 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2LED: Equipping Retrieval and Refinement in Lifelong User Modeling with Semantic IDs for CTR Prediction
Feb 06, 2026Lifelong user modeling, which leverages users' long-term behavior sequences for CTR prediction, has been widely applied in personalized services. Existing methods generally adopted a two-stage "retrieval-refinement" strategy to balance effectiveness and efficiency. However, they still suffer from (i) noisy retrieval due to skewed data distribution and (ii) lack of semantic understanding in refinement. While semantic enhancement, e.g., LLMs modeling or semantic embeddings, offers potential solutions to these two challenges, these approaches face impractical inference costs or insufficient representation granularity. Obsorbing multi-granularity and lightness merits of semantic identity (SID), we propose a novel paradigm that equips retrieval and refinement in Lifelong User Modeling with SEmantic IDs (R2LED) to address these issues. First, we introduce a Multi-route Mixed Retrieval for the retrieval stage. On the one hand, it captures users' interests from various granularities by several parallel recall routes. On the other hand, a mixed retrieval mechanism is proposed to efficiently retrieve candidates from both collaborative and semantic views, reducing noise. Then, for refinement, we design a Bi-level Fusion Refinement, including a target-aware cross-attention for route-level fusion and a gate mechanism for SID-level fusion. It can bridge the gap between semantic and collaborative spaces, exerting the merits of SID. The comprehensive experimental results on two public datasets demonstrate the superiority of our method in both performance and efficiency. To facilitate the reproduction, we have released the code online https://github.com/abananbao/R2LED.
UrbanMoE: A Sparse Multi-Modal Mixture-of-Experts Framework for Multi-Task Urban Region Profiling
Jan 30, 2026Urban region profiling, the task of characterizing geographical areas, is crucial for urban planning and resource allocation. However, existing research in this domain faces two significant limitations. First, most methods are confined to single-task prediction, failing to capture the interconnected, multi-faceted nature of urban environments where numerous indicators are deeply correlated. Second, the field lacks a standardized experimental benchmark, which severely impedes fair comparison and reproducible progress. To address these challenges, we first establish a comprehensive benchmark for multi-task urban region profiling, featuring multi-modal features and a diverse set of strong baselines to ensure a fair and rigorous evaluation environment. Concurrently, we propose UrbanMoE, the first sparse multi-modal, multi-expert framework specifically architected to solve the multi-task challenge. Leveraging a sparse Mixture-of-Experts architecture, it dynamically routes multi-modal features to specialized sub-networks, enabling the simultaneous prediction of diverse urban indicators. We conduct extensive experiments on three real-world datasets within our benchmark, where UrbanMoE consistently demonstrates superior performance over all baselines. Further in-depth analysis validates the efficacy and efficiency of our approach, setting a new state-of-the-art and providing the community with a valuable tool for future research in urban analytics
FedDis: A Causal Disentanglement Framework for Federated Traffic Prediction
Jan 30, 2026Federated learning offers a promising paradigm for privacy-preserving traffic prediction, yet its performance is often challenged by the non-identically and independently distributed (non-IID) nature of decentralized traffic data. Existing federated methods frequently struggle with this data heterogeneity, typically entangling globally shared patterns with client-specific local dynamics within a single representation. In this work, we postulate that this heterogeneity stems from the entanglement of two distinct generative sources: client-specific localized dynamics and cross-client global spatial-temporal patterns. Motivated by this perspective, we introduce FedDis, a novel framework that, to the best of our knowledge, is the first to leverage causal disentanglement for federated spatial-temporal prediction. Architecturally, FedDis comprises a dual-branch design wherein a Personalized Bank learns to capture client-specific factors, while a Global Pattern Bank distills common knowledge. This separation enables robust cross-client knowledge transfer while preserving high adaptability to unique local environments. Crucially, a mutual information minimization objective is employed to enforce informational orthogonality between the two branches, thereby ensuring effective disentanglement. Comprehensive experiments conducted on four real-world benchmark datasets demonstrate that FedDis consistently achieves state-of-the-art performance, promising efficiency, and superior expandability.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
TreeWriter: AI-Assisted Hierarchical Planning and Writing for Long-Form Documents
Jan 19, 2026Long documents pose many challenges to current intelligent writing systems. These include maintaining consistency across sections, sustaining efficient planning and writing as documents become more complex, and effectively providing and integrating AI assistance to the user. Existing AI co-writing tools offer either inline suggestions or limited structured planning, but rarely support the entire writing process that begins with high-level ideas and ends with polished prose, in which many layers of planning and outlining are needed. Here, we introduce TreeWriter, a hierarchical writing system that represents documents as trees and integrates contextual AI support. TreeWriter allows authors to create, save, and refine document outlines at multiple levels, facilitating drafting, understanding, and iterative editing of long documents. A built-in AI agent can dynamically load relevant content, navigate the document hierarchy, and provide context-aware editing suggestions. A within-subject study (N=12) comparing TreeWriter with Google Docs + Gemini on long-document editing and creative writing tasks shows that TreeWriter improves idea exploration/development, AI helpfulness, and perceived authorial control. A two-month field deployment (N=8) further demonstrated that hierarchical organization supports collaborative writing. Our findings highlight the potential of hierarchical, tree-structured editors with integrated AI support and provide design guidelines for future AI-assisted writing tools that balance automation with user agency.
Exploring Recommender System Evaluation: A Multi-Modal User Agent Framework for A/B Testing
Jan 08, 2026In recommender systems, online A/B testing is a crucial method for evaluating the performance of different models. However, conducting online A/B testing often presents significant challenges, including substantial economic costs, user experience degradation, and considerable time requirements. With the Large Language Models' powerful capacity, LLM-based agent shows great potential to replace traditional online A/B testing. Nonetheless, current agents fail to simulate the perception process and interaction patterns, due to the lack of real environments and visual perception capability. To address these challenges, we introduce a multi-modal user agent for A/B testing (A/B Agent). Specifically, we construct a recommendation sandbox environment for A/B testing, enabling multimodal and multi-page interactions that align with real user behavior on online platforms. The designed agent leverages multimodal information perception, fine-grained user preferences, and integrates profiles, action memory retrieval, and a fatigue system to simulate complex human decision-making. We validated the potential of the agent as an alternative to traditional A/B testing from three perspectives: model, data, and features. Furthermore, we found that the data generated by A/B Agent can effectively enhance the capabilities of recommendation models. Our code is publicly available at https://github.com/Applied-Machine-Learning-Lab/ABAgent.
The Best of the Two Worlds: Harmonizing Semantic and Hash IDs for Sequential Recommendation
Dec 11, 2025Conventional Sequential Recommender Systems (SRS) typically assign unique Hash IDs (HID) to construct item embeddings. These HID embeddings effectively learn collaborative information from historical user-item interactions, making them vulnerable to situations where most items are rarely consumed (the long-tail problem). Recent methods that incorporate auxiliary information often suffer from noisy collaborative sharing caused by co-occurrence signals or semantic homogeneity caused by flat dense embeddings. Semantic IDs (SIDs), with their capability of code sharing and multi-granular semantic modeling, provide a promising alternative. However, the collaborative overwhelming phenomenon hinders the further development of SID-based methods. The quantization mechanisms commonly compromise the uniqueness of identifiers required for modeling head items, creating a performance seesaw between head and tail items. To address this dilemma, we propose \textbf{\name}, a novel framework that harmonizes the SID and HID. Specifically, we devise a dual-branch modeling architecture that enables the model to capture both the multi-granular semantics within SID while preserving the unique collaborative identity of HID. Furthermore, we introduce a dual-level alignment strategy that bridges the two representations, facilitating knowledge transfer and supporting robust preference modeling. Extensive experiments on three real-world datasets show that \name~ effectively balances recommendation quality for both head and tail items while surpassing the existing baselines. The implementation code can be found online\footnote{https://github.com/ziwliu8/H2Rec}.
Breaking the Passive Learning Trap: An Active Perception Strategy for Human Motion Prediction
Nov 18, 2025Forecasting 3D human motion is an important embodiment of fine-grained understanding and cognition of human behavior by artificial agents. Current approaches excessively rely on implicit network modeling of spatiotemporal relationships and motion characteristics, falling into the passive learning trap that results in redundant and monotonous 3D coordinate information acquisition while lacking actively guided explicit learning mechanisms. To overcome these issues, we propose an Active Perceptual Strategy (APS) for human motion prediction, leveraging quotient space representations to explicitly encode motion properties while introducing auxiliary learning objectives to strengthen spatio-temporal modeling. Specifically, we first design a data perception module that projects poses into the quotient space, decoupling motion geometry from coordinate redundancy. By jointly encoding tangent vectors and Grassmann projections, this module simultaneously achieves geometric dimension reduction, semantic decoupling, and dynamic constraint enforcement for effective motion pose characterization. Furthermore, we introduce a network perception module that actively learns spatio-temporal dependencies through restorative learning. This module deliberately masks specific joints or injects noise to construct auxiliary supervision signals. A dedicated auxiliary learning network is designed to actively adapt and learn from perturbed information. Notably, APS is model agnostic and can be integrated with different prediction models to enhance active perceptual. The experimental results demonstrate that our method achieves the new state-of-the-art, outperforming existing methods by large margins: 16.3% on H3.6M, 13.9% on CMU Mocap, and 10.1% on 3DPW.
HyperD: Hybrid Periodicity Decoupling Framework for Traffic Forecasting
Nov 16, 2025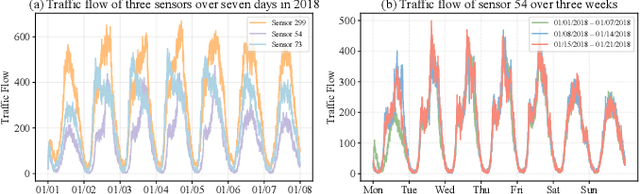
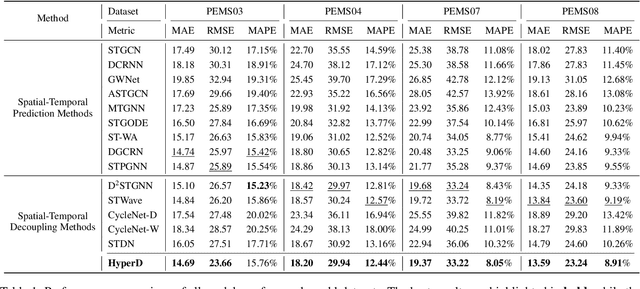
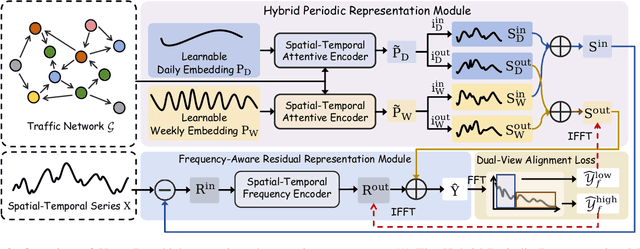
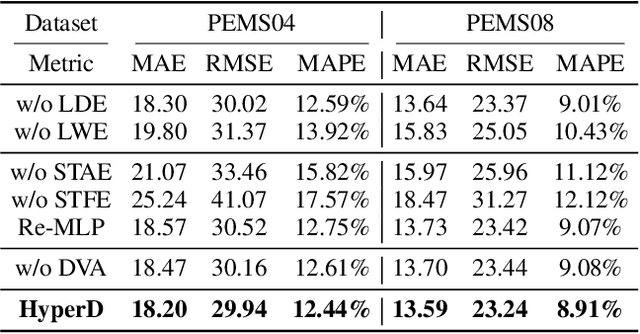
Accurate traffic forecasting plays a vital role in intelligent transportation systems, enabling applications such as congestion control, route planning, and urban mobility optimization. However, traffic forecasting remains challenging due to two key factors: (1) complex spatial dependencies arising from dynamic interactions between road segments and traffic sensors across the network, and (2) the coexistence of multi-scale periodic patterns (e.g., daily and weekly periodic patterns driven by human routines) with irregular fluctuations caused by unpredictable events (e.g., accidents, weather, or construction). To tackle these challenges, we propose HyperD (Hybrid Periodic Decoupling), a novel framework that decouples traffic data into periodic and residual components. The periodic component is handled by the Hybrid Periodic Representation Module, which extracts fine-grained daily and weekly patterns using learnable periodic embeddings and spatial-temporal attention. The residual component, which captures non-periodic, high-frequency fluctuations, is modeled by the Frequency-Aware Residual Representation Module, leveraging complex-valued MLP in frequency domain. To enforce semantic separation between the two components, we further introduce a Dual-View Alignment Loss, which aligns low-frequency information with the periodic branch and high-frequency information with the residual branch. Extensive experiments on four real-world traffic datasets demonstrate that HyperD achieves state-of-the-art prediction accuracy, while offering superior robustness under disturbances and improved computational efficiency compared to existing methods.
Boosting Fine-Grained Urban Flow Inference via Lightweight Architecture and Focalized Optimization
Nov 10, 2025Fine-grained urban flow inference is crucial for urban planning and intelligent transportation systems, enabling precise traffic management and resource allocation. However, the practical deployment of existing methods is hindered by two key challenges: the prohibitive computational cost of over-parameterized models and the suboptimal performance of conventional loss functions on the highly skewed distribution of urban flows. To address these challenges, we propose a unified solution that synergizes architectural efficiency with adaptive optimization. Specifically, we first introduce PLGF, a lightweight yet powerful architecture that employs a Progressive Local-Global Fusion strategy to effectively capture both fine-grained details and global contextual dependencies. Second, we propose DualFocal Loss, a novel function that integrates dual-space supervision with a difficulty-aware focusing mechanism, enabling the model to adaptively concentrate on hard-to-predict regions. Extensive experiments on 4 real-world scenarios validate the effectiveness and scalability of our method. Notably, while achieving state-of-the-art performance, PLGF reduces the model size by up to 97% compared to current high-performing methods. Furthermore, under comparable parameter budgets, our model yields an accuracy improvement of over 10% against strong baselines. The implementation is included in the https://github.com/Yasoz/PLGF.