 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProteinOPD: Towards Effective and Efficient Preference Alignment for Protein Design
May 11, 2026Designing proteins with desired functions or properties represents a core goal in synthetic biology and drug discovery. Recent advances in protein language models (PLMs) have enabled the generation of highly designable protein sequences, while preference alignment provides a promising way to steer designs toward desired functions and properties. Nevertheless, they often trigger catastrophic forgetting of pretrained knowledge, degrading basic designability and failing to balance multiple competing objectives. To address these issues, we draw inspiration from On-Policy Distillation (OPD), an advanced post-training method renowned for mitigating catastrophic forgetting through its mode-seeking nature. In this work, we propose ProteinOPD, a multi-objective preference alignment framework that can effectively balance multiple preference objectives while maintaining the inherent designability of PLMs. ProteinOPD adapts a pretrained PLM into preference-specific teachers and distills their knowledge into a shared student via token-level OPD on the student's own trajectories. During this process, the student is aligned to a unique normalized geometric consensus of weighted teachers while ensuring bounded optimization under conflicts. This bridges the gap for OPD in multi-objective/teacher alignment. Extensive experiments show that ProteinOPD achieves substantial gains on target preference objectives without compromising the designability, with an 8x training speedup over RL-based alignment competitors.
WeaveTime: Stream from Earlier Frames into Emergent Memory in VideoLLMs
Feb 25, 2026Recent advances in Multimodal Large Language Models have greatly improved visual understanding and reasoning, yet their quadratic attention and offline training protocols make them ill-suited for streaming settings where frames arrive sequentially and future observations are inaccessible. We diagnose a core limitation of current Video-LLMs, namely Time-Agnosticism, in which videos are treated as an unordered bag of evidence rather than a causally ordered sequence, yielding two failures in streams: temporal order ambiguity, in which the model cannot follow or reason over the correct chronological order, and past-current focus blindness where it fails to distinguish present observations from accumulated history. We present WeaveTime, a simple, efficient, and model agnostic framework that first teaches order and then uses order. We introduce a lightweight Temporal Reconstruction objective-our Streaming Order Perception enhancement-that instills order aware representations with minimal finetuning and no specialized streaming data. At inference, a Past-Current Dynamic Focus Cache performs uncertainty triggered, coarse-to-fine retrieval, expanding history only when needed. Plugged into exsiting Video-LLM without architectural changes, WeaveTime delivers consistent gains on representative streaming benchmarks, improving accuracy while reducing latency. These results establish WeaveTime as a practical path toward time aware stream Video-LLMs under strict online, time causal constraints. Code and weights will be made publicly available. Project Page: https://zhangyl4.github.io/publications/weavetime/
FedDis: A Causal Disentanglement Framework for Federated Traffic Prediction
Jan 30, 2026Federated learning offers a promising paradigm for privacy-preserving traffic prediction, yet its performance is often challenged by the non-identically and independently distributed (non-IID) nature of decentralized traffic data. Existing federated methods frequently struggle with this data heterogeneity, typically entangling globally shared patterns with client-specific local dynamics within a single representation. In this work, we postulate that this heterogeneity stems from the entanglement of two distinct generative sources: client-specific localized dynamics and cross-client global spatial-temporal patterns. Motivated by this perspective, we introduce FedDis, a novel framework that, to the best of our knowledge, is the first to leverage causal disentanglement for federated spatial-temporal prediction. Architecturally, FedDis comprises a dual-branch design wherein a Personalized Bank learns to capture client-specific factors, while a Global Pattern Bank distills common knowledge. This separation enables robust cross-client knowledge transfer while preserving high adaptability to unique local environments. Crucially, a mutual information minimization objective is employed to enforce informational orthogonality between the two branches, thereby ensuring effective disentanglement. Comprehensive experiments conducted on four real-world benchmark datasets demonstrate that FedDis consistently achieves state-of-the-art performance, promising efficiency, and superior expandability.
Variation Bayesian Interference for Multiple Extended Targets or Unresolved Group Targets Tracking
Jul 21, 2024



In this work, we propose a tracking method for multiple extended targets or unresolvable group targets based on the Variational Bayesian Inference (VBI). Firstly, based on the most commonly used Random Matrix Model (RMM), the joint states of a single target are modeled as a Gamma Gaussian Inverse Wishart (GGIW) distribution, and the multi-target joint association variables are involved in the estimation together as unknown information with a prior distribution. A shape evolution model and VBI are employed to address the shortcomings of the RMM. Through the VBI, we can derive the approximate variational posterior for the exact multi-target posterior. Furthermore, to demonstrate the applicability of the method in real-world tracking scenarios, we present two potential lightweight schemes. The first is based on clustering, which effectively prunes the joint association events. The second is a simplification of the variational posterior through marginal association probabilities. We demonstrate the effectiveness of the proposed method using simulation experiments, and the proposed method outperforms current state-of-the-art methods in terms of accuracy and adaptability. This manuscript is only a preprint version, a completer and more official version will be uploaded as soon as possible
Part2Object: Hierarchical Unsupervised 3D Instance Segmentation
Jul 14, 2024



Unsupervised 3D instance segmentation aims to segment objects from a 3D point cloud without any annotations. Existing methods face the challenge of either too loose or too tight clustering, leading to under-segmentation or over-segmentation. To address this issue, we propose Part2Object, hierarchical clustering with object guidance. Part2Object employs multi-layer clustering from points to object parts and objects, allowing objects to manifest at any layer. Additionally, it extracts and utilizes 3D objectness priors from temporally consecutive 2D RGB frames to guide the clustering process. Moreover, we propose Hi-Mask3D to support hierarchical 3D object part and instance segmentation. By training Hi-Mask3D on the objects and object parts extracted from Part2Object, we achieve consistent and superior performance compared to state-of-the-art models in various settings, including unsupervised instance segmentation, data-efficient fine-tuning, and cross-dataset generalization. Code is release at https://github.com/ChengShiest/Part2Object
An abstract theory of sensor eventification
Jun 30, 2024Unlike traditional cameras, event cameras measure changes in light intensity and report differences. This paper examines the conditions necessary for other traditional sensors to admit eventified versions that provide adequate information despite outputting only changes. The requirements depend upon the regularity of the signal space, which we show may depend on several factors including structure arising from the interplay of the robot and its environment, the input-output computation needed to achieve its task, as well as the specific mode of access (synchronous, asynchronous, polled, triggered). Further, there are additional properties of stability (or non-oscillatory behavior) that can be desirable for a system to possess and that we show are also closely related to the preceding notions. This paper contributes theory and algorithms (plus a hardness result) that addresses these considerations while developing several elementary robot examples along the way.
* 21 pages, 14 figures
A fixed-parameter tractable algorithm for combinatorial filter reduction
Sep 22, 2023What is the minimal information that a robot must retain to achieve its task? To design economical robots, the literature dealing with reduction of combinatorial filters approaches this problem algorithmically. As lossless state compression is NP-hard, prior work has examined, along with minimization algorithms, a variety of special cases in which specific properties enable efficient solution. Complementing those findings, this paper refines the present understanding from the perspective of parameterized complexity. We give a fixed-parameter tractable algorithm for the general reduction problem by exploiting a transformation into minimal clique covering. The transformation introduces new constraints that arise from sequential dependencies encoded within the input filter -- some of these constraints can be repaired, others are treated through enumeration. Through this approach, we identify parameters affecting filter reduction that are based upon inter-constraint couplings (expressed as a notion of their height and width), which add to the structural parameters present in the unconstrained problem of minimal clique covering.
A general class of combinatorial filters that can be minimized efficiently
Sep 10, 2022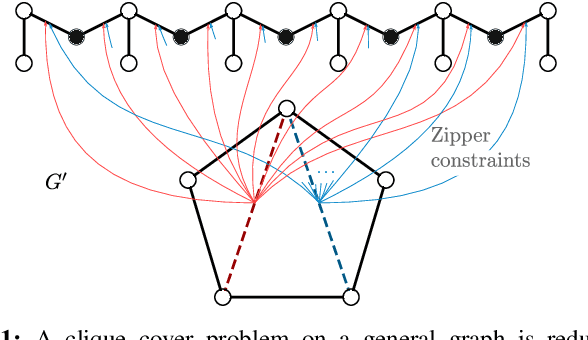
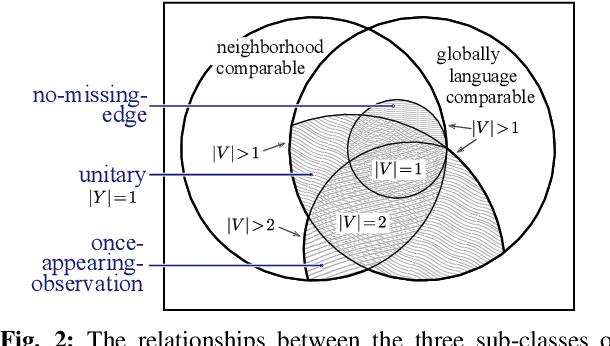
State minimization of combinatorial filters is a fundamental problem that arises, for example, in building cheap, resource-efficient robots. But exact minimization is known to be NP-hard. This paper conducts a more nuanced analysis of this hardness than up till now, and uncovers two factors which contribute to this complexity. We show each factor is a distinct source of the problem's hardness and are able, thereby, to shed some light on the role played by (1) structure of the graph that encodes compatibility relationships, and (2) determinism-enforcing constraints. Just as a line of prior work has sought to introduce additional assumptions and identify sub-classes that lead to practical state reduction, we next use this new, sharper understanding to explore special cases for which exact minimization is efficient. We introduce a new algorithm for constraint repair that applies to a large sub-class of filters, subsuming three distinct special cases for which the possibility of optimal minimization in polynomial time was known earlier. While the efficiency in each of these three cases appeared, previously, to stem from seemingly dissimilar properties, when seen through the lens of the present work, their commonality now becomes clear. We also provide entirely new families of filters that are efficiently reducible.
Nondeterminism subject to output commitment in combinatorial filters
Apr 01, 2022
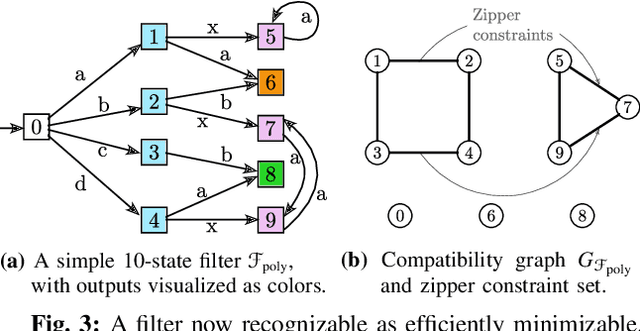
We study a class of filters -- discrete finite-state transition systems employed as incremental stream transducers -- that have application to robotics: e.g., to model combinatorial estimators and also as concise encodings of feedback plans/policies. The present paper examines their minimization problem under some new assumptions. Compared to strictly deterministic filters, allowing nondeterminism supplies opportunities for compression via re-use of states. But this paper suggests that the classic automata-theoretic concept of nondeterminism, though it affords said opportunities for reduction in state complexity, is problematic in many robotics settings. Instead, we argue for a new constrained type of nondeterminism that preserves input-output behavior for circumstances when, as for robots, causation forbids 'rewinding' of the world. We identify problem instances where compression under this constrained form of nondeterminism results in improvements over all deterministic filters. In this new setting, we examine computational complexity questions for the problem of reducing the state complexity of some given input filter. A hardness result for general deterministic input filters is presented, as well as for checking specific, narrower requirements, and some special cases. These results show that this class of nondeterminism gives problems of the same complexity class as classical nondeterminism, and the narrower questions help give a more nuanced understanding of the source of this complexity.
Learning a Robust Multiagent Driving Policy for Traffic Congestion Reduction
Dec 03, 2021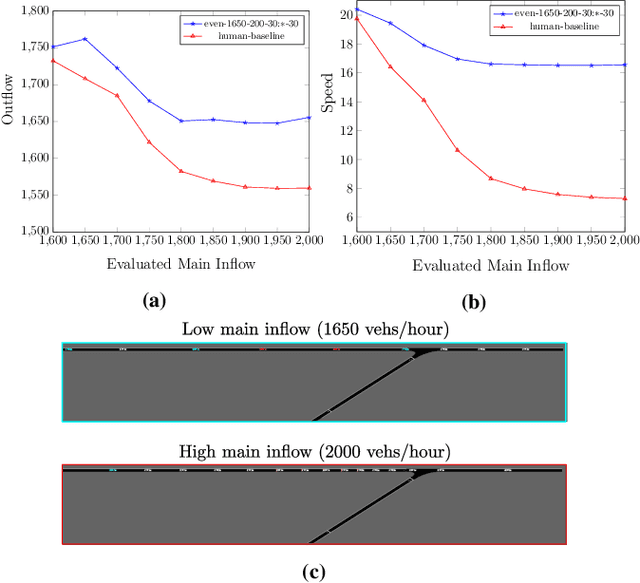
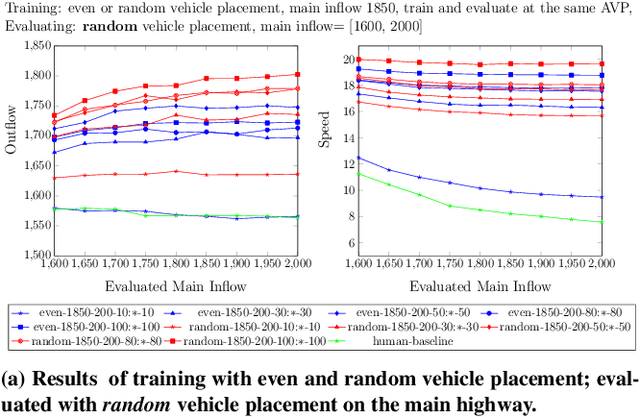

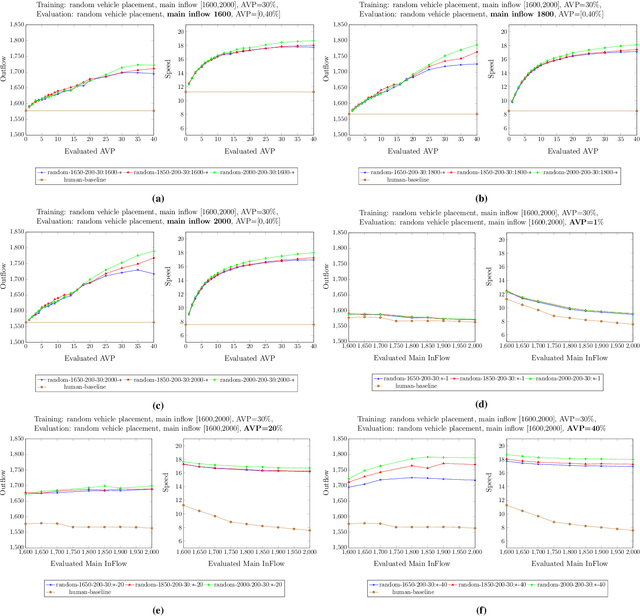
The advent of automated and autonomous vehicles (AVs) creates opportunities to achieve system-level goals using multiple AVs, such as traffic congestion reduction. Past research has shown that multiagent congestion-reducing driving policies can be learned in a variety of simulated scenarios. While initial proofs of concept were in small, closed traffic networks with a centralized controller, recently successful results have been demonstrated in more realistic settings with distributed control policies operating in open road networks where vehicles enter and leave. However, these driving policies were mostly tested under the same conditions they were trained on, and have not been thoroughly tested for robustness to different traffic conditions, which is a critical requirement in real-world scenarios. This paper presents a learned multiagent driving policy that is robust to a variety of open-network traffic conditions, including vehicle flows, the fraction of AVs in traffic, AV placement, and different merging road geometries. A thorough empirical analysis investigates the sensitivity of such a policy to the amount of AVs in both a simple merge network and a more complex road with two merging ramps. It shows that the learned policy achieves significant improvement over simulated human-driven policies even with AV penetration as low as 2%. The same policy is also shown to be capable of reducing traffic congestion in more complex roads with two merging ramps.