 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoding Problem Tagging
Papers and Code
Geo-ATBench: A Benchmark for Geospatial Audio Tagging with Geospatial Semantic Context
Mar 11, 2026Environmental sound understanding in computational auditory scene analysis (CASA) is often formulated as an audio-only recognition problem. This formulation leaves a persistent drawback in multi-label audio tagging (AT): acoustic similarity can make certain events difficult to separate from waveforms alone. In such cases, disambiguating cues often lie outside the waveform. Geospatial semantic context (GSC), derived from geographic information system data, e.g., points of interest (POI), provides location-tied environmental priors that can help reduce this ambiguity. A systematic study of this direction is enabled through the proposed geospatial audio tagging (Geo-AT) task, which conditions multi-label sound event tagging on GSC alongside audio. To benchmark Geo-AT, Geo-ATBench is introduced as a polyphonic audio benchmark with geographical annotations, containing 10.71 hours of audio across 28 event categories; each clip is paired with a GSC representation from 11 semantic context categories. GeoFusion-AT is proposed as a unified geo-audio fusion framework that evaluates feature-, representation-, and decision-level fusion on representative audio backbones, with audio- and GSC-only baselines. Results show that incorporating GSC improves AT performance, especially on acoustically confounded labels, indicating geospatial semantics provide effective priors beyond audio alone. A crowdsourced listening study with 10 participants on 579 samples shows that there is no significant difference in performance between models on Geo-ATBench labels and aggregated human labels, supporting Geo-ATBench as a human-aligned benchmark. The Geo-AT task, benchmark Geo-ATBench, and reproducible geo-audio fusion framework GeoFusion-AT provide a foundation for studying AT with geospatial semantic context within the CASA community. Dataset, code, models are on homepage (https://github.com/WuYanru2002/Geo-ATBench).
Prompt Tuning without Labeled Samples for Zero-Shot Node Classification in Text-Attributed Graphs
Jan 07, 2026Node classification is a fundamental problem in information retrieval with many real-world applications, such as community detection in social networks, grouping articles published online and product categorization in e-commerce. Zero-shot node classification in text-attributed graphs (TAGs) presents a significant challenge, particularly due to the absence of labeled data. In this paper, we propose a novel Zero-shot Prompt Tuning (ZPT) framework to address this problem by leveraging a Universal Bimodal Conditional Generator (UBCG). Our approach begins with pre-training a graph-language model to capture both the graph structure and the associated textual descriptions of each node. Following this, a conditional generative model is trained to learn the joint distribution of nodes in both graph and text modalities, enabling the generation of synthetic samples for each class based solely on the class name. These synthetic node and text embeddings are subsequently used to perform continuous prompt tuning, facilitating effective node classification in a zero-shot setting. Furthermore, we conduct extensive experiments on multiple benchmark datasets, demonstrating that our framework performs better than existing state-of-the-art baselines. We also provide ablation studies to validate the contribution of the bimodal generator. The code is provided at: https://github.com/Sethup123/ZPT.
Explicit Discovery of Nonlinear Symmetries from Dynamic Data
Oct 02, 2025Symmetry is widely applied in problems such as the design of equivariant networks and the discovery of governing equations, but in complex scenarios, it is not known in advance. Most previous symmetry discovery methods are limited to linear symmetries, and recent attempts to discover nonlinear symmetries fail to explicitly get the Lie algebra subspace. In this paper, we propose LieNLSD, which is, to our knowledge, the first method capable of determining the number of infinitesimal generators with nonlinear terms and their explicit expressions. We specify a function library for the infinitesimal group action and aim to solve for its coefficient matrix, proving that its prolongation formula for differential equations, which governs dynamic data, is also linear with respect to the coefficient matrix. By substituting the central differences of the data and the Jacobian matrix of the trained neural network into the infinitesimal criterion, we get a system of linear equations for the coefficient matrix, which can then be solved using SVD. On top quark tagging and a series of dynamic systems, LieNLSD shows qualitative advantages over existing methods and improves the long rollout accuracy of neural PDE solvers by over 20% while applying to guide data augmentation. Code and data are available at https://github.com/hulx2002/LieNLSD.
HiD-VAE: Interpretable Generative Recommendation via Hierarchical and Disentangled Semantic IDs
Aug 06, 2025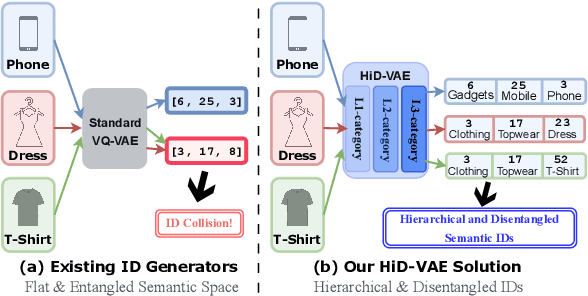
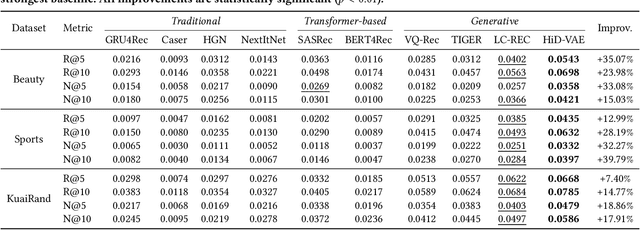
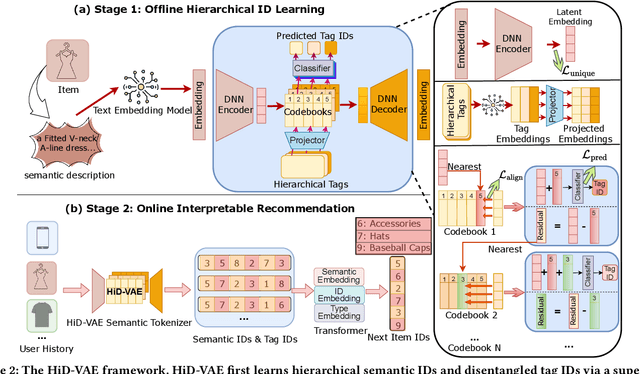
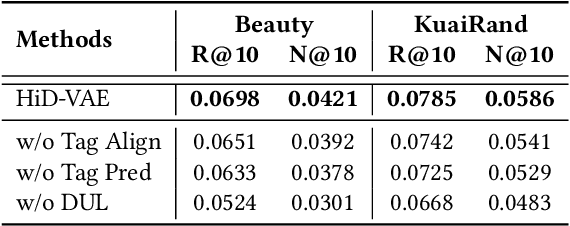
Recommender systems are indispensable for helping users navigate the immense item catalogs of modern online platforms. Recently, generative recommendation has emerged as a promising paradigm, unifying the conventional retrieve-and-rank pipeline into an end-to-end model capable of dynamic generation. However, existing generative methods are fundamentally constrained by their unsupervised tokenization, which generates semantic IDs suffering from two critical flaws: (1) they are semantically flat and uninterpretable, lacking a coherent hierarchy, and (2) they are prone to representation entanglement (i.e., ``ID collisions''), which harms recommendation accuracy and diversity. To overcome these limitations, we propose HiD-VAE, a novel framework that learns hierarchically disentangled item representations through two core innovations. First, HiD-VAE pioneers a hierarchically-supervised quantization process that aligns discrete codes with multi-level item tags, yielding more uniform and disentangled IDs. Crucially, the trained codebooks can predict hierarchical tags, providing a traceable and interpretable semantic path for each recommendation. Second, to combat representation entanglement, HiD-VAE incorporates a novel uniqueness loss that directly penalizes latent space overlap. This mechanism not only resolves the critical ID collision problem but also promotes recommendation diversity by ensuring a more comprehensive utilization of the item representation space. These high-quality, disentangled IDs provide a powerful foundation for downstream generative models. Extensive experiments on three public benchmarks validate HiD-VAE's superior performance against state-of-the-art methods. The code is available at https://anonymous.4open.science/r/HiD-VAE-84B2.
FinTagging: An LLM-ready Benchmark for Extracting and Structuring Financial Information
May 27, 2025We introduce FinTagging, the first full-scope, table-aware XBRL benchmark designed to evaluate the structured information extraction and semantic alignment capabilities of large language models (LLMs) in the context of XBRL-based financial reporting. Unlike prior benchmarks that oversimplify XBRL tagging as flat multi-class classification and focus solely on narrative text, FinTagging decomposes the XBRL tagging problem into two subtasks: FinNI for financial entity extraction and FinCL for taxonomy-driven concept alignment. It requires models to jointly extract facts and align them with the full 10k+ US-GAAP taxonomy across both unstructured text and structured tables, enabling realistic, fine-grained evaluation. We assess a diverse set of LLMs under zero-shot settings, systematically analyzing their performance on both subtasks and overall tagging accuracy. Our results reveal that, while LLMs demonstrate strong generalization in information extraction, they struggle with fine-grained concept alignment, particularly in disambiguating closely related taxonomy entries. These findings highlight the limitations of existing LLMs in fully automating XBRL tagging and underscore the need for improved semantic reasoning and schema-aware modeling to meet the demands of accurate financial disclosure. Code is available at our GitHub repository and data is at our Hugging Face repository.
Z1: Efficient Test-time Scaling with Code
Apr 01, 2025



Large Language Models (LLMs) can achieve enhanced complex problem-solving through test-time computing scaling, yet this often entails longer contexts and numerous reasoning token costs. In this paper, we propose an efficient test-time scaling method that trains LLMs on code-related reasoning trajectories, facilitating their reduction of excess thinking tokens while maintaining performance. First, we create Z1-Code-Reasoning-107K, a curated dataset of simple and complex coding problems paired with their short and long solution trajectories. Second, we present a novel Shifted Thinking Window to mitigate overthinking overhead by removing context-delimiting tags (e.g., <think>. . . </think>) and capping reasoning tokens. Trained with long and short trajectory data and equipped with Shifted Thinking Window, our model, Z1-7B, demonstrates the ability to adjust its reasoning level as the complexity of problems and exhibits efficient test-time scaling across different reasoning tasks that matches R1-Distill-Qwen-7B performance with about 30% of its average thinking tokens. Notably, fine-tuned with only code trajectories, Z1-7B demonstrates generalization to broader reasoning tasks (47.5% on GPQA Diamond). Our analysis of efficient reasoning elicitation also provides valuable insights for future research.
Automated Knowledge Component Generation and Knowledge Tracing for Coding Problems
Feb 25, 2025



Knowledge components (KCs) mapped to problems help model student learning, tracking their mastery levels on fine-grained skills thereby facilitating personalized learning and feedback in online learning platforms. However, crafting and tagging KCs to problems, traditionally performed by human domain experts, is highly labor-intensive. We present a fully automated, LLM-based pipeline for KC generation and tagging for open-ended programming problems. We also develop an LLM-based knowledge tracing (KT) framework to leverage these LLM-generated KCs, which we refer to as KCGen-KT. We conduct extensive quantitative and qualitative evaluations validating the effectiveness of KCGen-KT. On a real-world dataset of student code submissions to open-ended programming problems, KCGen-KT outperforms existing KT methods. We investigate the learning curves of generated KCs and show that LLM-generated KCs have a comparable level-of-fit to human-written KCs under the performance factor analysis (PFA) model. We also conduct a human evaluation to show that the KC tagging accuracy of our pipeline is reasonably accurate when compared to that by human domain experts.
Unlocking a New Rust Programming Experience: Fast and Slow Thinking with LLMs to Conquer Undefined Behaviors
Mar 04, 2025



To provide flexibility and low-level interaction capabilities, the unsafe tag in Rust is essential in many projects, but undermines memory safety and introduces Undefined Behaviors (UBs) that reduce safety. Eliminating these UBs requires a deep understanding of Rust's safety rules and strong typing. Traditional methods require depth analysis of code, which is laborious and depends on knowledge design. The powerful semantic understanding capabilities of LLM offer new opportunities to solve this problem. Although existing large model debugging frameworks excel in semantic tasks, limited by fixed processes and lack adaptive and dynamic adjustment capabilities. Inspired by the dual process theory of decision-making (Fast and Slow Thinking), we present a LLM-based framework called RustBrain that automatically and flexibly minimizes UBs in Rust projects. Fast thinking extracts features to generate solutions, while slow thinking decomposes, verifies, and generalizes them abstractly. To apply verification and generalization results to solution generation, enabling dynamic adjustments and precise outputs, RustBrain integrates two thinking through a feedback mechanism. Experimental results on Miri dataset show a 94.3% pass rate and 80.4% execution rate, improving flexibility and Rust projects safety.
ProBench: Benchmarking Large Language Models in Competitive Programming
Feb 28, 2025With reasoning language models such as OpenAI-o3 and DeepSeek-R1 emerging, large language models (LLMs) have entered a new phase of development. However, existing benchmarks for coding evaluation are gradually inadequate to assess the capability of advanced LLMs in code reasoning. To bridge the gap for high-level code reasoning assessment, we propose ProBench to benchmark LLMs in competitive programming, drawing inspiration from the International Collegiate Programming Contest. ProBench collects a comprehensive set of competitive programming problems from Codeforces, Luogu, and Nowcoder platforms during the period from July to December 2024, obtaining real test results through online submissions to ensure the fairness and accuracy of the evaluation. We establish a unified problem attribute system, including difficulty grading and algorithm tagging. With carefully collected and annotated data in ProBench, we systematically assess 9 latest LLMs in competitive programming across multiple dimensions, including thought chain analysis, error type diagnosis, and reasoning depth evaluation. Experimental results show that QwQ-32B-Preview achieves the best score of 20.93 followed by DeepSeek-V3 with a score of 16.38, suggesting that models trained with specialized reasoning tasks significantly outperform general-purpose models (even larger than reasoning-oriented models) in programming. Further analysis also reveals key areas for programming capability enhancement, e.g., algorithm adaptability and reasoning sufficiency, providing important insights for the future development of reasoning models.
Exploring Performance-Complexity Trade-Offs in Sound Event Detection
Mar 14, 2025We target the problem of developing new low-complexity networks for the sound event detection task. Our goal is to meticulously analyze the performance-complexity trade-off, aiming to be competitive with the large state-of-the-art models, at a fraction of the computational requirements. We find that low-complexity convolutional models previously proposed for audio tagging can be effectively adapted for event detection (which requires frame-wise prediction) by adjusting convolutional strides, removing the global pooling, and, importantly, adding a sequence model before the (now frame-wise) classification heads. Systematic experiments reveal that the best choice for the sequence model type depends on which complexity metric is most important for the given application. We also investigate the impact of enhanced training strategies such as knowledge distillation. In the end, we show that combined with an optimized training strategy, we can reach event detection performance comparable to state-of-the-art transformers while requiring only around 5% of the parameters. We release all our pre-trained models and the code for reproducing this work to support future research in low-complexity sound event detection at https://github.com/theMoro/EfficientSED.