 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Purified Representation and Integrated Semantic Modeling for Generative Sequential Recommendation
Jan 23, 2026Generative Sequential Recommendation (GSR) has emerged as a promising paradigm, reframing recommendation as an autoregressive sequence generation task over discrete Semantic IDs (SIDs), typically derived via codebook-based quantization. Despite its great potential in unifying retrieval and ranking, existing GSR frameworks still face two critical limitations: (1) impure and unstable semantic tokenization, where quantization methods struggle with interaction noise and codebook collapse, resulting in SIDs with ambiguous discrimination; and (2) lossy and weakly structured generation, where reliance solely on coarse-grained discrete tokens inevitably introduces information loss and neglects items' hierarchical logic. To address these issues, we propose a novel generative recommendation framework, PRISM, with Purified Representation and Integrated Semantic Modeling. Specifically, to ensure high-quality tokenization, we design a Purified Semantic Quantizer that constructs a robust codebook via adaptive collaborative denoising and hierarchical semantic anchoring mechanisms. To compensate for information loss during quantization, we further propose an Integrated Semantic Recommender, which incorporates a dynamic semantic integration mechanism to integrate fine-grained semantics and enforces logical validity through a semantic structure alignment objective. PRISM consistently outperforms state-of-the-art baselines across four real-world datasets, demonstrating substantial performance gains, particularly in high-sparsity scenarios.
Graph Federated Learning for Personalized Privacy Recommendation
Aug 08, 2025Federated recommendation systems (FedRecs) have gained significant attention for providing privacy-preserving recommendation services. However, existing FedRecs assume that all users have the same requirements for privacy protection, i.e., they do not upload any data to the server. The approaches overlook the potential to enhance the recommendation service by utilizing publicly available user data. In real-world applications, users can choose to be private or public. Private users' interaction data is not shared, while public users' interaction data can be shared. Inspired by the issue, this paper proposes a novel Graph Federated Learning for Personalized Privacy Recommendation (GFed-PP) that adapts to different privacy requirements while improving recommendation performance. GFed-PP incorporates the interaction data of public users to build a user-item interaction graph, which is then used to form a user relationship graph. A lightweight graph convolutional network (GCN) is employed to learn each user's user-specific personalized item embedding. To protect user privacy, each client learns the user embedding and the scoring function locally. Additionally, GFed-PP achieves optimization of the federated recommendation framework through the initialization of item embedding on clients and the aggregation of the user relationship graph on the server. Experimental results demonstrate that GFed-PP significantly outperforms existing methods for five datasets, offering superior recommendation accuracy without compromising privacy. This framework provides a practical solution for accommodating varying privacy preferences in federated recommendation systems.
HiD-VAE: Interpretable Generative Recommendation via Hierarchical and Disentangled Semantic IDs
Aug 06, 2025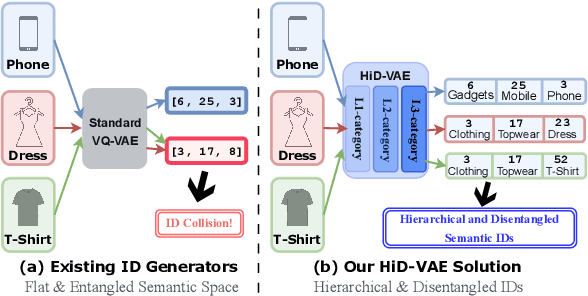
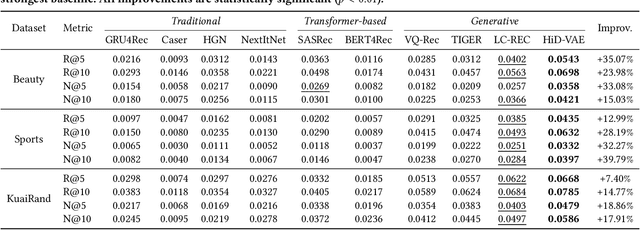
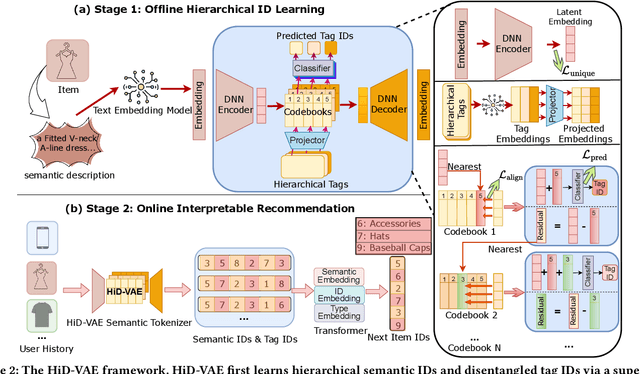
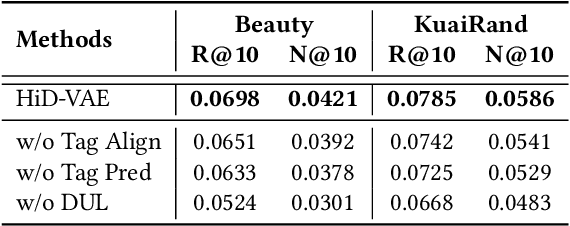
Recommender systems are indispensable for helping users navigate the immense item catalogs of modern online platforms. Recently, generative recommendation has emerged as a promising paradigm, unifying the conventional retrieve-and-rank pipeline into an end-to-end model capable of dynamic generation. However, existing generative methods are fundamentally constrained by their unsupervised tokenization, which generates semantic IDs suffering from two critical flaws: (1) they are semantically flat and uninterpretable, lacking a coherent hierarchy, and (2) they are prone to representation entanglement (i.e., ``ID collisions''), which harms recommendation accuracy and diversity. To overcome these limitations, we propose HiD-VAE, a novel framework that learns hierarchically disentangled item representations through two core innovations. First, HiD-VAE pioneers a hierarchically-supervised quantization process that aligns discrete codes with multi-level item tags, yielding more uniform and disentangled IDs. Crucially, the trained codebooks can predict hierarchical tags, providing a traceable and interpretable semantic path for each recommendation. Second, to combat representation entanglement, HiD-VAE incorporates a novel uniqueness loss that directly penalizes latent space overlap. This mechanism not only resolves the critical ID collision problem but also promotes recommendation diversity by ensuring a more comprehensive utilization of the item representation space. These high-quality, disentangled IDs provide a powerful foundation for downstream generative models. Extensive experiments on three public benchmarks validate HiD-VAE's superior performance against state-of-the-art methods. The code is available at https://anonymous.4open.science/r/HiD-VAE-84B2.
Progressive Document-level Text Simplification via Large Language Models
Jan 07, 2025



Research on text simplification has primarily focused on lexical and sentence-level changes. Long document-level simplification (DS) is still relatively unexplored. Large Language Models (LLMs), like ChatGPT, have excelled in many natural language processing tasks. However, their performance on DS tasks is unsatisfactory, as they often treat DS as merely document summarization. For the DS task, the generated long sequences not only must maintain consistency with the original document throughout, but complete moderate simplification operations encompassing discourses, sentences, and word-level simplifications. Human editors employ a hierarchical complexity simplification strategy to simplify documents. This study delves into simulating this strategy through the utilization of a multi-stage collaboration using LLMs. We propose a progressive simplification method (ProgDS) by hierarchically decomposing the task, including the discourse-level, topic-level, and lexical-level simplification. Experimental results demonstrate that ProgDS significantly outperforms existing smaller models or direct prompting with LLMs, advancing the state-of-the-art in the document simplification task.