 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateful Reasoning via Insight Replay
May 14, 2026Chain-of-Thought (CoT) reasoning has become a foundation for eliciting multi-step reasoning in large language models, but recent studies show that its benefits do not scale monotonically with chain length: while longer CoT generally enables a model to tackle harder problems, on a given problem, accuracy typically increases with CoT length up to a point, after which it declines. We identify a major cause of this phenomenon: as the CoT grows, the model's attention to critical insights produced earlier in the trace gradually weakens, making those insights progressively less accessible when they are most needed. Therefore, we propose \textbf{InsightReplay}, a stateful reasoning approach in which the model periodically extracts critical insights from its reasoning trace and replays them near the active generation frontier, keeping them accessible as the reasoning scales. Extensive experiments on a $\mathbf{2}\!\times\!\mathbf{3}\!\times\!\mathbf{4}$ benchmark grid, covering model scales $\{\text{8B}, \text{30B}\}$, model families $\{\text{Qwen3.5}, \text{DeepSeek-R1-Distill-Qwen}, \text{Gemma-4}\}$, and reasoning benchmarks $\{\text{AIME}, \text{HMMT}, \text{GPQA Diamond}, \text{LiveCodeBench v5}\}$, show that 3-round InsightReplay yields accuracy gains across \textbf{all 24 settings}, with an averaged improvement of $\mathbf{+1.65}$ points over standard CoT, and a largest single-setting gain of $\mathbf{+9.2}$ points on R1-Distill-32B's LiveCodeBench v5 subset. Our results suggest that the effectiveness of test-time scaling depends not only on how much a model reasons, but also on whether critical intermediate insights remain accessible throughout long reasoning trajectories.
InfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
May 16, 2025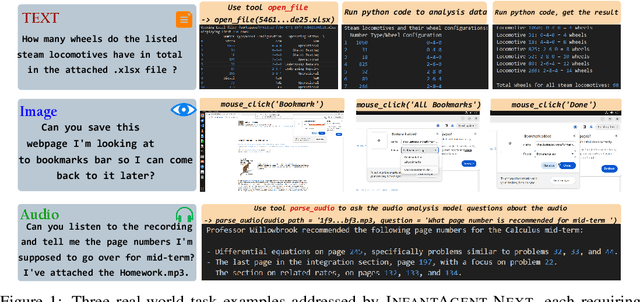

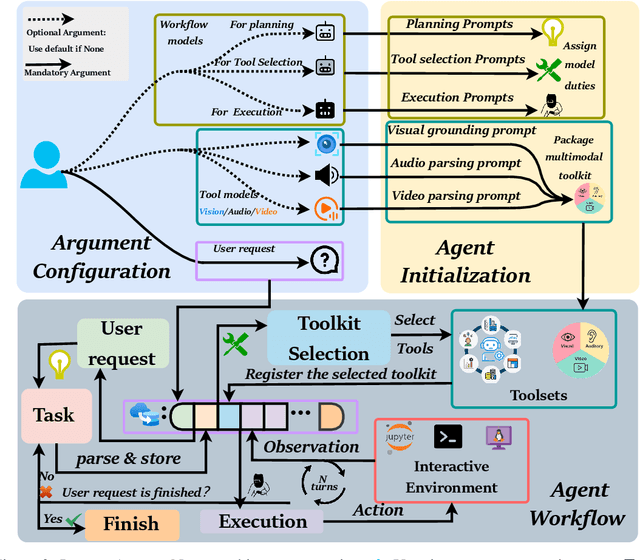
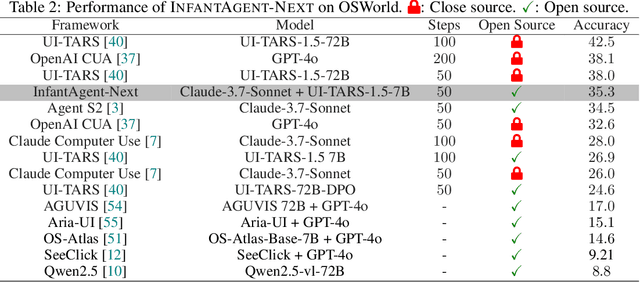
This paper introduces \textsc{InfantAgent-Next}, a generalist agent capable of interacting with computers in a multimodal manner, encompassing text, images, audio, and video. Unlike existing approaches that either build intricate workflows around a single large model or only provide workflow modularity, our agent integrates tool-based and pure vision agents within a highly modular architecture, enabling different models to collaboratively solve decoupled tasks in a step-by-step manner. Our generality is demonstrated by our ability to evaluate not only pure vision-based real-world benchmarks (i.e., OSWorld), but also more general or tool-intensive benchmarks (e.g., GAIA and SWE-Bench). Specifically, we achieve $\mathbf{7.27\%}$ accuracy on OSWorld, higher than Claude-Computer-Use. Codes and evaluation scripts are open-sourced at https://github.com/bin123apple/InfantAgent.
Fortran2CPP: Automating Fortran-to-C++ Migration using LLMs via Multi-Turn Dialogue and Dual-Agent Integration
Dec 27, 2024



Migrating Fortran code to C++ is a common task for many scientific computing teams, driven by the need to leverage modern programming paradigms, enhance cross-platform compatibility, and improve maintainability. Automating this translation process using large language models (LLMs) has shown promise, but the lack of high-quality, specialized datasets has hindered their effectiveness. In this paper, we address this challenge by introducing a novel multi-turn dialogue dataset, Fortran2CPP, specifically designed for Fortran-to-C++ code migration. Our dataset, significantly larger than existing alternatives, is generated using a unique LLM-driven, dual-agent pipeline incorporating iterative compilation, execution, and code repair to ensure high quality and functional correctness. To demonstrate the effectiveness of our dataset, we fine-tuned several open-weight LLMs on Fortran2CPP and evaluated their performance on two independent benchmarks. Fine-tuning on our dataset led to remarkable gains, with models achieving up to a 3.31x increase in CodeBLEU score and a 92\% improvement in compilation success rate. This highlights the dataset's ability to enhance both the syntactic accuracy and compilability of the translated C++ code. Our dataset and model have been open-sourced and are available on our public GitHub repository\footnote{\url{https://github.com/HPC-Fortran2CPP/Fortran2Cpp}}.
Infant Agent: A Tool-Integrated, Logic-Driven Agent with Cost-Effective API Usage
Nov 02, 2024



Despite the impressive capabilities of large language models (LLMs), they currently exhibit two primary limitations, \textbf{\uppercase\expandafter{\romannumeral 1}}: They struggle to \textbf{autonomously solve the real world engineering problem}. \textbf{\uppercase\expandafter{\romannumeral 2}}: They remain \textbf{challenged in reasoning through complex logic problems}. To address these challenges, we developed the \textsc{Infant Agent}, integrating task-aware functions, operators, a hierarchical management system, and a memory retrieval mechanism. Together, these components enable large language models to sustain extended reasoning processes and handle complex, multi-step tasks efficiently, all while significantly reducing API costs. Using the \textsc{Infant Agent}, GPT-4o's accuracy on the SWE-bench-lite dataset rises from $\mathbf{0.33\%}$ to $\mathbf{30\%}$, and in the AIME-2024 mathematics competition, it increases GPT-4o's accuracy from $\mathbf{13.3\%}$ to $\mathbf{37\%}$.
FALCON: Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization system
Oct 28, 2024



Recently, large language models (LLMs) have achieved significant progress in automated code generation. Despite their strong instruction-following capabilities, these models frequently struggled to align with user intent in coding scenarios. In particular, they were hampered by datasets that lacked diversity and failed to address specialized tasks or edge cases. Furthermore, challenges in supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) led to failures in generating precise, human-intent-aligned code. To tackle these challenges and improve the code generation performance for automated programming systems, we propose Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization (i.e., FALCON). FALCON is structured into two hierarchical levels. From the global level, long-term memory improves code quality by retaining and applying learned knowledge. At the local level, short-term memory allows for the incorporation of immediate feedback from compilers and AI systems. Additionally, we introduce meta-reinforcement learning with feedback rewards to solve the global-local bi-level optimization problem and enhance the model's adaptability across diverse code generation tasks. Extensive experiments demonstrate that our technique achieves state-of-the-art performance, leading other reinforcement learning methods by more than 4.5 percentage points on the MBPP benchmark and 6.1 percentage points on the Humaneval benchmark. The open-sourced code is publicly available at https://github.com/titurte/FALCON.
AutoCoder: Enhancing Code Large Language Model with \textsc{AIEV-Instruct}
May 23, 2024



We introduce AutoCoder, the first Large Language Model to surpass GPT-4 Turbo (April 2024) and GPT-4o in pass@1 on the Human Eval benchmark test ($\mathbf{90.9\%}$ vs. $\mathbf{90.2\%}$). In addition, AutoCoder offers a more versatile code interpreter compared to GPT-4 Turbo and GPT-4o. It's code interpreter can install external packages instead of limiting to built-in packages. AutoCoder's training data is a multi-turn dialogue dataset created by a system combining agent interaction and external code execution verification, a method we term \textbf{\textsc{AIEV-Instruct}} (Instruction Tuning with Agent-Interaction and Execution-Verified). Compared to previous large-scale code dataset generation methods, \textsc{AIEV-Instruct} reduces dependence on proprietary large models and provides execution-validated code dataset. The code and the demo video is available in \url{https://github.com/bin123apple/AutoCoder}.
MACM: Utilizing a Multi-Agent System for Condition Mining in Solving Complex Mathematical Problems
Apr 06, 2024



Recent advancements in large language models, such as GPT-4, have demonstrated remarkable capabilities in processing standard queries. Despite these advancements, their performance substantially declines in \textbf{advanced mathematical problems requiring complex, multi-step logical reasoning}. To enhance their inferential capabilities, current research has delved into \textit{prompting engineering}, exemplified by methodologies such as the Tree of Thought and Graph of Thought. Nonetheless, these existing approaches encounter two significant limitations. Firstly, their effectiveness in tackling complex mathematical problems is somewhat constrained. Secondly, the necessity to design distinct prompts for individual problems hampers their generalizability. In response to these limitations, this paper introduces the \textit{Multi-Agent System for conditional Mining} (\textbf{MACM}) prompting method. It not only resolves intricate mathematical problems but also demonstrates strong generalization capabilities across various mathematical contexts. With the assistance of MACM, the accuracy of GPT-4 Turbo on the most challenging level five mathematical problems in the MATH dataset increase from $\mathbf{54.68\%} \text{ to } \mathbf{76.73\%}$. The code is available in \url{https://github.com/bin123apple/MACM}.
FlashVideo: A Framework for Swift Inference in Text-to-Video Generation
Dec 30, 2023In the evolving field of machine learning, video generation has witnessed significant advancements with autoregressive-based transformer models and diffusion models, known for synthesizing dynamic and realistic scenes. However, these models often face challenges with prolonged inference times, even for generating short video clips such as GIFs. This paper introduces FlashVideo, a novel framework tailored for swift Text-to-Video generation. FlashVideo represents the first successful adaptation of the RetNet architecture for video generation, bringing a unique approach to the field. Leveraging the RetNet-based architecture, FlashVideo reduces the time complexity of inference from $\mathcal{O}(L^2)$ to $\mathcal{O}(L)$ for a sequence of length $L$, significantly accelerating inference speed. Additionally, we adopt a redundant-free frame interpolation method, enhancing the efficiency of frame interpolation. Our comprehensive experiments demonstrate that FlashVideo achieves a $\times9.17$ efficiency improvement over a traditional autoregressive-based transformer model, and its inference speed is of the same order of magnitude as that of BERT-based transformer models.
Advanced Language Model-Driven Verilog Development: Enhancing Power, Performance, and Area Optimization in Code Synthesis
Dec 02, 2023The increasing use of Advanced Language Models (ALMs) in diverse sectors, particularly due to their impressive capability to generate top-tier content following linguistic instructions, forms the core of this investigation. This study probes into ALMs' deployment in electronic hardware design, with a specific emphasis on the synthesis and enhancement of Verilog programming. We introduce an innovative framework, crafted to assess and amplify ALMs' productivity in this niche. The methodology commences with the initial crafting of Verilog programming via ALMs, succeeded by a distinct dual-stage refinement protocol. The premier stage prioritizes augmenting the code's operational and linguistic precision, while the latter stage is dedicated to aligning the code with Power-Performance-Area (PPA) benchmarks, a pivotal component in proficient hardware design. This bifurcated strategy, merging error remediation with PPA enhancement, has yielded substantial upgrades in the caliber of ALM-created Verilog programming. Our framework achieves an 81.37% rate in linguistic accuracy and 62.0% in operational efficacy in programming synthesis, surpassing current leading-edge techniques, such as 73% in linguistic accuracy and 46% in operational efficacy. These findings illuminate ALMs' aptitude in tackling complex technical domains and signal a positive shift in the mechanization of hardware design operations.
CompCodeVet: A Compiler-guided Validation and Enhancement Approach for Code Dataset
Nov 11, 2023



Large language models (LLMs) have become increasingly prominent in academia and industry due to their remarkable performance in diverse applications. As these models evolve with increasing parameters, they excel in tasks like sentiment analysis and machine translation. However, even models with billions of parameters face challenges in tasks demanding multi-step reasoning. Code generation and comprehension, especially in C and C++, emerge as significant challenges. While LLMs trained on code datasets demonstrate competence in many tasks, they struggle with rectifying non-compilable C and C++ code. Our investigation attributes this subpar performance to two primary factors: the quality of the training dataset and the inherent complexity of the problem which demands intricate reasoning. Existing "Chain of Thought" (CoT) prompting techniques aim to enhance multi-step reasoning. This approach, however, retains the limitations associated with the latent drawbacks of LLMs. In this work, we propose CompCodeVet, a compiler-guided CoT approach to produce compilable code from non-compilable ones. Diverging from the conventional approach of utilizing larger LLMs, we employ compilers as a teacher to establish a more robust zero-shot thought process. The evaluation of CompCodeVet on two open-source code datasets shows that CompCodeVet has the ability to improve the training dataset quality for LLMs.