 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
HyperD: Hybrid Periodicity Decoupling Framework for Traffic Forecasting
Nov 16, 2025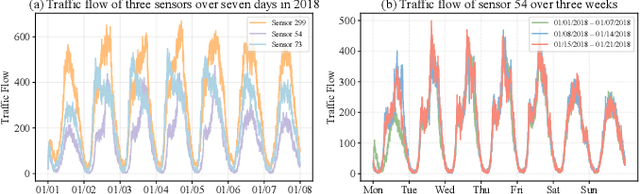
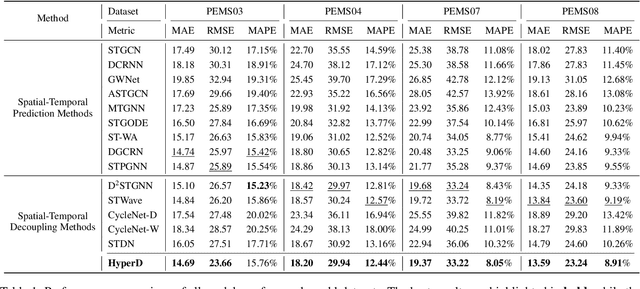
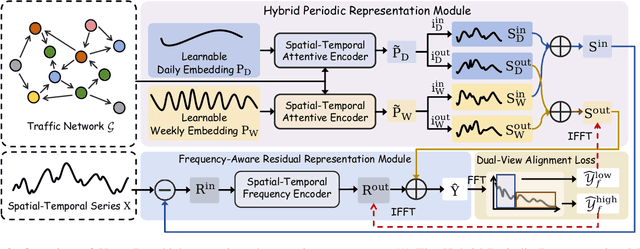
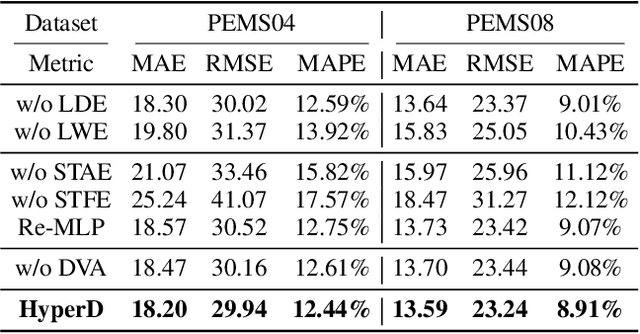
Accurate traffic forecasting plays a vital role in intelligent transportation systems, enabling applications such as congestion control, route planning, and urban mobility optimization. However, traffic forecasting remains challenging due to two key factors: (1) complex spatial dependencies arising from dynamic interactions between road segments and traffic sensors across the network, and (2) the coexistence of multi-scale periodic patterns (e.g., daily and weekly periodic patterns driven by human routines) with irregular fluctuations caused by unpredictable events (e.g., accidents, weather, or construction). To tackle these challenges, we propose HyperD (Hybrid Periodic Decoupling), a novel framework that decouples traffic data into periodic and residual components. The periodic component is handled by the Hybrid Periodic Representation Module, which extracts fine-grained daily and weekly patterns using learnable periodic embeddings and spatial-temporal attention. The residual component, which captures non-periodic, high-frequency fluctuations, is modeled by the Frequency-Aware Residual Representation Module, leveraging complex-valued MLP in frequency domain. To enforce semantic separation between the two components, we further introduce a Dual-View Alignment Loss, which aligns low-frequency information with the periodic branch and high-frequency information with the residual branch. Extensive experiments on four real-world traffic datasets demonstrate that HyperD achieves state-of-the-art prediction accuracy, while offering superior robustness under disturbances and improved computational efficiency compared to existing methods.
Dual Mamba for Node-Specific Representation Learning: Tackling Over-Smoothing with Selective State Space Modeling
Nov 11, 2025Over-smoothing remains a fundamental challenge in deep Graph Neural Networks (GNNs), where repeated message passing causes node representations to become indistinguishable. While existing solutions, such as residual connections and skip layers, alleviate this issue to some extent, they fail to explicitly model how node representations evolve in a node-specific and progressive manner across layers. Moreover, these methods do not take global information into account, which is also crucial for mitigating the over-smoothing problem. To address the aforementioned issues, in this work, we propose a Dual Mamba-enhanced Graph Convolutional Network (DMbaGCN), which is a novel framework that integrates Mamba into GNNs to address over-smoothing from both local and global perspectives. DMbaGCN consists of two modules: the Local State-Evolution Mamba (LSEMba) for local neighborhood aggregation and utilizing Mamba's selective state space modeling to capture node-specific representation dynamics across layers, and the Global Context-Aware Mamba (GCAMba) that leverages Mamba's global attention capabilities to incorporate global context for each node. By combining these components, DMbaGCN enhances node discriminability in deep GNNs, thereby mitigating over-smoothing. Extensive experiments on multiple benchmarks demonstrate the effectiveness and efficiency of our method.
BlindGuard: Safeguarding LLM-based Multi-Agent Systems under Unknown Attacks
Aug 11, 2025The security of LLM-based multi-agent systems (MAS) is critically threatened by propagation vulnerability, where malicious agents can distort collective decision-making through inter-agent message interactions. While existing supervised defense methods demonstrate promising performance, they may be impractical in real-world scenarios due to their heavy reliance on labeled malicious agents to train a supervised malicious detection model. To enable practical and generalizable MAS defenses, in this paper, we propose BlindGuard, an unsupervised defense method that learns without requiring any attack-specific labels or prior knowledge of malicious behaviors. To this end, we establish a hierarchical agent encoder to capture individual, neighborhood, and global interaction patterns of each agent, providing a comprehensive understanding for malicious agent detection. Meanwhile, we design a corruption-guided detector that consists of directional noise injection and contrastive learning, allowing effective detection model training solely on normal agent behaviors. Extensive experiments show that BlindGuard effectively detects diverse attack types (i.e., prompt injection, memory poisoning, and tool attack) across MAS with various communication patterns while maintaining superior generalizability compared to supervised baselines. The code is available at: https://github.com/MR9812/BlindGuard.
Understanding the Information Propagation Effects of Communication Topologies in LLM-based Multi-Agent Systems
May 29, 2025The communication topology in large language model-based multi-agent systems fundamentally governs inter-agent collaboration patterns, critically shaping both the efficiency and effectiveness of collective decision-making. While recent studies for communication topology automated design tend to construct sparse structures for efficiency, they often overlook why and when sparse and dense topologies help or hinder collaboration. In this paper, we present a causal framework to analyze how agent outputs, whether correct or erroneous, propagate under topologies with varying sparsity. Our empirical studies reveal that moderately sparse topologies, which effectively suppress error propagation while preserving beneficial information diffusion, typically achieve optimal task performance. Guided by this insight, we propose a novel topology design approach, EIB-leanrner, that balances error suppression and beneficial information propagation by fusing connectivity patterns from both dense and sparse graphs. Extensive experiments show the superior effectiveness, communication cost, and robustness of EIB-leanrner.
Latte: Transfering LLMs` Latent-level Knowledge for Few-shot Tabular Learning
May 08, 2025



Few-shot tabular learning, in which machine learning models are trained with a limited amount of labeled data, provides a cost-effective approach to addressing real-world challenges. The advent of Large Language Models (LLMs) has sparked interest in leveraging their pre-trained knowledge for few-shot tabular learning. Despite promising results, existing approaches either rely on test-time knowledge extraction, which introduces undesirable latency, or text-level knowledge, which leads to unreliable feature engineering. To overcome these limitations, we propose Latte, a training-time knowledge extraction framework that transfers the latent prior knowledge within LLMs to optimize a more generalized downstream model. Latte enables general knowledge-guided downstream tabular learning, facilitating the weighted fusion of information across different feature values while reducing the risk of overfitting to limited labeled data. Furthermore, Latte is compatible with existing unsupervised pre-training paradigms and effectively utilizes available unlabeled samples to overcome the performance limitations imposed by an extremely small labeled dataset. Extensive experiments on various few-shot tabular learning benchmarks demonstrate the superior performance of Latte, establishing it as a state-of-the-art approach in this domain