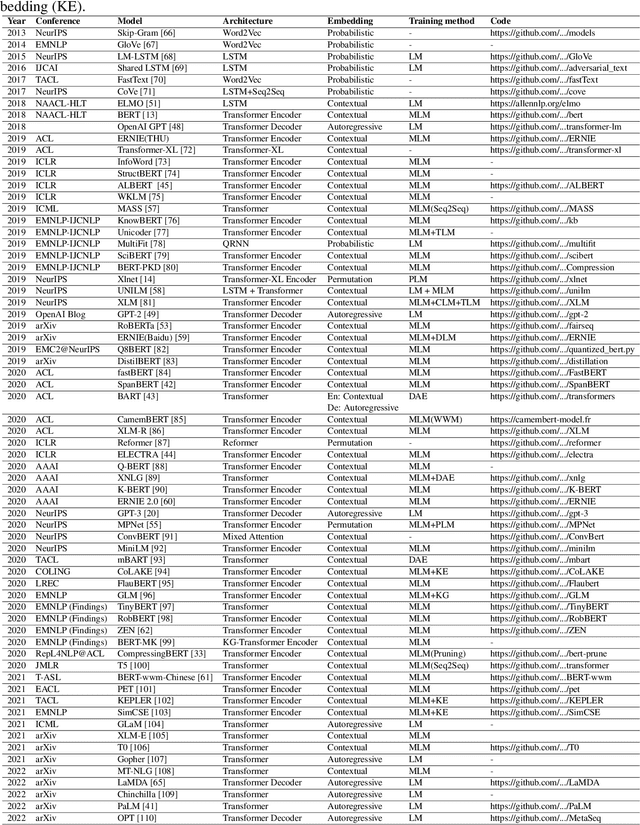
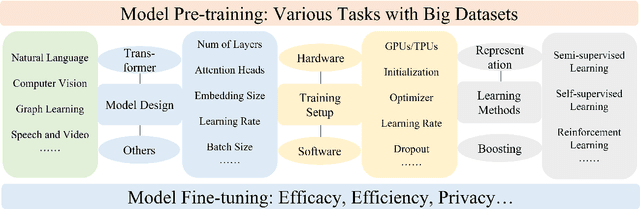
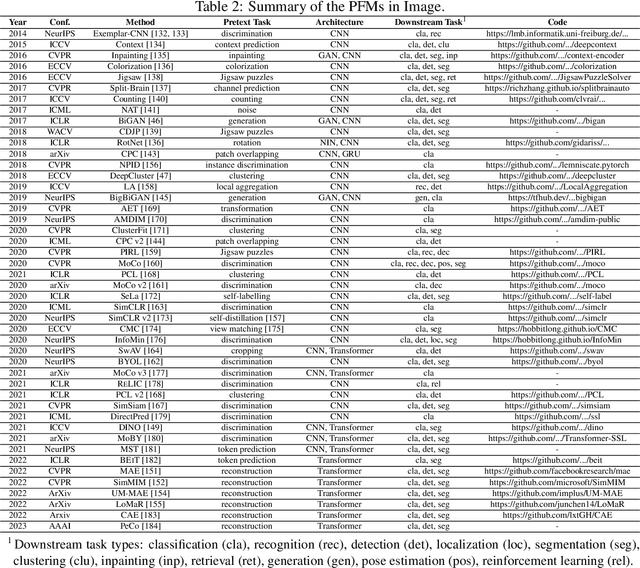
The Pretrained Foundation Models (PFMs) are regarded as the foundation for various downstream tasks with different data modalities. A pretrained foundation model, such as BERT, GPT-3, MAE, DALLE-E, and ChatGPT, is trained on large-scale data which provides a reasonable parameter initialization for a wide range of downstream applications. The idea of pretraining behind PFMs plays an important role in the application of large models. Different from previous methods that apply convolution and recurrent modules for feature extractions, the generative pre-training (GPT) method applies Transformer as the feature extractor and is trained on large datasets with an autoregressive paradigm. Similarly, the BERT apples transformers to train on large datasets as a contextual language model. Recently, the ChatGPT shows promising success on large language models, which applies an autoregressive language model with zero shot or few show prompting. With the extraordinary success of PFMs, AI has made waves in a variety of fields over the past few years. Considerable methods, datasets, and evaluation metrics have been proposed in the literature, the need is raising for an updated survey. This study provides a comprehensive review of recent research advancements, current and future challenges, and opportunities for PFMs in text, image, graph, as well as other data modalities. We first review the basic components and existing pretraining in natural language processing, computer vision, and graph learning. We then discuss other advanced PFMs for other data modalities and unified PFMs considering the data quality and quantity. Besides, we discuss relevant research about the fundamentals of the PFM, including model efficiency and compression, security, and privacy. Finally, we lay out key implications, future research directions, challenges, and open problems.
Multi-organ segmentation: a progressive exploration of learning paradigms under scarce annotation
Feb 07, 2023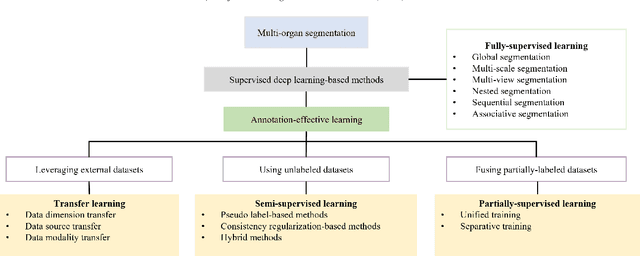
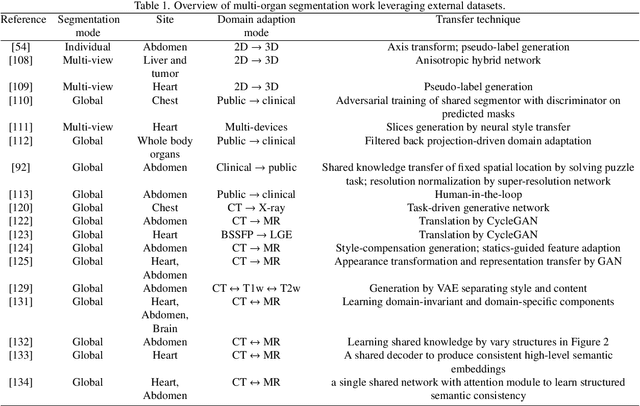
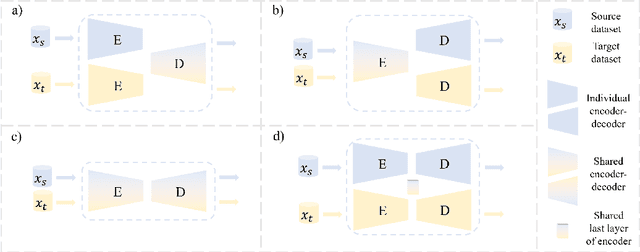

Precise delineation of multiple organs or abnormal regions in the human body from medical images plays an essential role in computer-aided diagnosis, surgical simulation, image-guided interventions, and especially in radiotherapy treatment planning. Thus, it is of great significance to explore automatic segmentation approaches, among which deep learning-based approaches have evolved rapidly and witnessed remarkable progress in multi-organ segmentation. However, obtaining an appropriately sized and fine-grained annotated dataset of multiple organs is extremely hard and expensive. Such scarce annotation limits the development of high-performance multi-organ segmentation models but promotes many annotation-efficient learning paradigms. Among these, studies on transfer learning leveraging external datasets, semi-supervised learning using unannotated datasets and partially-supervised learning integrating partially-labeled datasets have led the dominant way to break such dilemma in multi-organ segmentation. We first review the traditional fully supervised method, then present a comprehensive and systematic elaboration of the 3 abovementioned learning paradigms in the context of multi-organ segmentation from both technical and methodological perspectives, and finally summarize their challenges and future trends.
NeSe: Near-Sensor Event-Driven Scheme for Low Power Energy Harvesting Sensors
Feb 07, 2023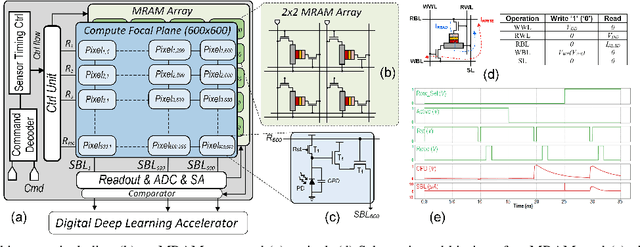
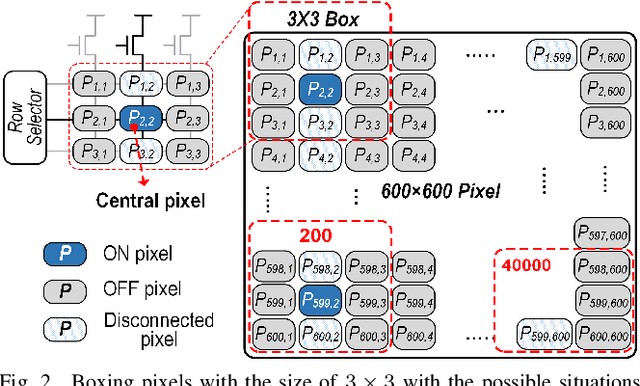


Digital technologies have made it possible to deploy visual sensor nodes capable of detecting motion events in the coverage area cost-effectively. However, background subtraction, as a widely used approach, remains an intractable task due to its inability to achieve competitive accuracy and reduced computation cost simultaneously. In this paper, an effective background subtraction approach, namely NeSe, for tiny energy-harvested sensors is proposed leveraging non-volatile memory (NVM). Using the developed software/hardware method, the accuracy and efficiency of event detection can be adjusted at runtime by changing the precision depending on the application's needs. Due to the near-sensor implementation of background subtraction and NVM usage, the proposed design reduces the data movement overhead while ensuring intermittent resiliency. The background is stored for a specific time interval within NVMs and compared with the next frame. If the power is cut, the background remains unchanged and is updated after the interval passes. Once the moving object is detected, the device switches to the high-powered sensor mode to capture the image.
RobustNeRF: Ignoring Distractors with Robust Losses
Feb 02, 2023
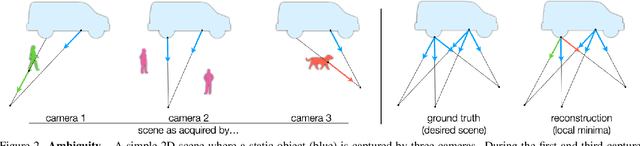
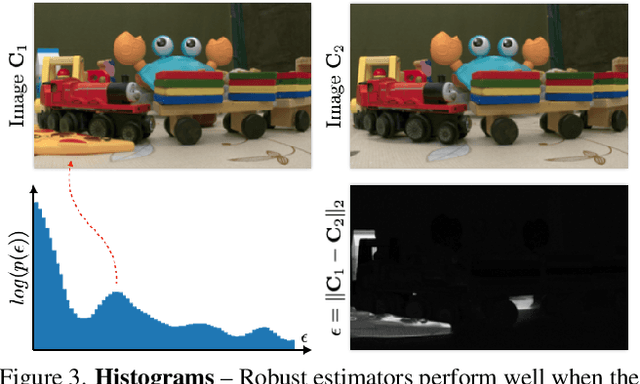
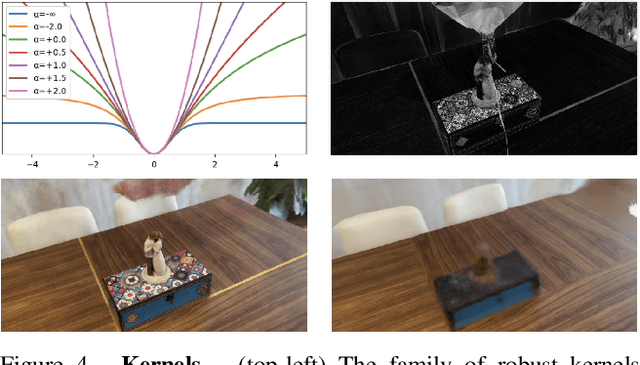
Neural radiance fields (NeRF) excel at synthesizing new views given multi-view, calibrated images of a static scene. When scenes include distractors, which are not persistent during image capture (moving objects, lighting variations, shadows), artifacts appear as view-dependent effects or 'floaters'. To cope with distractors, we advocate a form of robust estimation for NeRF training, modeling distractors in training data as outliers of an optimization problem. Our method successfully removes outliers from a scene and improves upon our baselines, on synthetic and real-world scenes. Our technique is simple to incorporate in modern NeRF frameworks, with few hyper-parameters. It does not assume a priori knowledge of the types of distractors, and is instead focused on the optimization problem rather than pre-processing or modeling transient objects. More results on our page https://robustnerf.github.io/public.
Isotopic envelope identification by analysis of the spatial distribution of components in MALDI-MSI data
Feb 13, 2023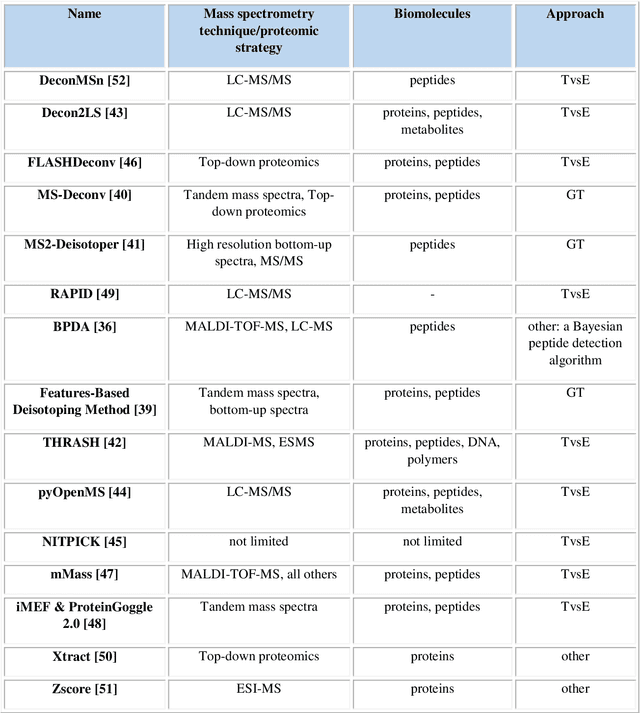
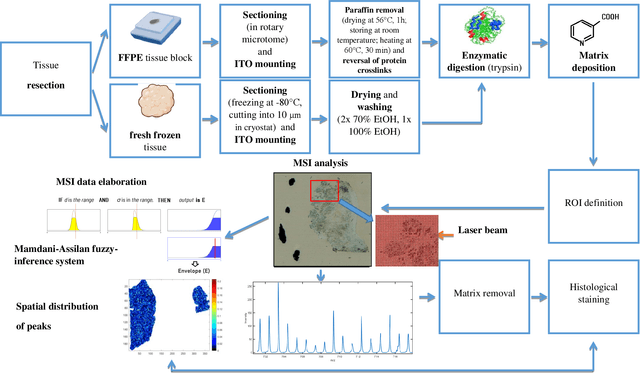
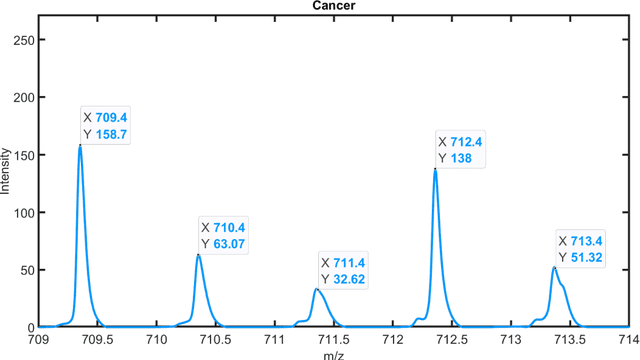
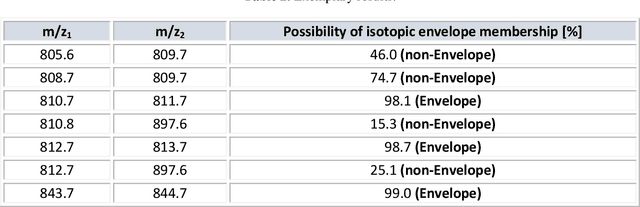
One of the significant steps in the process leading to the identification of proteins is mass spectrometry, which allows for obtaining information about the structure of proteins. Removing isotope peaks from the mass spectrum is vital and it is done in a process called deisotoping. There are different algorithms for deisotoping, but they have their limitations, they are dedicated to different methods of mass spectrometry. Data from experiments performed with the MALDI-ToF technique are characterized by high dimensionality. This paper presents a method for identifying isotope envelopes in MALDI-ToF molecular imaging data based on the Mamdani-Assilan fuzzy system and spatial maps of the molecular distribution of peaks included in the isotopic envelope. Several image texture measures were used to evaluate spatial molecular distribution maps. The algorithm was tested on eight datasets obtained from the MALDI-ToF experiment on samples from the National Institute of Oncology in Gliwice from patients with cancer of the head and neck region. The data were subjected to pre-processing and feature extraction. The results were collected and compared with three existing deisotoping algorithms. The analysis of the obtained results showed that the method for identifying isotopic envelopes proposed in this paper enables the detection of overlapping envelopes by using the approach oriented to study peak pairs. Moreover, the proposed algorithm enables the analysis of large data sets.
Self-Supervised Endoscopic Image Key-Points Matching
Aug 24, 2022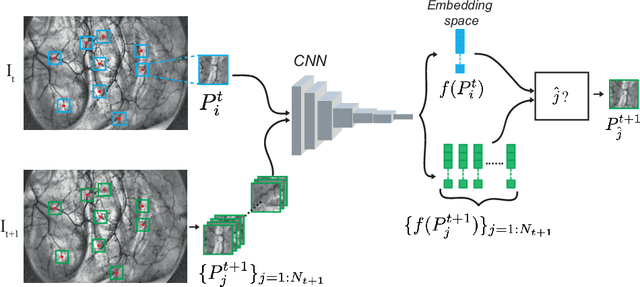
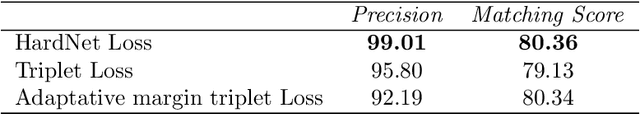
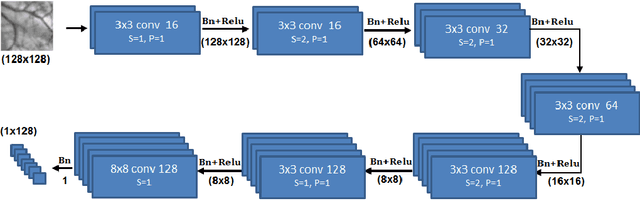
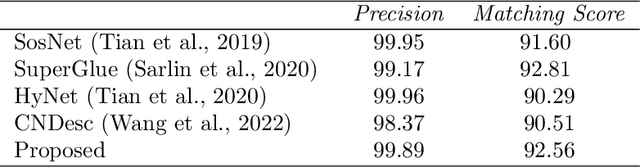
Feature matching and finding correspondences between endoscopic images is a key step in many clinical applications such as patient follow-up and generation of panoramic image from clinical sequences for fast anomalies localization. Nonetheless, due to the high texture variability present in endoscopic images, the development of robust and accurate feature matching becomes a challenging task. Recently, deep learning techniques which deliver learned features extracted via convolutional neural networks (CNNs) have gained traction in a wide range of computer vision tasks. However, they all follow a supervised learning scheme where a large amount of annotated data is required to reach good performances, which is generally not always available for medical data databases. To overcome this limitation related to labeled data scarcity, the self-supervised learning paradigm has recently shown great success in a number of applications. This paper proposes a novel self-supervised approach for endoscopic image matching based on deep learning techniques. When compared to standard hand-crafted local feature descriptors, our method outperformed them in terms of precision and recall. Furthermore, our self-supervised descriptor provides a competitive performance in comparison to a selection of state-of-the-art deep learning based supervised methods in terms of precision and matching score.
BuildSeg: A General Framework for the Segmentation of Buildings
Jan 15, 2023

Building segmentation from aerial images and 3D laser scanning (LiDAR) is a challenging task due to the diversity of backgrounds, building textures, and image quality. While current research using different types of convolutional and transformer networks has considerably improved the performance on this task, even more accurate segmentation methods for buildings are desirable for applications such as automatic mapping. In this study, we propose a general framework termed \emph{BuildSeg} employing a generic approach that can be quickly applied to segment buildings. Different data sources were combined to increase generalization performance. The approach yields good results for different data sources as shown by experiments on high-resolution multi-spectral and LiDAR imagery of cities in Norway, Denmark and France. We applied ConvNeXt and SegFormer based models on the high resolution aerial image dataset from the MapAI-competition. The methods achieved an IOU of 0.7902 and a boundary IOU of 0.6185. We used post-processing to account for the rectangular shape of the objects. This increased the boundary IOU from 0.6185 to 0.6189.
Extracting Training Data from Diffusion Models
Jan 30, 2023


Image diffusion models such as DALL-E 2, Imagen, and Stable Diffusion have attracted significant attention due to their ability to generate high-quality synthetic images. In this work, we show that diffusion models memorize individual images from their training data and emit them at generation time. With a generate-and-filter pipeline, we extract over a thousand training examples from state-of-the-art models, ranging from photographs of individual people to trademarked company logos. We also train hundreds of diffusion models in various settings to analyze how different modeling and data decisions affect privacy. Overall, our results show that diffusion models are much less private than prior generative models such as GANs, and that mitigating these vulnerabilities may require new advances in privacy-preserving training.