 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIG-Diff: Complex Night Scene Restoration with Illumination-Guided Diffusion Model
May 14, 2026In nighttime circumstances, it is challenging for individuals and machines to perceive their surroundings. While prevailing image restoration methods adeptly handle singular forms of degradation, they falter when confronted with intricate nocturnal scenes, such as the concurrent presence of weather and low-light conditions. Compounding this challenge, the lack of paired data that encapsulates the coexistence of low-light situations and other forms of degradation hinders the development of a comprehensive end-to-end solution. In this work, we contribute complex nighttime scene datasets that simulate both illumination degradation and other forms of deterioration. To address the complexity of night degradation, we propose an integration of an illumination-guided module embedded in the diffusion model to guide the illumination restoration process. Our model can preserve texture fidelity while contending with the adversities posed by various degradation in low-light scenarios.
NTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
Infinite-World: Scaling Interactive World Models to 1000-Frame Horizons via Pose-Free Hierarchical Memory
Feb 03, 2026We propose Infinite-World, a robust interactive world model capable of maintaining coherent visual memory over 1000+ frames in complex real-world environments. While existing world models can be efficiently optimized on synthetic data with perfect ground-truth, they lack an effective training paradigm for real-world videos due to noisy pose estimations and the scarcity of viewpoint revisits. To bridge this gap, we first introduce a Hierarchical Pose-free Memory Compressor (HPMC) that recursively distills historical latents into a fixed-budget representation. By jointly optimizing the compressor with the generative backbone, HPMC enables the model to autonomously anchor generations in the distant past with bounded computational cost, eliminating the need for explicit geometric priors. Second, we propose an Uncertainty-aware Action Labeling module that discretizes continuous motion into a tri-state logic. This strategy maximizes the utilization of raw video data while shielding the deterministic action space from being corrupted by noisy trajectories, ensuring robust action-response learning. Furthermore, guided by insights from a pilot toy study, we employ a Revisit-Dense Finetuning Strategy using a compact, 30-minute dataset to efficiently activate the model's long-range loop-closure capabilities. Extensive experiments, including objective metrics and user studies, demonstrate that Infinite-World achieves superior performance in visual quality, action controllability, and spatial consistency.
ViDA-UGC: Detailed Image Quality Analysis via Visual Distortion Assessment for UGC Images
Aug 18, 2025Recent advances in Multimodal Large Language Models (MLLMs) have introduced a paradigm shift for Image Quality Assessment (IQA) from unexplainable image quality scoring to explainable IQA, demonstrating practical applications like quality control and optimization guidance. However, current explainable IQA methods not only inadequately use the same distortion criteria to evaluate both User-Generated Content (UGC) and AI-Generated Content (AIGC) images, but also lack detailed quality analysis for monitoring image quality and guiding image restoration. In this study, we establish the first large-scale Visual Distortion Assessment Instruction Tuning Dataset for UGC images, termed ViDA-UGC, which comprises 11K images with fine-grained quality grounding, detailed quality perception, and reasoning quality description data. This dataset is constructed through a distortion-oriented pipeline, which involves human subject annotation and a Chain-of-Thought (CoT) assessment framework. This framework guides GPT-4o to generate quality descriptions by identifying and analyzing UGC distortions, which helps capturing rich low-level visual features that inherently correlate with distortion patterns. Moreover, we carefully select 476 images with corresponding 6,149 question answer pairs from ViDA-UGC and invite a professional team to ensure the accuracy and quality of GPT-generated information. The selected and revised data further contribute to the first UGC distortion assessment benchmark, termed ViDA-UGC-Bench. Experimental results demonstrate the effectiveness of the ViDA-UGC and CoT framework for consistently enhancing various image quality analysis abilities across multiple base MLLMs on ViDA-UGC-Bench and Q-Bench, even surpassing GPT-4o.
Adaptive Blind Super-Resolution Network for Spatial-Specific and Spatial-Agnostic Degradations
Jun 09, 2025Prior methodologies have disregarded the diversities among distinct degradation types during image reconstruction, employing a uniform network model to handle multiple deteriorations. Nevertheless, we discover that prevalent degradation modalities, including sampling, blurring, and noise, can be roughly categorized into two classes. We classify the first class as spatial-agnostic dominant degradations, less affected by regional changes in image space, such as downsampling and noise degradation. The second class degradation type is intimately associated with the spatial position of the image, such as blurring, and we identify them as spatial-specific dominant degradations. We introduce a dynamic filter network integrating global and local branches to address these two degradation types. This network can greatly alleviate the practical degradation problem. Specifically, the global dynamic filtering layer can perceive the spatial-agnostic dominant degradation in different images by applying weights generated by the attention mechanism to multiple parallel standard convolution kernels, enhancing the network's representation ability. Meanwhile, the local dynamic filtering layer converts feature maps of the image into a spatially specific dynamic filtering operator, which performs spatially specific convolution operations on the image features to handle spatial-specific dominant degradations. By effectively integrating both global and local dynamic filtering operators, our proposed method outperforms state-of-the-art blind super-resolution algorithms in both synthetic and real image datasets.
Incorporating Uncertainty-Guided and Top-k Codebook Matching for Real-World Blind Image Super-Resolution
Jun 09, 2025Recent advancements in codebook-based real image super-resolution (SR) have shown promising results in real-world applications. The core idea involves matching high-quality image features from a codebook based on low-resolution (LR) image features. However, existing methods face two major challenges: inaccurate feature matching with the codebook and poor texture detail reconstruction. To address these issues, we propose a novel Uncertainty-Guided and Top-k Codebook Matching SR (UGTSR) framework, which incorporates three key components: (1) an uncertainty learning mechanism that guides the model to focus on texture-rich regions, (2) a Top-k feature matching strategy that enhances feature matching accuracy by fusing multiple candidate features, and (3) an Align-Attention module that enhances the alignment of information between LR and HR features. Experimental results demonstrate significant improvements in texture realism and reconstruction fidelity compared to existing methods. We will release the code upon formal publication.
A Systematic Investigation on Deep Learning-Based Omnidirectional Image and Video Super-Resolution
Jun 07, 2025Omnidirectional image and video super-resolution is a crucial research topic in low-level vision, playing an essential role in virtual reality and augmented reality applications. Its goal is to reconstruct high-resolution images or video frames from low-resolution inputs, thereby enhancing detail preservation and enabling more accurate scene analysis and interpretation. In recent years, numerous innovative and effective approaches have been proposed, predominantly based on deep learning techniques, involving diverse network architectures, loss functions, projection strategies, and training datasets. This paper presents a systematic review of recent progress in omnidirectional image and video super-resolution, focusing on deep learning-based methods. Given that existing datasets predominantly rely on synthetic degradation and fall short in capturing real-world distortions, we introduce a new dataset, 360Insta, that comprises authentically degraded omnidirectional images and videos collected under diverse conditions, including varying lighting, motion, and exposure settings. This dataset addresses a critical gap in current omnidirectional benchmarks and enables more robust evaluation of the generalization capabilities of omnidirectional super-resolution methods. We conduct comprehensive qualitative and quantitative evaluations of existing methods on both public datasets and our proposed dataset. Furthermore, we provide a systematic overview of the current status of research and discuss promising directions for future exploration. All datasets, methods, and evaluation metrics introduced in this work are publicly available and will be regularly updated. Project page: https://github.com/nqian1/Survey-on-ODISR-and-ODVSR.
3D-UIR: 3D Gaussian for Underwater 3D Scene Reconstruction via Physics Based Appearance-Medium Decoupling
May 29, 2025Novel view synthesis for underwater scene reconstruction presents unique challenges due to complex light-media interactions. Optical scattering and absorption in water body bring inhomogeneous medium attenuation interference that disrupts conventional volume rendering assumptions of uniform propagation medium. While 3D Gaussian Splatting (3DGS) offers real-time rendering capabilities, it struggles with underwater inhomogeneous environments where scattering media introduce artifacts and inconsistent appearance. In this study, we propose a physics-based framework that disentangles object appearance from water medium effects through tailored Gaussian modeling. Our approach introduces appearance embeddings, which are explicit medium representations for backscatter and attenuation, enhancing scene consistency. In addition, we propose a distance-guided optimization strategy that leverages pseudo-depth maps as supervision with depth regularization and scale penalty terms to improve geometric fidelity. By integrating the proposed appearance and medium modeling components via an underwater imaging model, our approach achieves both high-quality novel view synthesis and physically accurate scene restoration. Experiments demonstrate our significant improvements in rendering quality and restoration accuracy over existing methods. The project page is available at https://bilityniu.github.io/3D-UIR.
DIPO: Dual-State Images Controlled Articulated Object Generation Powered by Diverse Data
May 28, 2025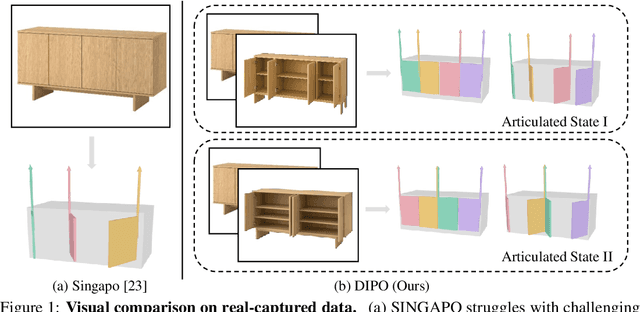
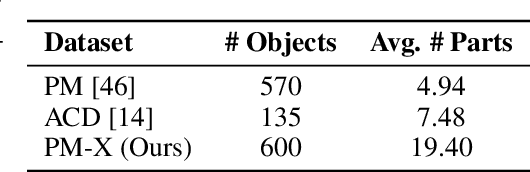
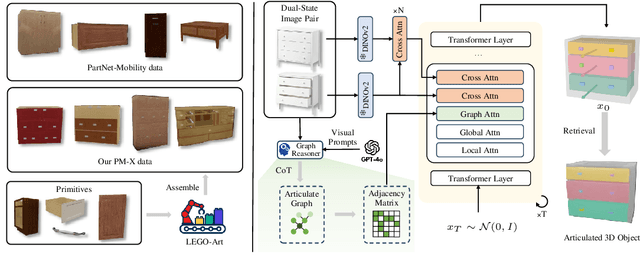
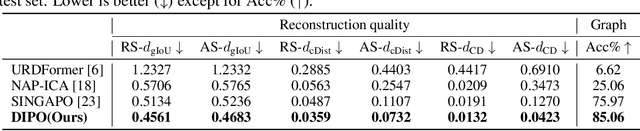
We present DIPO, a novel framework for the controllable generation of articulated 3D objects from a pair of images: one depicting the object in a resting state and the other in an articulated state. Compared to the single-image approach, our dual-image input imposes only a modest overhead for data collection, but at the same time provides important motion information, which is a reliable guide for predicting kinematic relationships between parts. Specifically, we propose a dual-image diffusion model that captures relationships between the image pair to generate part layouts and joint parameters. In addition, we introduce a Chain-of-Thought (CoT) based graph reasoner that explicitly infers part connectivity relationships. To further improve robustness and generalization on complex articulated objects, we develop a fully automated dataset expansion pipeline, name LEGO-Art, that enriches the diversity and complexity of PartNet-Mobility dataset. We propose PM-X, a large-scale dataset of complex articulated 3D objects, accompanied by rendered images, URDF annotations, and textual descriptions. Extensive experiments demonstrate that DIPO significantly outperforms existing baselines in both the resting state and the articulated state, while the proposed PM-X dataset further enhances generalization to diverse and structurally complex articulated objects. Our code and dataset will be released to the community upon publication.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.