 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDota 2
Papers and Code
SPWOOD: Sparse Partial Weakly-Supervised Oriented Object Detection
Feb 03, 2026A consistent trend throughout the research of oriented object detection has been the pursuit of maintaining comparable performance with fewer and weaker annotations. This is particularly crucial in the remote sensing domain, where the dense object distribution and a wide variety of categories contribute to prohibitively high costs. Based on the supervision level, existing oriented object detection algorithms can be broadly grouped into fully supervised, semi-supervised, and weakly supervised methods. Within the scope of this work, we further categorize them to include sparsely supervised and partially weakly-supervised methods. To address the challenges of large-scale labeling, we introduce the first Sparse Partial Weakly-Supervised Oriented Object Detection framework, designed to efficiently leverage only a few sparse weakly-labeled data and plenty of unlabeled data. Our framework incorporates three key innovations: (1) We design a Sparse-annotation-Orientation-and-Scale-aware Student (SOS-Student) model to separate unlabeled objects from the background in a sparsely-labeled setting, and learn orientation and scale information from orientation-agnostic or scale-agnostic weak annotations. (2) We construct a novel Multi-level Pseudo-label Filtering strategy that leverages the distribution of model predictions, which is informed by the model's multi-layer predictions. (3) We propose a unique sparse partitioning approach, ensuring equal treatment for each category. Extensive experiments on the DOTA and DIOR datasets show that our framework achieves a significant performance gain over traditional oriented object detection methods mentioned above, offering a highly cost-effective solution. Our code is publicly available at https://github.com/VisionXLab/SPWOOD.
PADE: A Predictor-Free Sparse Attention Accelerator via Unified Execution and Stage Fusion
Dec 16, 2025



Attention-based models have revolutionized AI, but the quadratic cost of self-attention incurs severe computational and memory overhead. Sparse attention methods alleviate this by skipping low-relevance token pairs. However, current approaches lack practicality due to the heavy expense of added sparsity predictor, which severely drops their hardware efficiency. This paper advances the state-of-the-art (SOTA) by proposing a bit-serial enable stage-fusion (BSF) mechanism, which eliminates the need for a separate predictor. However, it faces key challenges: 1) Inaccurate bit-sliced sparsity speculation leads to incorrect pruning; 2) Hardware under-utilization due to fine-grained and imbalanced bit-level workloads. 3) Tiling difficulty caused by the row-wise dependency in sparsity pruning criteria. We propose PADE, a predictor-free algorithm-hardware co-design for dynamic sparse attention acceleration. PADE features three key innovations: 1) Bit-wise uncertainty interval-enabled guard filtering (BUI-GF) strategy to accurately identify trivial tokens during each bit round; 2) Bidirectional sparsity-based out-of-order execution (BS-OOE) to improve hardware utilization; 3) Interleaving-based sparsity-tiled attention (ISTA) to reduce both I/O and computational complexity. These techniques, combined with custom accelerator designs, enable practical sparsity acceleration without relying on an added sparsity predictor. Extensive experiments on 22 benchmarks show that PADE achieves 7.43x speed up and 31.1x higher energy efficiency than Nvidia H100 GPU. Compared to SOTA accelerators, PADE achieves 5.1x, 4.3x and 3.4x energy saving than Sanger, DOTA and SOFA.
A Comprehensive Review of Multi-Agent Reinforcement Learning in Video Games
Sep 03, 2025Recent advancements in multi-agent reinforcement learning (MARL) have demonstrated its application potential in modern games. Beginning with foundational work and progressing to landmark achievements such as AlphaStar in StarCraft II and OpenAI Five in Dota 2, MARL has proven capable of achieving superhuman performance across diverse game environments through techniques like self-play, supervised learning, and deep reinforcement learning. With its growing impact, a comprehensive review has become increasingly important in this field. This paper aims to provide a thorough examination of MARL's application from turn-based two-agent games to real-time multi-agent video games including popular genres such as Sports games, First-Person Shooter (FPS) games, Real-Time Strategy (RTS) games and Multiplayer Online Battle Arena (MOBA) games. We further analyze critical challenges posed by MARL in video games, including nonstationary, partial observability, sparse rewards, team coordination, and scalability, and highlight successful implementations in games like Rocket League, Minecraft, Quake III Arena, StarCraft II, Dota 2, Honor of Kings, etc. This paper offers insights into MARL in video game AI systems, proposes a novel method to estimate game complexity, and suggests future research directions to advance MARL and its applications in game development, inspiring further innovation in this rapidly evolving field.
Partial Weakly-Supervised Oriented Object Detection
Jul 03, 2025



The growing demand for oriented object detection (OOD) across various domains has driven significant research in this area. However, the high cost of dataset annotation remains a major concern. Current mainstream OOD algorithms can be mainly categorized into three types: (1) fully supervised methods using complete oriented bounding box (OBB) annotations, (2) semi-supervised methods using partial OBB annotations, and (3) weakly supervised methods using weak annotations such as horizontal boxes or points. However, these algorithms inevitably increase the cost of models in terms of annotation speed or annotation cost. To address this issue, we propose:(1) the first Partial Weakly-Supervised Oriented Object Detection (PWOOD) framework based on partially weak annotations (horizontal boxes or single points), which can efficiently leverage large amounts of unlabeled data, significantly outperforming weakly supervised algorithms trained with partially weak annotations, also offers a lower cost solution; (2) Orientation-and-Scale-aware Student (OS-Student) model capable of learning orientation and scale information with only a small amount of orientation-agnostic or scale-agnostic weak annotations; and (3) Class-Agnostic Pseudo-Label Filtering strategy (CPF) to reduce the model's sensitivity to static filtering thresholds. Comprehensive experiments on DOTA-v1.0/v1.5/v2.0 and DIOR datasets demonstrate that our PWOOD framework performs comparably to, or even surpasses, traditional semi-supervised algorithms.
Context-Aware Toxicity Detection in Multiplayer Games: Integrating Domain-Adaptive Pretraining and Match Metadata
Apr 02, 2025The detrimental effects of toxicity in competitive online video games are widely acknowledged, prompting publishers to monitor player chat conversations. This is challenging due to the context-dependent nature of toxicity, often spread across multiple messages or informed by non-textual interactions. Traditional toxicity detectors focus on isolated messages, missing the broader context needed for accurate moderation. This is especially problematic in video games, where interactions involve specialized slang, abbreviations, and typos, making it difficult for standard models to detect toxicity, especially given its rarity. We adapted RoBERTa LLM to support moderation tailored to video games, integrating both textual and non-textual context. By enhancing pretrained embeddings with metadata and addressing the unique slang and language quirks through domain adaptive pretraining, our method better captures the nuances of player interactions. Using two gaming datasets - from Defense of the Ancients 2 (DOTA 2) and Call of Duty$^\circledR$: Modern Warfare$^\circledR$III (MWIII) we demonstrate which sources of context (metadata, prior interactions...) are most useful, how to best leverage them to boost performance, and the conditions conducive to doing so. This work underscores the importance of context-aware and domain-specific approaches for proactive moderation.
Semantic-decoupled Spatial Partition Guided Point-supervised Oriented Object Detection
Jun 12, 2025Recent remote sensing tech advancements drive imagery growth, making oriented object detection rapid development, yet hindered by labor-intensive annotation for high-density scenes. Oriented object detection with point supervision offers a cost-effective solution for densely packed scenes in remote sensing, yet existing methods suffer from inadequate sample assignment and instance confusion due to rigid rule-based designs. To address this, we propose SSP (Semantic-decoupled Spatial Partition), a unified framework that synergizes rule-driven prior injection and data-driven label purification. Specifically, SSP introduces two core innovations: 1) Pixel-level Spatial Partition-based Sample Assignment, which compactly estimates the upper and lower bounds of object scales and mines high-quality positive samples and hard negative samples through spatial partitioning of pixel maps. 2) Semantic Spatial Partition-based Box Extraction, which derives instances from spatial partitions modulated by semantic maps and reliably converts them into bounding boxes to form pseudo-labels for supervising the learning of downstream detectors. Experiments on DOTA-v1.0 and others demonstrate SSP\' s superiority: it achieves 45.78% mAP under point supervision, outperforming SOTA method PointOBB-v2 by 4.10%. Furthermore, when integrated with ORCNN and ReDet architectures, the SSP framework achieves mAP values of 47.86% and 48.50%, respectively. The code is available at https://github.com/antxinyuan/ssp.
S$^2$Teacher: Step-by-step Teacher for Sparsely Annotated Oriented Object Detection
Apr 15, 2025



Although fully-supervised oriented object detection has made significant progress in multimodal remote sensing image understanding, it comes at the cost of labor-intensive annotation. Recent studies have explored weakly and semi-supervised learning to alleviate this burden. However, these methods overlook the difficulties posed by dense annotations in complex remote sensing scenes. In this paper, we introduce a novel setting called sparsely annotated oriented object detection (SAOOD), which only labels partial instances, and propose a solution to address its challenges. Specifically, we focus on two key issues in the setting: (1) sparse labeling leading to overfitting on limited foreground representations, and (2) unlabeled objects (false negatives) confusing feature learning. To this end, we propose the S$^2$Teacher, a novel method that progressively mines pseudo-labels for unlabeled objects, from easy to hard, to enhance foreground representations. Additionally, it reweights the loss of unlabeled objects to mitigate their impact during training. Extensive experiments demonstrate that S$^2$Teacher not only significantly improves detector performance across different sparse annotation levels but also achieves near-fully-supervised performance on the DOTA dataset with only 10% annotation instances, effectively balancing detection accuracy with annotation efficiency. The code will be public.
Spiking Meets Attention: Efficient Remote Sensing Image Super-Resolution with Attention Spiking Neural Networks
Mar 06, 2025Spiking neural networks (SNNs) are emerging as a promising alternative to traditional artificial neural networks (ANNs), offering biological plausibility and energy efficiency. Despite these merits, SNNs are frequently hampered by limited capacity and insufficient representation power, yet remain underexplored in remote sensing super-resolution (SR) tasks. In this paper, we first observe that spiking signals exhibit drastic intensity variations across diverse textures, highlighting an active learning state of the neurons. This observation motivates us to apply SNNs for efficient SR of RSIs. Inspired by the success of attention mechanisms in representing salient information, we devise the spiking attention block (SAB), a concise yet effective component that optimizes membrane potentials through inferred attention weights, which, in turn, regulates spiking activity for superior feature representation. Our key contributions include: 1) we bridge the independent modulation between temporal and channel dimensions, facilitating joint feature correlation learning, and 2) we access the global self-similar patterns in large-scale remote sensing imagery to infer spatial attention weights, incorporating effective priors for realistic and faithful reconstruction. Building upon SAB, we proposed SpikeSR, which achieves state-of-the-art performance across various remote sensing benchmarks such as AID, DOTA, and DIOR, while maintaining high computational efficiency. The code of SpikeSR will be available upon paper acceptance.
LEGNet: Lightweight Edge-Gaussian Driven Network for Low-Quality Remote Sensing Image Object Detection
Mar 18, 2025
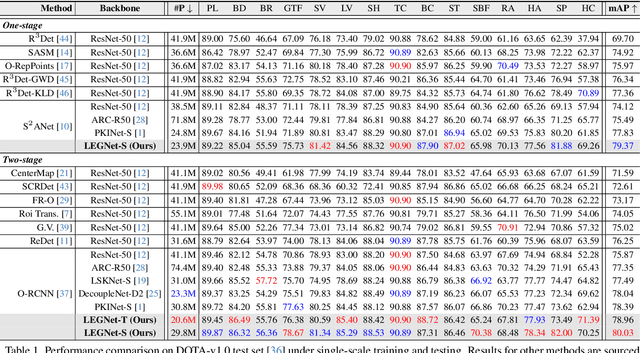
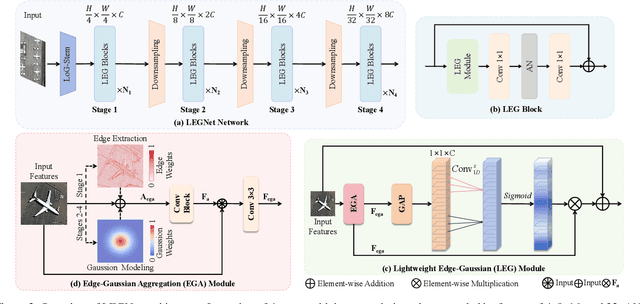
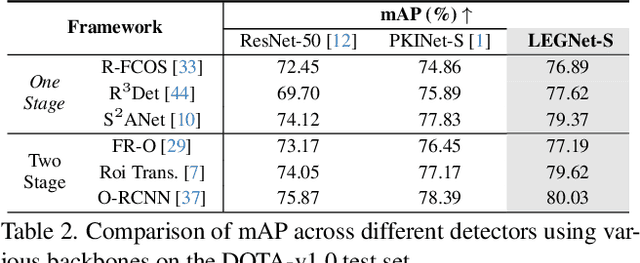
Remote sensing object detection (RSOD) faces formidable challenges in complex visual environments. Aerial and satellite images inherently suffer from limitations such as low spatial resolution, sensor noise, blurred objects, low-light degradation, and partial occlusions. These degradation factors collectively compromise the feature discriminability in detection models, resulting in three key issues: (1) reduced contrast that hampers foreground-background separation, (2) structural discontinuities in edge representations, and (3) ambiguous feature responses caused by variations in illumination. These collectively weaken model robustness and deployment feasibility. To address these challenges, we propose LEGNet, a lightweight network that incorporates a novel edge-Gaussian aggregation (EGA) module specifically designed for low-quality remote sensing images. Our key innovation lies in the synergistic integration of Scharr operator-based edge priors with uncertainty-aware Gaussian modeling: (a) The orientation-aware Scharr filters preserve high-frequency edge details with rotational invariance; (b) The uncertainty-aware Gaussian layers probabilistically refine low-confidence features through variance estimation. This design enables precision enhancement while maintaining architectural simplicity. Comprehensive evaluations across four RSOD benchmarks (DOTA-v1.0, v1.5, DIOR-R, FAIR1M-v1.0) and a UAV-view dataset (VisDrone2019) demonstrate significant improvements. LEGNet achieves state-of-the-art performance across five benchmark datasets while ensuring computational efficiency, making it well-suited for deployment on resource-constrained edge devices in real-world remote sensing applications. The code is available at https://github.com/lwCVer/LEGNet.
Fine-Tuning Pre-trained Language Models to Detect In-Game Trash Talks
Mar 19, 2024



Common problems in playing online mobile and computer games were related to toxic behavior and abusive communication among players. Based on different reports and studies, the study also discusses the impact of online hate speech and toxicity on players' in-game performance and overall well-being. This study investigates the capability of pre-trained language models to classify or detect trash talk or toxic in-game messages The study employs and evaluates the performance of pre-trained BERT and GPT language models in detecting toxicity within in-game chats. Using publicly available APIs, in-game chat data from DOTA 2 game matches were collected, processed, reviewed, and labeled as non-toxic, mild (toxicity), and toxic. The study was able to collect around two thousand in-game chats to train and test BERT (Base-uncased), BERT (Large-uncased), and GPT-3 models. Based on the three models' state-of-the-art performance, this study concludes pre-trained language models' promising potential for addressing online hate speech and in-game insulting trash talk.