 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemix the Timbre: Diffusion-Based Style Transfer Across Polyphonic Stems
May 10, 2026Timbre transfer aims to modify the timbral identity of a musical recording while preserving the original melody and rhythm. While single-instrument timbre transfer has made substantial progress, existing approaches to multi-instrument settings rely on separate-then-transfer pipelines that propagate source separation artifacts and produce incoherent synthesized timbres across stems. This paper proposes MixtureTT, to the best of our knowledge the first system for flexible per-stem timbre transfer directly from a polyphonic mixture. Given a mixture and a separate timbre reference for each target voice, MixtureTT jointly transfers all stems to the specified instruments through a shared diffusion process. Modeling the dependencies across the per-stem content and cross-stem harmonic, the proposed joint stem diffusion transformer eliminates cascaded separation error, reduces inference cost by a factor equal to the number of stems, and yields more coherent multi-stem outputs. Despite operating under a strictly harder input condition, evaluations on the SATB choral dataset show that MixtureTT outperforms single-instrument baselines on both objective and subjective metrics demonstrating the necessity of dedicated multi-instrument timbre transfer over the naive separate-then-transfer pipelines. As a result, this work confirms that the cross-stem modeling is essential for mixture-level timbre transfer as the proposed joint setting consistently exceeds an equivalent single-stem ablation.
Geo-ATBench: A Benchmark for Geospatial Audio Tagging with Geospatial Semantic Context
Mar 11, 2026Environmental sound understanding in computational auditory scene analysis (CASA) is often formulated as an audio-only recognition problem. This formulation leaves a persistent drawback in multi-label audio tagging (AT): acoustic similarity can make certain events difficult to separate from waveforms alone. In such cases, disambiguating cues often lie outside the waveform. Geospatial semantic context (GSC), derived from geographic information system data, e.g., points of interest (POI), provides location-tied environmental priors that can help reduce this ambiguity. A systematic study of this direction is enabled through the proposed geospatial audio tagging (Geo-AT) task, which conditions multi-label sound event tagging on GSC alongside audio. To benchmark Geo-AT, Geo-ATBench is introduced as a polyphonic audio benchmark with geographical annotations, containing 10.71 hours of audio across 28 event categories; each clip is paired with a GSC representation from 11 semantic context categories. GeoFusion-AT is proposed as a unified geo-audio fusion framework that evaluates feature-, representation-, and decision-level fusion on representative audio backbones, with audio- and GSC-only baselines. Results show that incorporating GSC improves AT performance, especially on acoustically confounded labels, indicating geospatial semantics provide effective priors beyond audio alone. A crowdsourced listening study with 10 participants on 579 samples shows that there is no significant difference in performance between models on Geo-ATBench labels and aggregated human labels, supporting Geo-ATBench as a human-aligned benchmark. The Geo-AT task, benchmark Geo-ATBench, and reproducible geo-audio fusion framework GeoFusion-AT provide a foundation for studying AT with geospatial semantic context within the CASA community. Dataset, code, models are on homepage (https://github.com/WuYanru2002/Geo-ATBench).
Training a Perceptual Model for Evaluating Auditory Similarity in Music Adversarial Attack
Sep 05, 2025



Music Information Retrieval (MIR) systems are highly vulnerable to adversarial attacks that are often imperceptible to humans, primarily due to a misalignment between model feature spaces and human auditory perception. Existing defenses and perceptual metrics frequently fail to adequately capture these auditory nuances, a limitation supported by our initial listening tests showing low correlation between common metrics and human judgments. To bridge this gap, we introduce Perceptually-Aligned MERT Transformer (PAMT), a novel framework for learning robust, perceptually-aligned music representations. Our core innovation lies in the psychoacoustically-conditioned sequential contrastive transformer, a lightweight projection head built atop a frozen MERT encoder. PAMT achieves a Spearman correlation coefficient of 0.65 with subjective scores, outperforming existing perceptual metrics. Our approach also achieves an average of 9.15\% improvement in robust accuracy on challenging MIR tasks, including Cover Song Identification and Music Genre Classification, under diverse perceptual adversarial attacks. This work pioneers architecturally-integrated psychoacoustic conditioning, yielding representations significantly more aligned with human perception and robust against music adversarial attacks.
MAIA: An Inpainting-Based Approach for Music Adversarial Attacks
Sep 05, 2025
Music adversarial attacks have garnered significant interest in the field of Music Information Retrieval (MIR). In this paper, we present Music Adversarial Inpainting Attack (MAIA), a novel adversarial attack framework that supports both white-box and black-box attack scenarios. MAIA begins with an importance analysis to identify critical audio segments, which are then targeted for modification. Utilizing generative inpainting models, these segments are reconstructed with guidance from the output of the attacked model, ensuring subtle and effective adversarial perturbations. We evaluate MAIA on multiple MIR tasks, demonstrating high attack success rates in both white-box and black-box settings while maintaining minimal perceptual distortion. Additionally, subjective listening tests confirm the high audio fidelity of the adversarial samples. Our findings highlight vulnerabilities in current MIR systems and emphasize the need for more robust and secure models.
Intelligent Fish Detection System with Similarity-Aware Transformer
Sep 28, 2024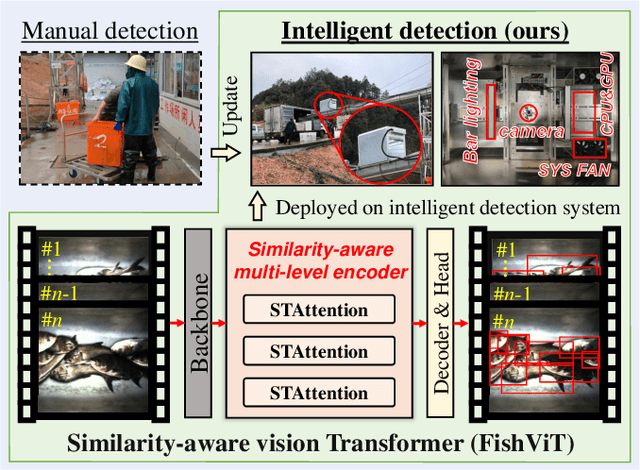
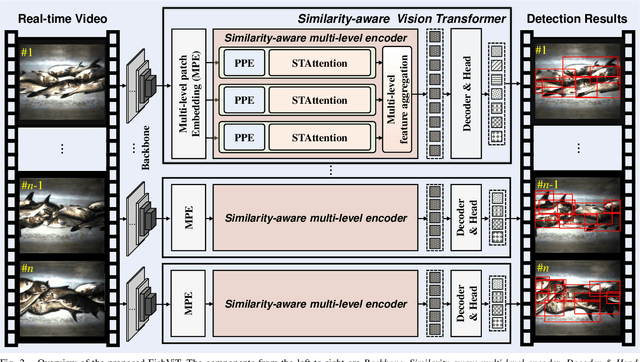
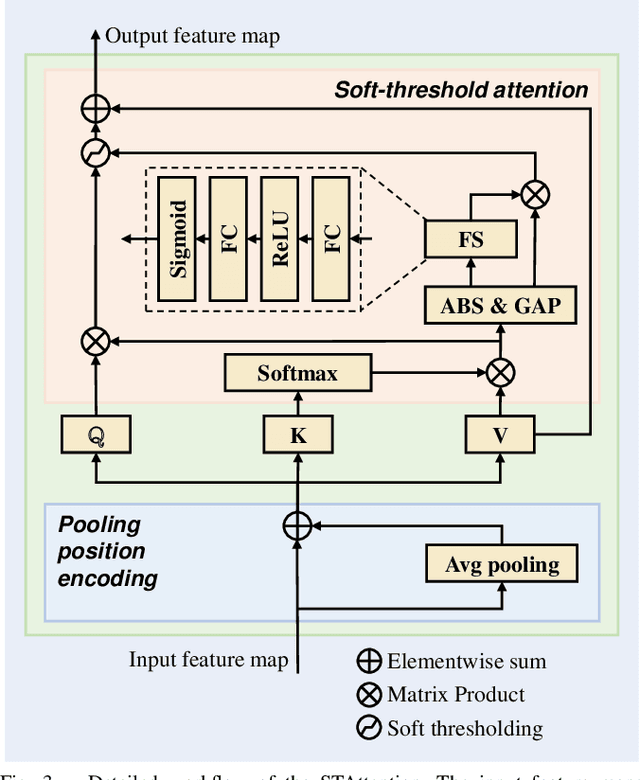

Fish detection in water-land transfer has significantly contributed to the fishery. However, manual fish detection in crowd-collaboration performs inefficiently and expensively, involving insufficient accuracy. To further enhance the water-land transfer efficiency, improve detection accuracy, and reduce labor costs, this work designs a new type of lightweight and plug-and-play edge intelligent vision system to automatically conduct fast fish detection with high-speed camera. Moreover, a novel similarity-aware vision Transformer for fast fish detection (FishViT) is proposed to onboard identify every single fish in a dense and similar group. Specifically, a novel similarity-aware multi-level encoder is developed to enhance multi-scale features in parallel, thereby yielding discriminative representations for varying-size fish. Additionally, a new soft-threshold attention mechanism is introduced, which not only effectively eliminates background noise from images but also accurately recognizes both the edge details and overall features of different similar fish. 85 challenging video sequences with high framerate and high-resolution are collected to establish a benchmark from real fish water-land transfer scenarios. Exhaustive evaluation conducted with this challenging benchmark has proved the robustness and effectiveness of FishViT with over 80 FPS. Real work scenario tests validate the practicality of the proposed method. The code and demo video are available at https://github.com/vision4robotics/FishViT.
Exploring Differences between Human Perception and Model Inference in Audio Event Recognition
Sep 10, 2024



Audio Event Recognition (AER) traditionally focuses on detecting and identifying audio events. Most existing AER models tend to detect all potential events without considering their varying significance across different contexts. This makes the AER results detected by existing models often have a large discrepancy with human auditory perception. Although this is a critical and significant issue, it has not been extensively studied by the Detection and Classification of Sound Scenes and Events (DCASE) community because solving it is time-consuming and labour-intensive. To address this issue, this paper introduces the concept of semantic importance in AER, focusing on exploring the differences between human perception and model inference. This paper constructs a Multi-Annotated Foreground Audio Event Recognition (MAFAR) dataset, which comprises audio recordings labelled by 10 professional annotators. Through labelling frequency and variance, the MAFAR dataset facilitates the quantification of semantic importance and analysis of human perception. By comparing human annotations with the predictions of ensemble pre-trained models, this paper uncovers a significant gap between human perception and model inference in both semantic identification and existence detection of audio events. Experimental results reveal that human perception tends to ignore subtle or trivial events in the event semantic identification, while model inference is easily affected by events with noises. Meanwhile, in event existence detection, models are usually more sensitive than humans.
Leveraging Self-supervised Audio Representations for Data-Efficient Acoustic Scene Classification
Aug 27, 2024Acoustic scene classification (ASC) predominantly relies on supervised approaches. However, acquiring labeled data for training ASC models is often costly and time-consuming. Recently, self-supervised learning (SSL) has emerged as a powerful method for extracting features from unlabeled audio data, benefiting many downstream audio tasks. This paper proposes a data-efficient and low-complexity ASC system by leveraging self-supervised audio representations extracted from general-purpose audio datasets. We introduce BEATs, an audio SSL pre-trained model, to extract the general representations from AudioSet. Through extensive experiments, it has been demonstrated that the self-supervised audio representations can help to achieve high ASC accuracy with limited labeled fine-tuning data. Furthermore, we find that ensembling the SSL models fine-tuned with different strategies contributes to a further performance improvement. To meet low-complexity requirements, we use knowledge distillation to transfer the self-supervised knowledge from large teacher models to an efficient student model. The experimental results suggest that the self-supervised teachers effectively improve the classification accuracy of the student model. Our best-performing system obtains an average accuracy of 56.7%.
TF-SepNet: An Efficient 1D Kernel Design in CNNs for Low-Complexity Acoustic Scene Classification
Sep 15, 2023



Recent studies focus on developing efficient systems for acoustic scene classification (ASC) using convolutional neural networks (CNNs), which typically consist of consecutive kernels. This paper highlights the benefits of using separate kernels as a more powerful and efficient design approach in ASC tasks. Inspired by the time-frequency nature of audio signals, we propose TF-SepNet, a CNN architecture that separates the feature processing along the time and frequency dimensions. Features resulted from the separate paths are then merged by channels and directly forwarded to the classifier. Instead of the conventional two dimensional (2D) kernel, TF-SepNet incorporates one dimensional (1D) kernels to reduce the computational costs. Experiments have been conducted using the TAU Urban Acoustic Scene 2022 Mobile development dataset. The results show that TF-SepNet outperforms similar state-of-the-arts that use consecutive kernels. A further investigation reveals that the separate kernels lead to a larger effective receptive field (ERF), which enables TF-SepNet to capture more time-frequency features.
An Comparative Analysis of Different Pitch and Metrical Grid Encoding Methods in the Task of Sequential Music Generation
Jan 31, 2023Pitch and meter are two fundamental music features for symbolic music generation tasks, where researchers usually choose different encoding methods depending on specific goals. However, the advantages and drawbacks of different encoding methods have not been frequently discussed. This paper presents a integrated analysis of the influence of two low-level feature, pitch and meter, on the performance of a token-based sequential music generation model. First, the commonly used MIDI number encoding and a less used class-octave encoding are compared. Second, an dense intra-bar metric grid is imposed to the encoded sequence as auxiliary features. Different complexity and resolutions of the metric grid are compared. For complexity, the single token approach and the multiple token approach are compared; for grid resolution, 0 (ablation), 1 (bar-level), 4 (downbeat-level) 12, (8th-triplet-level) up to 64 (64th-note-grid-level) are compared; for duration resolution, 4, 8, 12 and 16 subdivisions per beat are compared. All different encodings are tested on separately trained Transformer-XL models for a melody generation task. Regarding distribution similarity of several objective evaluation metrics to the test dataset, results suggest that the class-octave encoding significantly outperforms the taken-for-granted MIDI encoding on pitch-related metrics; finer grids and multiple-token grids improve the rhythmic quality, but also suffer from over-fitting at early training stage. Results display a general phenomenon of over-fitting from two aspects, the pitch embedding space and the test loss of the single-token grid encoding. From a practical perspective, we both demonstrate the feasibility and raise the concern of easy over-fitting problem of using smaller networks and lower embedding dimensions on the generation task. The findings can also contribute to futural models in terms of feature engineering.
Determining Ratio of Prunable Channels in MobileNet by Sparsity for Acoustic Scene Classification
Oct 28, 2022MobileNet is widely used for Acoustic Scene Classification (ASC) in embedded systems. Existing works reduce the complexity of ASC algorithms by pruning some components, e.g. pruning channels in the convolutional layer. In practice, the maximum proportion of channels being pruned, which is defined as Ratio of Prunable Channels ($R_\textit{PC}$), is often decided empirically. This paper proposes a method that determines the $R_\textit{PC}$ by simple linear regression models related to the Sparsity of Channels ($S_C$) in the convolutional layers. In the experiment, $R_\textit{PC}$ is examined by removing inactive channels until reaching a knee point of performance decrease. Simple methods for calculating the $S_C$ of trained models and resulted $R_\textit{PC}$ are proposed. The experiment results demonstrate that 1) the decision of $R_\textit{PC}$ is linearly dependent on $S_C$ and the hyper-parameters have a little impact on the relationship; 2) MobileNet shows a high sensitivity and stability on proposed method.