 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyMoE: Leveraging Modal Asymmetry for Enhanced Expert Specialization in Large Vision-Language Models
Sep 16, 2025Large Vision-Language Models (LVLMs) have demonstrated impressive performance on multimodal tasks through scaled architectures and extensive training. However, existing Mixture of Experts (MoE) approaches face challenges due to the asymmetry between visual and linguistic processing. Visual information is spatially complete, while language requires maintaining sequential context. As a result, MoE models struggle to balance modality-specific features and cross-modal interactions. Through systematic analysis, we observe that language experts in deeper layers progressively lose contextual grounding and rely more on parametric knowledge rather than utilizing the provided visual and linguistic information. To address this, we propose AsyMoE, a novel architecture that models this asymmetry using three specialized expert groups. We design intra-modality experts for modality-specific processing, hyperbolic inter-modality experts for hierarchical cross-modal interactions, and evidence-priority language experts to suppress parametric biases and maintain contextual grounding. Extensive experiments demonstrate that AsyMoE achieves 26.58% and 15.45% accuracy improvements over vanilla MoE and modality-specific MoE respectively, with 25.45% fewer activated parameters than dense models.
SPJFNet: Self-Mining Prior-Guided Joint Frequency Enhancement for Ultra-Efficient Dark Image Restoration
Aug 06, 2025Current dark image restoration methods suffer from severe efficiency bottlenecks, primarily stemming from: (1) computational burden and error correction costs associated with reliance on external priors (manual or cross-modal); (2) redundant operations in complex multi-stage enhancement pipelines; and (3) indiscriminate processing across frequency components in frequency-domain methods, leading to excessive global computational demands. To address these challenges, we propose an Efficient Self-Mining Prior-Guided Joint Frequency Enhancement Network (SPJFNet). Specifically, we first introduce a Self-Mining Guidance Module (SMGM) that generates lightweight endogenous guidance directly from the network, eliminating dependence on external priors and thereby bypassing error correction overhead while improving inference speed. Second, through meticulous analysis of different frequency domain characteristics, we reconstruct and compress multi-level operation chains into a single efficient operation via lossless wavelet decomposition and joint Fourier-based advantageous frequency enhancement, significantly reducing parameters. Building upon this foundation, we propose a Dual-Frequency Guidance Framework (DFGF) that strategically deploys specialized high/low frequency branches (wavelet-domain high-frequency enhancement and Fourier-domain low-frequency restoration), decoupling frequency processing to substantially reduce computational complexity. Rigorous evaluation across multiple benchmarks demonstrates that SPJFNet not only surpasses state-of-the-art performance but also achieves significant efficiency improvements, substantially reducing model complexity and computational overhead. Code is available at https://github.com/bywlzts/SPJFNet.
HKD4VLM: A Progressive Hybrid Knowledge Distillation Framework for Robust Multimodal Hallucination and Factuality Detection in VLMs
Jun 16, 2025Driven by the rapid progress in vision-language models (VLMs), the responsible behavior of large-scale multimodal models has become a prominent research area, particularly focusing on hallucination detection and factuality checking. In this paper, we present the solution for the two tracks of Responsible AI challenge. Inspirations from the general domain demonstrate that a smaller distilled VLM can often outperform a larger VLM that is directly tuned on downstream tasks, while achieving higher efficiency. We thus jointly tackle two tasks from the perspective of knowledge distillation and propose a progressive hybrid knowledge distillation framework termed HKD4VLM. Specifically, the overall framework can be decomposed into Pyramid-like Progressive Online Distillation and Ternary-Coupled Refinement Distillation, hierarchically moving from coarse-grained knowledge alignment to fine-grained refinement. Besides, we further introduce the mapping shift-enhanced inference and diverse augmentation strategies to enhance model performance and robustness. Extensive experimental results demonstrate the effectiveness of our HKD4VLM. Ablation studies provide insights into the critical design choices driving performance gains.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Adaptive Plan-Execute Framework for Smart Contract Security Auditing
May 21, 2025Large Language Models (LLMs) have shown great promise in code analysis and auditing; however, they still struggle with hallucinations and limited context-aware reasoning. We introduce SmartAuditFlow, a novel Plan-Execute framework that enhances smart contract security analysis through dynamic audit planning and structured execution. Unlike conventional LLM-based auditing approaches that follow fixed workflows and predefined steps, SmartAuditFlow dynamically generates and refines audit plans based on the unique characteristics of each smart contract. It continuously adjusts its auditing strategy in response to intermediate LLM outputs and newly detected vulnerabilities, ensuring a more adaptive and precise security assessment. The framework then executes these plans step by step, applying a structured reasoning process to enhance vulnerability detection accuracy while minimizing hallucinations and false positives. To further improve audit precision, SmartAuditFlow integrates iterative prompt optimization and external knowledge sources, such as static analysis tools and Retrieval-Augmented Generation (RAG). This ensures audit decisions are contextually informed and backed by real-world security knowledge, producing comprehensive security reports. Extensive evaluations across multiple benchmarks demonstrate that SmartAuditFlow outperforms existing methods, achieving 100 percent accuracy on common and critical vulnerabilities, 41.2 percent accuracy for comprehensive coverage of known smart contract weaknesses in real-world projects, and successfully identifying all 13 tested CVEs. These results highlight SmartAuditFlow's scalability, cost-effectiveness, and superior adaptability over traditional static analysis tools and contemporary LLM-based approaches, establishing it as a robust solution for automated smart contract auditing.
InfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
May 16, 2025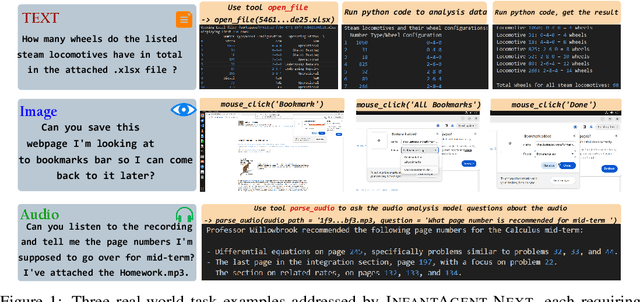

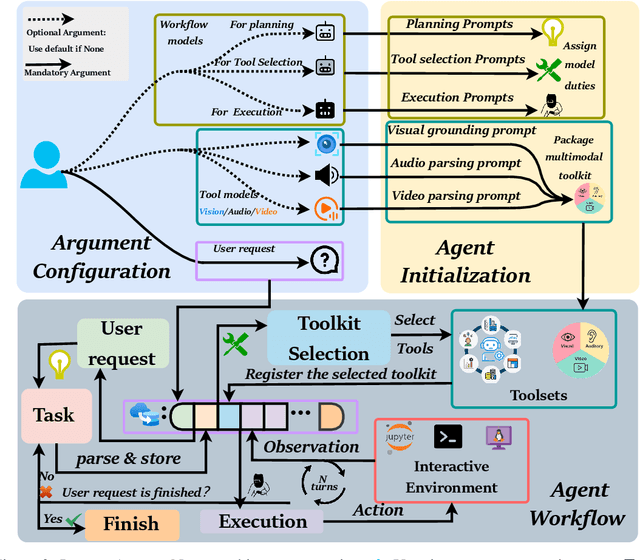
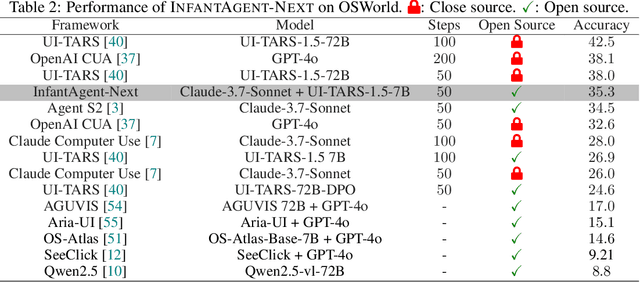
This paper introduces \textsc{InfantAgent-Next}, a generalist agent capable of interacting with computers in a multimodal manner, encompassing text, images, audio, and video. Unlike existing approaches that either build intricate workflows around a single large model or only provide workflow modularity, our agent integrates tool-based and pure vision agents within a highly modular architecture, enabling different models to collaboratively solve decoupled tasks in a step-by-step manner. Our generality is demonstrated by our ability to evaluate not only pure vision-based real-world benchmarks (i.e., OSWorld), but also more general or tool-intensive benchmarks (e.g., GAIA and SWE-Bench). Specifically, we achieve $\mathbf{7.27\%}$ accuracy on OSWorld, higher than Claude-Computer-Use. Codes and evaluation scripts are open-sourced at https://github.com/bin123apple/InfantAgent.
El Agente: An Autonomous Agent for Quantum Chemistry
May 05, 2025Computational chemistry tools are widely used to study the behaviour of chemical phenomena. Yet, the complexity of these tools can make them inaccessible to non-specialists and challenging even for experts. In this work, we introduce El Agente Q, an LLM-based multi-agent system that dynamically generates and executes quantum chemistry workflows from natural language user prompts. The system is built on a novel cognitive architecture featuring a hierarchical memory framework that enables flexible task decomposition, adaptive tool selection, post-analysis, and autonomous file handling and submission. El Agente Q is benchmarked on six university-level course exercises and two case studies, demonstrating robust problem-solving performance (averaging >87% task success) and adaptive error handling through in situ debugging. It also supports longer-term, multi-step task execution for more complex workflows, while maintaining transparency through detailed action trace logs. Together, these capabilities lay the foundation for increasingly autonomous and accessible quantum chemistry.
Anyprefer: An Agentic Framework for Preference Data Synthesis
Apr 27, 2025



High-quality preference data is essential for aligning foundation models with human values through preference learning. However, manual annotation of such data is often time-consuming and costly. Recent methods often adopt a self-rewarding approach, where the target model generates and annotates its own preference data, but this can lead to inaccuracies since the reward model shares weights with the target model, thereby amplifying inherent biases. To address these issues, we propose Anyprefer, a framework designed to synthesize high-quality preference data for aligning the target model. Anyprefer frames the data synthesis process as a cooperative two-player Markov Game, where the target model and the judge model collaborate together. Here, a series of external tools are introduced to assist the judge model in accurately rewarding the target model's responses, mitigating biases in the rewarding process. In addition, a feedback mechanism is introduced to optimize prompts for both models, enhancing collaboration and improving data quality. The synthesized data is compiled into a new preference dataset, Anyprefer-V1, consisting of 58K high-quality preference pairs. Extensive experiments show that Anyprefer significantly improves model alignment performance across four main applications, covering 21 datasets, achieving average improvements of 18.55% in five natural language generation datasets, 3.66% in nine vision-language understanding datasets, 30.05% in three medical image analysis datasets, and 16.00% in four visuo-motor control tasks.
Bridge the Domains: Large Language Models Enhanced Cross-domain Sequential Recommendation
Apr 25, 2025Cross-domain Sequential Recommendation (CDSR) aims to extract the preference from the user's historical interactions across various domains. Despite some progress in CDSR, two problems set the barrier for further advancements, i.e., overlap dilemma and transition complexity. The former means existing CDSR methods severely rely on users who own interactions on all domains to learn cross-domain item relationships, compromising the practicability. The latter refers to the difficulties in learning the complex transition patterns from the mixed behavior sequences. With powerful representation and reasoning abilities, Large Language Models (LLMs) are promising to address these two problems by bridging the items and capturing the user's preferences from a semantic view. Therefore, we propose an LLMs Enhanced Cross-domain Sequential Recommendation model (LLM4CDSR). To obtain the semantic item relationships, we first propose an LLM-based unified representation module to represent items. Then, a trainable adapter with contrastive regularization is designed to adapt the CDSR task. Besides, a hierarchical LLMs profiling module is designed to summarize user cross-domain preferences. Finally, these two modules are integrated into the proposed tri-thread framework to derive recommendations. We have conducted extensive experiments on three public cross-domain datasets, validating the effectiveness of LLM4CDSR. We have released the code online.
TokenFocus-VQA: Enhancing Text-to-Image Alignment with Position-Aware Focus and Multi-Perspective Aggregations on LVLMs
Apr 10, 2025While text-to-image (T2I) generation models have achieved remarkable progress in recent years, existing evaluation methodologies for vision-language alignment still struggle with the fine-grained semantic matching. Current approaches based on global similarity metrics often overlook critical token-level correspondences between textual descriptions and visual content. To this end, we present TokenFocus-VQA, a novel evaluation framework that leverages Large Vision-Language Models (LVLMs) through visual question answering (VQA) paradigm with position-specific probability optimization. Our key innovation lies in designing a token-aware loss function that selectively focuses on probability distributions at pre-defined vocabulary positions corresponding to crucial semantic elements, enabling precise measurement of fine-grained semantical alignment. The proposed framework further integrates ensemble learning techniques to aggregate multi-perspective assessments from diverse LVLMs architectures, thereby achieving further performance enhancement. Evaluated on the NTIRE 2025 T2I Quality Assessment Challenge Track 1, our TokenFocus-VQA ranks 2nd place (0.8445, only 0.0001 lower than the 1st method) on public evaluation and 2nd place (0.8426) on the official private test set, demonstrating superiority in capturing nuanced text-image correspondences compared to conventional evaluation methods.