 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
May 16, 2025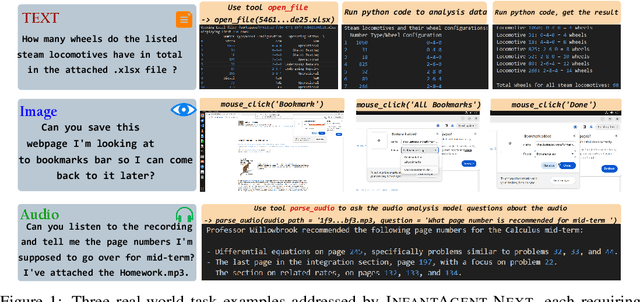

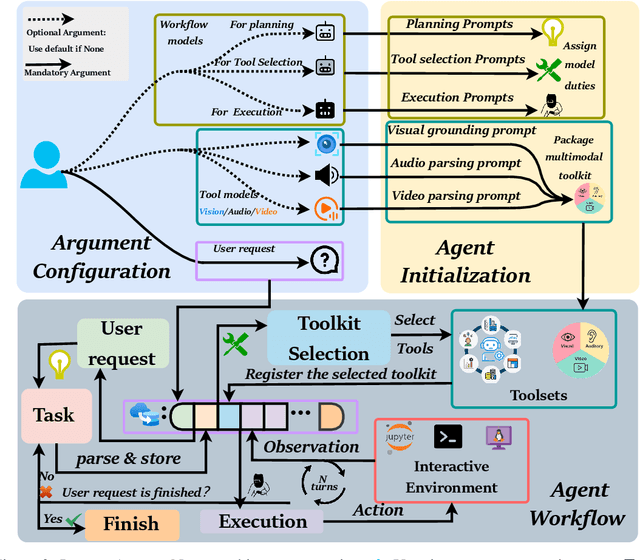
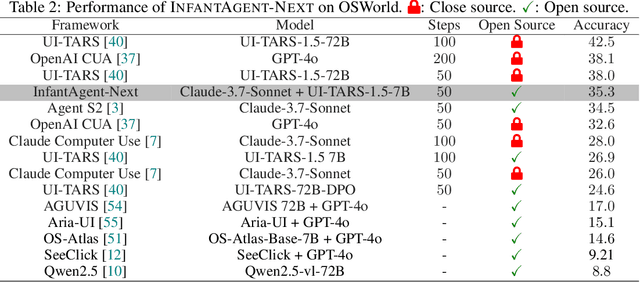
This paper introduces \textsc{InfantAgent-Next}, a generalist agent capable of interacting with computers in a multimodal manner, encompassing text, images, audio, and video. Unlike existing approaches that either build intricate workflows around a single large model or only provide workflow modularity, our agent integrates tool-based and pure vision agents within a highly modular architecture, enabling different models to collaboratively solve decoupled tasks in a step-by-step manner. Our generality is demonstrated by our ability to evaluate not only pure vision-based real-world benchmarks (i.e., OSWorld), but also more general or tool-intensive benchmarks (e.g., GAIA and SWE-Bench). Specifically, we achieve $\mathbf{7.27\%}$ accuracy on OSWorld, higher than Claude-Computer-Use. Codes and evaluation scripts are open-sourced at https://github.com/bin123apple/InfantAgent.
RankFlow: A Multi-Role Collaborative Reranking Workflow Utilizing Large Language Models
Feb 04, 2025



In an Information Retrieval (IR) system, reranking plays a critical role by sorting candidate passages according to their relevance to a specific query. This process demands a nuanced understanding of the variations among passages linked to the query. In this work, we introduce RankFlow, a multi-role reranking workflow that leverages the capabilities of Large Language Models (LLMs) and role specializations to improve reranking performance. RankFlow enlists LLMs to fulfill four distinct roles: the query Rewriter, the pseudo Answerer, the passage Summarizer, and the Reranker. This orchestrated approach enables RankFlow to: (1) accurately interpret queries, (2) draw upon LLMs' extensive pre-existing knowledge, (3) distill passages into concise versions, and (4) assess passages in a comprehensive manner, resulting in notably better reranking results. Our experimental results reveal that RankFlow outperforms existing leading approaches on widely recognized IR benchmarks, such as TREC-DL, BEIR, and NovelEval. Additionally, we investigate the individual contributions of each role in RankFlow. Code is available at https://github.com/jincan333/RankFlow.
AdaPI: Facilitating DNN Model Adaptivity for Efficient Private Inference in Edge Computing
Jul 08, 2024



Private inference (PI) has emerged as a promising solution to execute computations on encrypted data, safeguarding user privacy and model parameters in edge computing. However, existing PI methods are predominantly developed considering constant resource constraints, overlooking the varied and dynamic resource constraints in diverse edge devices, like energy budgets. Consequently, model providers have to design specialized models for different devices, where all of them have to be stored on the edge server, resulting in inefficient deployment. To fill this gap, this work presents AdaPI, a novel approach that achieves adaptive PI by allowing a model to perform well across edge devices with diverse energy budgets. AdaPI employs a PI-aware training strategy that optimizes the model weights alongside weight-level and feature-level soft masks. These soft masks are subsequently transformed into multiple binary masks to enable adjustments in communication and computation workloads. Through sequentially training the model with increasingly dense binary masks, AdaPI attains optimal accuracy for each energy budget, which outperforms the state-of-the-art PI methods by 7.3\% in terms of test accuracy on CIFAR-100. The code of AdaPI can be accessed via https://github.com/jiahuiiiiii/AdaPI.
MaxK-GNN: Towards Theoretical Speed Limits for Accelerating Graph Neural Networks Training
Dec 18, 2023



In the acceleration of deep neural network training, the GPU has become the mainstream platform. GPUs face substantial challenges on GNNs, such as workload imbalance and memory access irregularities, leading to underutilized hardware. Existing solutions such as PyG, DGL with cuSPARSE, and GNNAdvisor frameworks partially address these challenges but memory traffic is still significant. We argue that drastic performance improvements can only be achieved by the vertical optimization of algorithm and system innovations, rather than treating the speedup optimization as an "after-thought" (i.e., (i) given a GNN algorithm, designing an accelerator, or (ii) given hardware, mainly optimizing the GNN algorithm). In this paper, we present MaxK-GNN, an advanced high-performance GPU training system integrating algorithm and system innovation. (i) We introduce the MaxK nonlinearity and provide a theoretical analysis of MaxK nonlinearity as a universal approximator, and present the Compressed Balanced Sparse Row (CBSR) format, designed to store the data and index of the feature matrix after nonlinearity; (ii) We design a coalescing enhanced forward computation with row-wise product-based SpGEMM Kernel using CBSR for input feature matrix fetching and strategic placement of a sparse output accumulation buffer in shared memory; (iii) We develop an optimized backward computation with outer product-based and SSpMM Kernel. We conduct extensive evaluations of MaxK-GNN and report the end-to-end system run-time. Experiments show that MaxK-GNN system could approach the theoretical speedup limit according to Amdahl's law. We achieve comparable accuracy to SOTA GNNs, but at a significantly increased speed: 3.22/4.24 times speedup (vs. theoretical limits, 5.52/7.27 times) on Reddit compared to DGL and GNNAdvisor implementations.
Advanced Language Model-Driven Verilog Development: Enhancing Power, Performance, and Area Optimization in Code Synthesis
Dec 02, 2023The increasing use of Advanced Language Models (ALMs) in diverse sectors, particularly due to their impressive capability to generate top-tier content following linguistic instructions, forms the core of this investigation. This study probes into ALMs' deployment in electronic hardware design, with a specific emphasis on the synthesis and enhancement of Verilog programming. We introduce an innovative framework, crafted to assess and amplify ALMs' productivity in this niche. The methodology commences with the initial crafting of Verilog programming via ALMs, succeeded by a distinct dual-stage refinement protocol. The premier stage prioritizes augmenting the code's operational and linguistic precision, while the latter stage is dedicated to aligning the code with Power-Performance-Area (PPA) benchmarks, a pivotal component in proficient hardware design. This bifurcated strategy, merging error remediation with PPA enhancement, has yielded substantial upgrades in the caliber of ALM-created Verilog programming. Our framework achieves an 81.37% rate in linguistic accuracy and 62.0% in operational efficacy in programming synthesis, surpassing current leading-edge techniques, such as 73% in linguistic accuracy and 46% in operational efficacy. These findings illuminate ALMs' aptitude in tackling complex technical domains and signal a positive shift in the mechanization of hardware design operations.
Accel-GCN: High-Performance GPU Accelerator Design for Graph Convolution Networks
Aug 22, 2023



Graph Convolutional Networks (GCNs) are pivotal in extracting latent information from graph data across various domains, yet their acceleration on mainstream GPUs is challenged by workload imbalance and memory access irregularity. To address these challenges, we present Accel-GCN, a GPU accelerator architecture for GCNs. The design of Accel-GCN encompasses: (i) a lightweight degree sorting stage to group nodes with similar degree; (ii) a block-level partition strategy that dynamically adjusts warp workload sizes, enhancing shared memory locality and workload balance, and reducing metadata overhead compared to designs like GNNAdvisor; (iii) a combined warp strategy that improves memory coalescing and computational parallelism in the column dimension of dense matrices. Utilizing these principles, we formulated a kernel for sparse matrix multiplication (SpMM) in GCNs that employs block-level partitioning and combined warp strategy. This approach augments performance and multi-level memory efficiency and optimizes memory bandwidth by exploiting memory coalescing and alignment. Evaluation of Accel-GCN across 18 benchmark graphs reveals that it outperforms cuSPARSE, GNNAdvisor, and graph-BLAST by factors of 1.17 times, 1.86 times, and 2.94 times respectively. The results underscore Accel-GCN as an effective solution for enhancing GCN computational efficiency.
AutoReP: Automatic ReLU Replacement for Fast Private Network Inference
Aug 20, 2023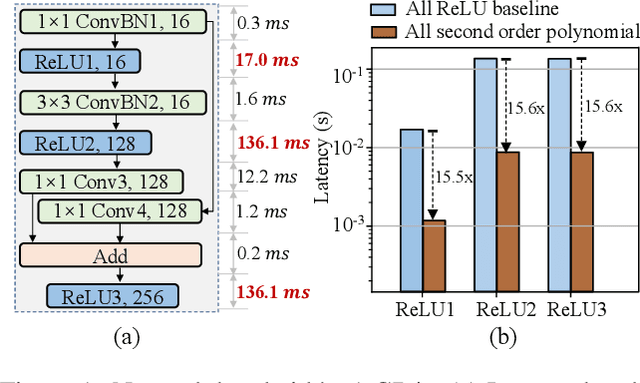

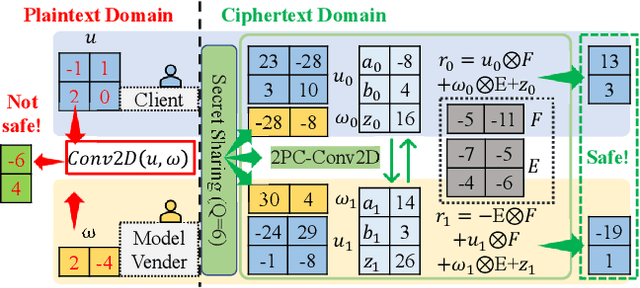
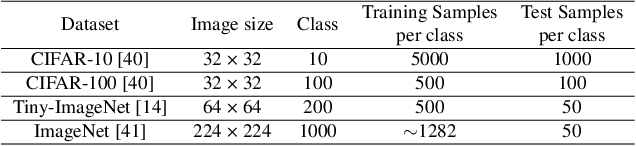
The growth of the Machine-Learning-As-A-Service (MLaaS) market has highlighted clients' data privacy and security issues. Private inference (PI) techniques using cryptographic primitives offer a solution but often have high computation and communication costs, particularly with non-linear operators like ReLU. Many attempts to reduce ReLU operations exist, but they may need heuristic threshold selection or cause substantial accuracy loss. This work introduces AutoReP, a gradient-based approach to lessen non-linear operators and alleviate these issues. It automates the selection of ReLU and polynomial functions to speed up PI applications and introduces distribution-aware polynomial approximation (DaPa) to maintain model expressivity while accurately approximating ReLUs. Our experimental results demonstrate significant accuracy improvements of 6.12% (94.31%, 12.9K ReLU budget, CIFAR-10), 8.39% (74.92%, 12.9K ReLU budget, CIFAR-100), and 9.45% (63.69%, 55K ReLU budget, Tiny-ImageNet) over current state-of-the-art methods, e.g., SNL. Morever, AutoReP is applied to EfficientNet-B2 on ImageNet dataset, and achieved 75.55% accuracy with 176.1 times ReLU budget reduction.
RRNet: Towards ReLU-Reduced Neural Network for Two-party Computation Based Private Inference
Feb 22, 2023



The proliferation of deep learning (DL) has led to the emergence of privacy and security concerns. To address these issues, secure Two-party computation (2PC) has been proposed as a means of enabling privacy-preserving DL computation. However, in practice, 2PC methods often incur high computation and communication overhead, which can impede their use in large-scale systems. To address this challenge, we introduce RRNet, a systematic framework that aims to jointly reduce the overhead of MPC comparison protocols and accelerate computation through hardware acceleration. Our approach integrates the hardware latency of cryptographic building blocks into the DNN loss function, resulting in improved energy efficiency, accuracy, and security guarantees. Furthermore, we propose a cryptographic hardware scheduler and corresponding performance model for Field Programmable Gate Arrays (FPGAs) to further enhance the efficiency of our framework. Experiments show RRNet achieved a much higher ReLU reduction performance than all SOTA works on CIFAR-10 dataset.