 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical Lens Attack on Monocular Depth Estimation for Autonomous Driving
Oct 31, 2024



Monocular Depth Estimation (MDE) is a pivotal component of vision-based Autonomous Driving (AD) systems, enabling vehicles to estimate the depth of surrounding objects using a single camera image. This estimation guides essential driving decisions, such as braking before an obstacle or changing lanes to avoid collisions. In this paper, we explore vulnerabilities of MDE algorithms in AD systems, presenting LensAttack, a novel physical attack that strategically places optical lenses on the camera of an autonomous vehicle to manipulate the perceived object depths. LensAttack encompasses two attack formats: concave lens attack and convex lens attack, each utilizing different optical lenses to induce false depth perception. We first develop a mathematical model that outlines the parameters of the attack, followed by simulations and real-world evaluations to assess its efficacy on state-of-the-art MDE models. Additionally, we adopt an attack optimization method to further enhance the attack success rate by optimizing the attack focal length. To better evaluate the implications of LensAttack on AD, we conduct comprehensive end-to-end system simulations using the CARLA platform. The results reveal that LensAttack can significantly disrupt the depth estimation processes in AD systems, posing a serious threat to their reliability and safety. Finally, we discuss some potential defense methods to mitigate the effects of the proposed attack.
Optical Lens Attack on Deep Learning Based Monocular Depth Estimation
Sep 25, 2024



Monocular Depth Estimation (MDE) plays a crucial role in vision-based Autonomous Driving (AD) systems. It utilizes a single-camera image to determine the depth of objects, facilitating driving decisions such as braking a few meters in front of a detected obstacle or changing lanes to avoid collision. In this paper, we investigate the security risks associated with monocular vision-based depth estimation algorithms utilized by AD systems. By exploiting the vulnerabilities of MDE and the principles of optical lenses, we introduce LensAttack, a physical attack that involves strategically placing optical lenses on the camera of an autonomous vehicle to manipulate the perceived object depths. LensAttack encompasses two attack formats: concave lens attack and convex lens attack, each utilizing different optical lenses to induce false depth perception. We begin by constructing a mathematical model of our attack, incorporating various attack parameters. Subsequently, we simulate the attack and evaluate its real-world performance in driving scenarios to demonstrate its effect on state-of-the-art MDE models. The results highlight the significant impact of LensAttack on the accuracy of depth estimation in AD systems.
Transient Adversarial 3D Projection Attacks on Object Detection in Autonomous Driving
Sep 25, 2024Object detection is a crucial task in autonomous driving. While existing research has proposed various attacks on object detection, such as those using adversarial patches or stickers, the exploration of projection attacks on 3D surfaces remains largely unexplored. Compared to adversarial patches or stickers, which have fixed adversarial patterns, projection attacks allow for transient modifications to these patterns, enabling a more flexible attack. In this paper, we introduce an adversarial 3D projection attack specifically targeting object detection in autonomous driving scenarios. We frame the attack formulation as an optimization problem, utilizing a combination of color mapping and geometric transformation models. Our results demonstrate the effectiveness of the proposed attack in deceiving YOLOv3 and Mask R-CNN in physical settings. Evaluations conducted in an indoor environment show an attack success rate of up to 100% under low ambient light conditions, highlighting the potential damage of our attack in real-world driving scenarios.
Protecting Activity Sensing Data Privacy Using Hierarchical Information Dissociation
Sep 04, 2024



Smartphones and wearable devices have been integrated into our daily lives, offering personalized services. However, many apps become overprivileged as their collected sensing data contains unnecessary sensitive information. For example, mobile sensing data could reveal private attributes (e.g., gender and age) and unintended sensitive features (e.g., hand gestures when entering passwords). To prevent sensitive information leakage, existing methods must obtain private labels and users need to specify privacy policies. However, they only achieve limited control over information disclosure. In this work, we present Hippo to dissociate hierarchical information including private metadata and multi-grained activity information from the sensing data. Hippo achieves fine-grained control over the disclosure of sensitive information without requiring private labels. Specifically, we design a latent guidance-based diffusion model, which generates multi-grained versions of raw sensor data conditioned on hierarchical latent activity features. Hippo enables users to control the disclosure of sensitive information in sensing data, ensuring their privacy while preserving the necessary features to meet the utility requirements of applications. Hippo is the first unified model that achieves two goals: perturbing the sensitive attributes and controlling the disclosure of sensitive information in mobile sensing data. Extensive experiments show that Hippo can anonymize personal attributes and transform activity information at various resolutions across different types of sensing data.
MedTrinity-25M: A Large-scale Multimodal Dataset with Multigranular Annotations for Medicine
Aug 06, 2024This paper introduces MedTrinity-25M, a comprehensive, large-scale multimodal dataset for medicine, covering over 25 million images across 10 modalities, with multigranular annotations for more than 65 diseases. These enriched annotations encompass both global textual information, such as disease/lesion type, modality, region-specific descriptions, and inter-regional relationships, as well as detailed local annotations for regions of interest (ROIs), including bounding boxes, segmentation masks. Unlike existing approach which is limited by the availability of image-text pairs, we have developed the first automated pipeline that scales up multimodal data by generating multigranular visual and texual annotations (in the form of image-ROI-description triplets) without the need for any paired text descriptions. Specifically, data from over 90 different sources have been collected, preprocessed, and grounded using domain-specific expert models to identify ROIs related to abnormal regions. We then build a comprehensive knowledge base and prompt multimodal large language models to perform retrieval-augmented generation with the identified ROIs as guidance, resulting in multigranular texual descriptions. Compared to existing datasets, MedTrinity-25M provides the most enriched annotations, supporting a comprehensive range of multimodal tasks such as captioning and report generation, as well as vision-centric tasks like classification and segmentation. Pretraining on MedTrinity-25M, our model achieves state-of-the-art performance on VQA-RAD and PathVQA, surpassing both multimodal large language models and other representative SoTA approaches. This dataset can also be utilized to support large-scale pre-training of multimodal medical AI models, contributing to the development of future foundation models in the medical domain.
Beyond Boundaries: A Comprehensive Survey of Transferable Attacks on AI Systems
Nov 20, 2023



Artificial Intelligence (AI) systems such as autonomous vehicles, facial recognition, and speech recognition systems are increasingly integrated into our daily lives. However, despite their utility, these AI systems are vulnerable to a wide range of attacks such as adversarial, backdoor, data poisoning, membership inference, model inversion, and model stealing attacks. In particular, numerous attacks are designed to target a particular model or system, yet their effects can spread to additional targets, referred to as transferable attacks. Although considerable efforts have been directed toward developing transferable attacks, a holistic understanding of the advancements in transferable attacks remains elusive. In this paper, we comprehensively explore learning-based attacks from the perspective of transferability, particularly within the context of cyber-physical security. We delve into different domains -- the image, text, graph, audio, and video domains -- to highlight the ubiquitous and pervasive nature of transferable attacks. This paper categorizes and reviews the architecture of existing attacks from various viewpoints: data, process, model, and system. We further examine the implications of transferable attacks in practical scenarios such as autonomous driving, speech recognition, and large language models (LLMs). Additionally, we outline the potential research directions to encourage efforts in exploring the landscape of transferable attacks. This survey offers a holistic understanding of the prevailing transferable attacks and their impacts across different domains.
SSVEP-Based BCI Wheelchair Control System
Jul 12, 2023



A brain-computer interface (BCI) is a system that allows a person to communicate or control the surroundings without depending on the brain's normal output pathways of peripheral nerves and muscles. A lot of successful applications have arisen utilizing the advantages of BCI to assist disabled people with so-called assistive technology. Considering using BCI has fewer limitations and huge potential, this project has been proposed to control the movement of an electronic wheelchair via brain signals. The goal of this project is to help disabled people, especially paralyzed people suffering from motor disabilities, improve their life qualities. In order to realize the project stated above, Steady-State Visual Evoked Potential (SSVEP) is involved. It can be easily elicited in the visual cortical with the same frequency as the one is being focused by the subject. There are two important parts in this project. One is to process the EEG signals and another one is to make a visual stimulator using hardware. The EEG signals are processed in Matlab using the algorithm of Butterworth Infinite Impulse Response (IIR) bandpass filter (for preprocessing) and Fast Fourier Transform (FFT) (for feature extraction). Besides, a harmonics-based classification method is proposed and applied in the classification part. Moreover, the design of the visual stimulator combines LEDs as flickers and LCDs as information displayers on one panel. Microcontrollers are employed to control the SSVEP visual stimuli panel. This project is evaluated by subjects with different races and ages. Experimental results show the system is easy to be operated and it can achieve approximately a minimum 1-second time delay. So it demonstrates that this SSVEP-based BCI-controlled wheelchair has a huge potential to be applied to disabled people in the future.
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
Feb 18, 2023The Pretrained Foundation Models (PFMs) are regarded as the foundation for various downstream tasks with different data modalities. A pretrained foundation model, such as BERT, GPT-3, MAE, DALLE-E, and ChatGPT, is trained on large-scale data which provides a reasonable parameter initialization for a wide range of downstream applications. The idea of pretraining behind PFMs plays an important role in the application of large models. Different from previous methods that apply convolution and recurrent modules for feature extractions, the generative pre-training (GPT) method applies Transformer as the feature extractor and is trained on large datasets with an autoregressive paradigm. Similarly, the BERT apples transformers to train on large datasets as a contextual language model. Recently, the ChatGPT shows promising success on large language models, which applies an autoregressive language model with zero shot or few show prompting. With the extraordinary success of PFMs, AI has made waves in a variety of fields over the past few years. Considerable methods, datasets, and evaluation metrics have been proposed in the literature, the need is raising for an updated survey. This study provides a comprehensive review of recent research advancements, current and future challenges, and opportunities for PFMs in text, image, graph, as well as other data modalities. We first review the basic components and existing pretraining in natural language processing, computer vision, and graph learning. We then discuss other advanced PFMs for other data modalities and unified PFMs considering the data quality and quantity. Besides, we discuss relevant research about the fundamentals of the PFM, including model efficiency and compression, security, and privacy. Finally, we lay out key implications, future research directions, challenges, and open problems.
DoubleStar: Long-Range Attack Towards Depth Estimation based Obstacle Avoidance in Autonomous Systems
Oct 07, 2021
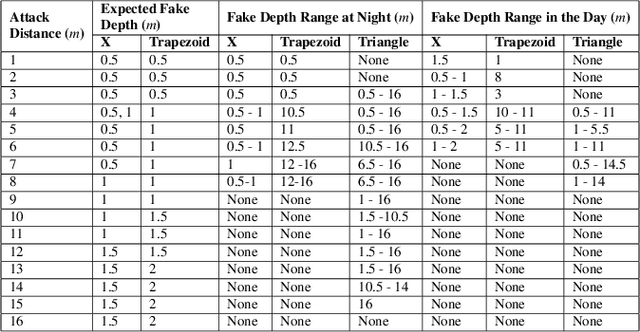
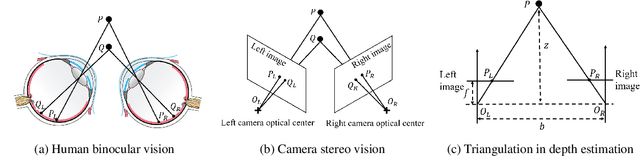
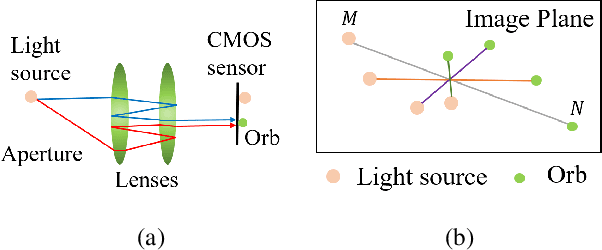
Depth estimation-based obstacle avoidance has been widely adopted by autonomous systems (drones and vehicles) for safety purpose. It normally relies on a stereo camera to automatically detect obstacles and make flying/driving decisions, e.g., stopping several meters ahead of the obstacle in the path or moving away from the detected obstacle. In this paper, we explore new security risks associated with the stereo vision-based depth estimation algorithms used for obstacle avoidance. By exploiting the weaknesses of the stereo matching in depth estimation algorithms and the lens flare effect in optical imaging, we propose DoubleStar, a long-range attack that injects fake obstacle depth by projecting pure light from two complementary light sources. DoubleStar includes two distinctive attack formats: beams attack and orbs attack, which leverage projected light beams and lens flare orbs respectively to cause false depth perception. We successfully attack two commercial stereo cameras designed for autonomous systems (ZED and Intel RealSense). The visualization of fake depth perceived by the stereo cameras illustrates the false stereo matching induced by DoubleStar. We further use Ardupilot to simulate the attack and demonstrate its impact on drones. To validate the attack on real systems, we perform a real-world attack towards a commercial drone equipped with state-of-the-art obstacle avoidance algorithms. Our attack can continuously bring a flying drone to a sudden stop or drift it away across a long distance under various lighting conditions, even bypassing sensor fusion mechanisms. Specifically, our experimental results show that DoubleStar creates fake depth up to 15 meters in distance at night and up to 8 meters during the daytime. To mitigate this newly discovered threat, we provide discussions on potential countermeasures to defend against DoubleStar.