 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInline Critic Steers Image Editing
May 12, 2026Instruction-based image editing exhibits heterogeneous difficulty not only across cases but also across regions of an image, motivating refinement approaches that allocate correction to where the model struggles. Existing refinement signals arrive late, after a fully generated image or a completed denoising step. We ask whether such a signal can act within an ongoing forward pass. To investigate this, we probe a frozen image-editing model and find that although generation capability emerges only in the last few layers, the error pattern is already set in early layers (rank correlation \r{ho} = 0.83 with the final-layer error map). Based on this, we introduce Inline Critic, a learnable token that critiques a frozen model's predictions at its intermediate layers and steers its hidden states to refine generation during the forward pass. A three-stage recipe is proposed to stabilize the training from learning how to critique to steering generation. As a result, we achieve state of the art on GEdit-Bench (7.89), a +9.4 gain on RISEBench over the same backbone, and the strongest open-source result on KRIS-Bench (81.92, surpassing GPT-4o). We further provide analyses showing that the critic genuinely shapes the model's attention and prediction updates at subsequent layers.
From Particles to Fields: Reframing Photon Mapping with Continuous Gaussian Photon Fields
Dec 13, 2025Accurately modeling light transport is essential for realistic image synthesis. Photon mapping provides physically grounded estimates of complex global illumination effects such as caustics and specular-diffuse interactions, yet its per-view radiance estimation remains computationally inefficient when rendering multiple views of the same scene. The inefficiency arises from independent photon tracing and stochastic kernel estimation at each viewpoint, leading to inevitable redundant computation. To accelerate multi-view rendering, we reformulate photon mapping as a continuous and reusable radiance function. Specifically, we introduce the Gaussian Photon Field (GPF), a learnable representation that encodes photon distributions as anisotropic 3D Gaussian primitives parameterized by position, rotation, scale, and spectrum. GPF is initialized from physically traced photons in the first SPPM iteration and optimized using multi-view supervision of final radiance, distilling photon-based light transport into a continuous field. Once trained, the field enables differentiable radiance evaluation along camera rays without repeated photon tracing or iterative refinement. Extensive experiments on scenes with complex light transport, such as caustics and specular-diffuse interactions, demonstrate that GPF attains photon-level accuracy while reducing computation by orders of magnitude, unifying the physical rigor of photon-based rendering with the efficiency of neural scene representations.
VGent: Visual Grounding via Modular Design for Disentangling Reasoning and Prediction
Dec 11, 2025



Current visual grounding models are either based on a Multimodal Large Language Model (MLLM) that performs auto-regressive decoding, which is slow and risks hallucinations, or on re-aligning an LLM with vision features to learn new special or object tokens for grounding, which may undermine the LLM's pretrained reasoning ability. In contrast, we propose VGent, a modular encoder-decoder architecture that explicitly disentangles high-level reasoning and low-level bounding box prediction. Specifically, a frozen MLLM serves as the encoder to provide untouched powerful reasoning capabilities, while a decoder takes high-quality boxes proposed by detectors as queries and selects target box(es) via cross-attending on encoder's hidden states. This design fully leverages advances in both object detection and MLLM, avoids the pitfalls of auto-regressive decoding, and enables fast inference. Moreover, it supports modular upgrades of both the encoder and decoder to benefit the whole system: we introduce (i) QuadThinker, an RL-based training paradigm for enhancing multi-target reasoning ability of the encoder; (ii) mask-aware label for resolving detection-segmentation ambiguity; and (iii) global target recognition to improve the recognition of all the targets which benefits the selection among augmented proposals. Experiments on multi-target visual grounding benchmarks show that VGent achieves a new state-of-the-art with +20.6% F1 improvement over prior methods, and further boosts gIoU by +8.2% and cIoU by +5.8% under visual reference challenges, while maintaining constant, fast inference latency.
Investigating the Design Space of Visual Grounding in Multimodal Large Language Model
Aug 11, 2025



Fine-grained multimodal capability in Multimodal Large Language Models (MLLMs) has emerged as a critical research direction, particularly for tackling the visual grounding (VG) problem. Despite the strong performance achieved by existing approaches, they often employ disparate design choices when fine-tuning MLLMs for VG, lacking systematic verification to support these designs. To bridge this gap, this paper presents a comprehensive study of various design choices that impact the VG performance of MLLMs. We conduct our analysis using LLaVA-1.5, which has been widely adopted in prior empirical studies of MLLMs. While more recent models exist, we follow this convention to ensure our findings remain broadly applicable and extendable to other architectures. We cover two key aspects: (1) exploring different visual grounding paradigms in MLLMs, identifying the most effective design, and providing our insights; and (2) conducting ablation studies on the design of grounding data to optimize MLLMs' fine-tuning for the VG task. Finally, our findings contribute to a stronger MLLM for VG, achieving improvements of +5.6% / +6.9% / +7.0% on RefCOCO/+/g over the LLaVA-1.5.
InfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
May 16, 2025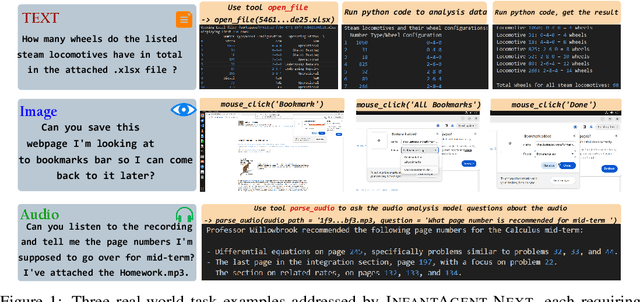

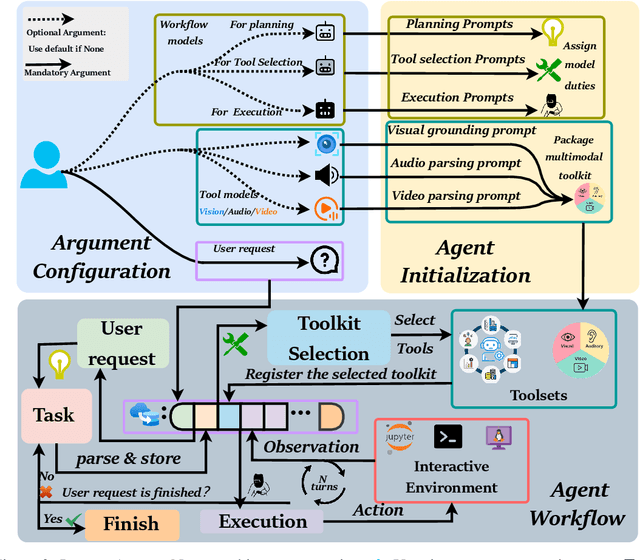
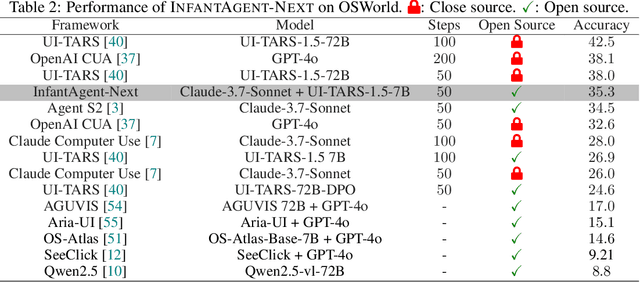
This paper introduces \textsc{InfantAgent-Next}, a generalist agent capable of interacting with computers in a multimodal manner, encompassing text, images, audio, and video. Unlike existing approaches that either build intricate workflows around a single large model or only provide workflow modularity, our agent integrates tool-based and pure vision agents within a highly modular architecture, enabling different models to collaboratively solve decoupled tasks in a step-by-step manner. Our generality is demonstrated by our ability to evaluate not only pure vision-based real-world benchmarks (i.e., OSWorld), but also more general or tool-intensive benchmarks (e.g., GAIA and SWE-Bench). Specifically, we achieve $\mathbf{7.27\%}$ accuracy on OSWorld, higher than Claude-Computer-Use. Codes and evaluation scripts are open-sourced at https://github.com/bin123apple/InfantAgent.
3DResT: A Strong Baseline for Semi-Supervised 3D Referring Expression Segmentation
Apr 17, 20253D Referring Expression Segmentation (3D-RES) typically requires extensive instance-level annotations, which are time-consuming and costly. Semi-supervised learning (SSL) mitigates this by using limited labeled data alongside abundant unlabeled data, improving performance while reducing annotation costs. SSL uses a teacher-student paradigm where teacher generates high-confidence-filtered pseudo-labels to guide student. However, in the context of 3D-RES, where each label corresponds to a single mask and labeled data is scarce, existing SSL methods treat high-quality pseudo-labels merely as auxiliary supervision, which limits the model's learning potential. The reliance on high-confidence thresholds for filtering often results in potentially valuable pseudo-labels being discarded, restricting the model's ability to leverage the abundant unlabeled data. Therefore, we identify two critical challenges in semi-supervised 3D-RES, namely, inefficient utilization of high-quality pseudo-labels and wastage of useful information from low-quality pseudo-labels. In this paper, we introduce the first semi-supervised learning framework for 3D-RES, presenting a robust baseline method named 3DResT. To address these challenges, we propose two novel designs called Teacher-Student Consistency-Based Sampling (TSCS) and Quality-Driven Dynamic Weighting (QDW). TSCS aids in the selection of high-quality pseudo-labels, integrating them into the labeled dataset to strengthen the labeled supervision signals. QDW preserves low-quality pseudo-labels by dynamically assigning them lower weights, allowing for the effective extraction of useful information rather than discarding them. Extensive experiments conducted on the widely used benchmark demonstrate the effectiveness of our method. Notably, with only 1% labeled data, 3DResT achieves an mIoU improvement of 8.34 points compared to the fully supervised method.
Infant Agent: A Tool-Integrated, Logic-Driven Agent with Cost-Effective API Usage
Nov 02, 2024



Despite the impressive capabilities of large language models (LLMs), they currently exhibit two primary limitations, \textbf{\uppercase\expandafter{\romannumeral 1}}: They struggle to \textbf{autonomously solve the real world engineering problem}. \textbf{\uppercase\expandafter{\romannumeral 2}}: They remain \textbf{challenged in reasoning through complex logic problems}. To address these challenges, we developed the \textsc{Infant Agent}, integrating task-aware functions, operators, a hierarchical management system, and a memory retrieval mechanism. Together, these components enable large language models to sustain extended reasoning processes and handle complex, multi-step tasks efficiently, all while significantly reducing API costs. Using the \textsc{Infant Agent}, GPT-4o's accuracy on the SWE-bench-lite dataset rises from $\mathbf{0.33\%}$ to $\mathbf{30\%}$, and in the AIME-2024 mathematics competition, it increases GPT-4o's accuracy from $\mathbf{13.3\%}$ to $\mathbf{37\%}$.
ACTRESS: Active Retraining for Semi-supervised Visual Grounding
Jul 03, 2024Semi-Supervised Visual Grounding (SSVG) is a new challenge for its sparse labeled data with the need for multimodel understanding. A previous study, RefTeacher, makes the first attempt to tackle this task by adopting the teacher-student framework to provide pseudo confidence supervision and attention-based supervision. However, this approach is incompatible with current state-of-the-art visual grounding models, which follow the Transformer-based pipeline. These pipelines directly regress results without region proposals or foreground binary classification, rendering them unsuitable for fitting in RefTeacher due to the absence of confidence scores. Furthermore, the geometric difference in teacher and student inputs, stemming from different data augmentations, induces natural misalignment in attention-based constraints. To establish a compatible SSVG framework, our paper proposes the ACTive REtraining approach for Semi-Supervised Visual Grounding, abbreviated as ACTRESS. Initially, the model is enhanced by incorporating an additional quantized detection head to expose its detection confidence. Building upon this, ACTRESS consists of an active sampling strategy and a selective retraining strategy. The active sampling strategy iteratively selects high-quality pseudo labels by evaluating three crucial aspects: Faithfulness, Robustness, and Confidence, optimizing the utilization of unlabeled data. The selective retraining strategy retrains the model with periodic re-initialization of specific parameters, facilitating the model's escape from local minima. Extensive experiments demonstrates our superior performance on widely-used benchmark datasets.
SegVG: Transferring Object Bounding Box to Segmentation for Visual Grounding
Jul 03, 2024



Different from Object Detection, Visual Grounding deals with detecting a bounding box for each text-image pair. This one box for each text-image data provides sparse supervision signals. Although previous works achieve impressive results, their passive utilization of annotation, i.e. the sole use of the box annotation as regression ground truth, results in a suboptimal performance. In this paper, we present SegVG, a novel method transfers the box-level annotation as Segmentation signals to provide an additional pixel-level supervision for Visual Grounding. Specifically, we propose the Multi-layer Multi-task Encoder-Decoder as the target grounding stage, where we learn a regression query and multiple segmentation queries to ground the target by regression and segmentation of the box in each decoding layer, respectively. This approach allows us to iteratively exploit the annotation as signals for both box-level regression and pixel-level segmentation. Moreover, as the backbones are typically initialized by pretrained parameters learned from unimodal tasks and the queries for both regression and segmentation are static learnable embeddings, a domain discrepancy remains among these three types of features, which impairs subsequent target grounding. To mitigate this discrepancy, we introduce the Triple Alignment module, where the query, text, and vision tokens are triangularly updated to share the same space by triple attention mechanism. Extensive experiments on five widely used datasets validate our state-of-the-art (SOTA) performance.
Visual Grounding with Attention-Driven Constraint Balancing
Jul 03, 2024Unlike Object Detection, Visual Grounding task necessitates the detection of an object described by complex free-form language. To simultaneously model such complex semantic and visual representations, recent state-of-the-art studies adopt transformer-based models to fuse features from both modalities, further introducing various modules that modulate visual features to align with the language expressions and eliminate the irrelevant redundant information. However, their loss function, still adopting common Object Detection losses, solely governs the bounding box regression output, failing to fully optimize for the above objectives. To tackle this problem, in this paper, we first analyze the attention mechanisms of transformer-based models. Building upon this, we further propose a novel framework named Attention-Driven Constraint Balancing (AttBalance) to optimize the behavior of visual features within language-relevant regions. Extensive experimental results show that our method brings impressive improvements. Specifically, we achieve constant improvements over five different models evaluated on four different benchmarks. Moreover, we attain a new state-of-the-art performance by integrating our method into QRNet.