 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Personalized Text Generation with Multi-Trajectory Reasoning
Apr 27, 2026As Large Language Models (LLMs) advance, personalization has become a key mechanism for tailoring outputs to individual user needs. However, most existing methods rely heavily on dense interaction histories, making them ineffective in cold-start scenarios where such data is sparse or unavailable. While external signals (e.g., content of similar users) can offer a potential remedy, leveraging them effectively remains challenging: raw context is often noisy, and existing methods struggle to reason over heterogeneous data sources. To address these issues, we introduce PAT (Personalization with Aligned Trajectories), a reasoning framework for cold-start LLM personalization. PAT first retrieves information along two complementary trajectories: writing-style cues from stylistically similar users and topic-specific context from preference-aligned users. It then employs a reinforcement learning-based, iterative dual-reasoning mechanism that enables the LLM to jointly refine and integrate these signals. Experimental results across real-world personalization benchmarks show that PAT consistently improves generation quality and alignment under sparse-data conditions, establishing a strong solution to the cold-start personalization problem.
A Survey on LLM-based Conversational User Simulation
Apr 27, 2026User simulation has long played a vital role in computer science due to its potential to support a wide range of applications. Language, as the primary medium of human communication, forms the foundation of social interaction and behavior. Consequently, simulating conversational behavior has become a key area of study. Recent advancements in large language models (LLMs) have significantly catalyzed progress in this domain by enabling high-fidelity generation of synthetic user conversation. In this paper, we survey recent advancements in LLM-based conversational user simulation. We introduce a novel taxonomy covering user granularity and simulation objectives. Additionally, we systematically analyze core techniques and evaluation methodologies. We aim to keep the research community informed of the latest advancements in conversational user simulation and to further facilitate future research by identifying open challenges and organizing existing work under a unified framework.
Human-Aligned MLLM Judges for Fine-Grained Image Editing Evaluation: A Benchmark, Framework, and Analysis
Feb 13, 2026Evaluating image editing models remains challenging due to the coarse granularity and limited interpretability of traditional metrics, which often fail to capture aspects important to human perception and intent. Such metrics frequently reward visually plausible outputs while overlooking controllability, edit localization, and faithfulness to user instructions. In this work, we introduce a fine-grained Multimodal Large Language Model (MLLM)-as-a-Judge framework for image editing that decomposes common evaluation notions into twelve fine-grained interpretable factors spanning image preservation, edit quality, and instruction fidelity. Building on this formulation, we present a new human-validated benchmark that integrates human judgments, MLLM-based evaluations, model outputs, and traditional metrics across diverse image editing tasks. Through extensive human studies, we show that the proposed MLLM judges align closely with human evaluations at a fine granularity, supporting their use as reliable and scalable evaluators. We further demonstrate that traditional image editing metrics are often poor proxies for these factors, failing to distinguish over-edited or semantically imprecise outputs, whereas our judges provide more intuitive and informative assessments in both offline and online settings. Together, this work introduces a benchmark, a principled factorization, and empirical evidence positioning fine-grained MLLM judges as a practical foundation for studying, comparing, and improving image editing approaches.
SliderEdit: Continuous Image Editing with Fine-Grained Instruction Control
Nov 12, 2025Instruction-based image editing models have recently achieved impressive performance, enabling complex edits to an input image from a multi-instruction prompt. However, these models apply each instruction in the prompt with a fixed strength, limiting the user's ability to precisely and continuously control the intensity of individual edits. We introduce SliderEdit, a framework for continuous image editing with fine-grained, interpretable instruction control. Given a multi-part edit instruction, SliderEdit disentangles the individual instructions and exposes each as a globally trained slider, allowing smooth adjustment of its strength. Unlike prior works that introduced slider-based attribute controls in text-to-image generation, typically requiring separate training or fine-tuning for each attribute or concept, our method learns a single set of low-rank adaptation matrices that generalize across diverse edits, attributes, and compositional instructions. This enables continuous interpolation along individual edit dimensions while preserving both spatial locality and global semantic consistency. We apply SliderEdit to state-of-the-art image editing models, including FLUX-Kontext and Qwen-Image-Edit, and observe substantial improvements in edit controllability, visual consistency, and user steerability. To the best of our knowledge, we are the first to explore and propose a framework for continuous, fine-grained instruction control in instruction-based image editing models. Our results pave the way for interactive, instruction-driven image manipulation with continuous and compositional control.
Decomposition-Enhanced Training for Post-Hoc Attributions In Language Models
Oct 29, 2025Large language models (LLMs) are increasingly used for long-document question answering, where reliable attribution to sources is critical for trust. Existing post-hoc attribution methods work well for extractive QA but struggle in multi-hop, abstractive, and semi-extractive settings, where answers synthesize information across passages. To address these challenges, we argue that post-hoc attribution can be reframed as a reasoning problem, where answers are decomposed into constituent units, each tied to specific context. We first show that prompting models to generate such decompositions alongside attributions improves performance. Building on this, we introduce DecompTune, a post-training method that teaches models to produce answer decompositions as intermediate reasoning steps. We curate a diverse dataset of complex QA tasks, annotated with decompositions by a strong LLM, and post-train Qwen-2.5 (7B and 14B) using a two-stage SFT + GRPO pipeline with task-specific curated rewards. Across extensive experiments and ablations, DecompTune substantially improves attribution quality, outperforming prior methods and matching or exceeding state-of-the-art frontier models.
Hop, Skip, and Overthink: Diagnosing Why Reasoning Models Fumble during Multi-Hop Analysis
Aug 06, 2025The emergence of reasoning models and their integration into practical AI chat bots has led to breakthroughs in solving advanced math, deep search, and extractive question answering problems that requires a complex and multi-step thought process. Yet, a complete understanding of why these models hallucinate more than general purpose language models is missing. In this investigative study, we systematicallyexplore reasoning failures of contemporary language models on multi-hop question answering tasks. We introduce a novel, nuanced error categorization framework that examines failures across three critical dimensions: the diversity and uniqueness of source documents involved ("hops"), completeness in capturing relevant information ("coverage"), and cognitive inefficiency ("overthinking"). Through rigorous hu-man annotation, supported by complementary automated metrics, our exploration uncovers intricate error patterns often hidden by accuracy-centric evaluations. This investigative approach provides deeper insights into the cognitive limitations of current models and offers actionable guidance toward enhancing reasoning fidelity, transparency, and robustness in future language modeling efforts.
A Closer Look at Bias and Chain-of-Thought Faithfulness of Large (Vision) Language Models
May 29, 2025



Chain-of-thought (CoT) reasoning enhances performance of large language models, but questions remain about whether these reasoning traces faithfully reflect the internal processes of the model. We present the first comprehensive study of CoT faithfulness in large vision-language models (LVLMs), investigating how both text-based and previously unexplored image-based biases affect reasoning and bias articulation. Our work introduces a novel, fine-grained evaluation pipeline for categorizing bias articulation patterns, enabling significantly more precise analysis of CoT reasoning than previous methods. This framework reveals critical distinctions in how models process and respond to different types of biases, providing new insights into LVLM CoT faithfulness. Our findings reveal that subtle image-based biases are rarely articulated compared to explicit text-based ones, even in models specialized for reasoning. Additionally, many models exhibit a previously unidentified phenomenon we term ``inconsistent'' reasoning - correctly reasoning before abruptly changing answers, serving as a potential canary for detecting biased reasoning from unfaithful CoTs. We then apply the same evaluation pipeline to revisit CoT faithfulness in LLMs across various levels of implicit cues. Our findings reveal that current language-only reasoning models continue to struggle with articulating cues that are not overtly stated.
Localizing Knowledge in Diffusion Transformers
May 24, 2025Understanding how knowledge is distributed across the layers of generative models is crucial for improving interpretability, controllability, and adaptation. While prior work has explored knowledge localization in UNet-based architectures, Diffusion Transformer (DiT)-based models remain underexplored in this context. In this paper, we propose a model- and knowledge-agnostic method to localize where specific types of knowledge are encoded within the DiT blocks. We evaluate our method on state-of-the-art DiT-based models, including PixArt-alpha, FLUX, and SANA, across six diverse knowledge categories. We show that the identified blocks are both interpretable and causally linked to the expression of knowledge in generated outputs. Building on these insights, we apply our localization framework to two key applications: model personalization and knowledge unlearning. In both settings, our localized fine-tuning approach enables efficient and targeted updates, reducing computational cost, improving task-specific performance, and better preserving general model behavior with minimal interference to unrelated or surrounding content. Overall, our findings offer new insights into the internal structure of DiTs and introduce a practical pathway for more interpretable, efficient, and controllable model editing.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
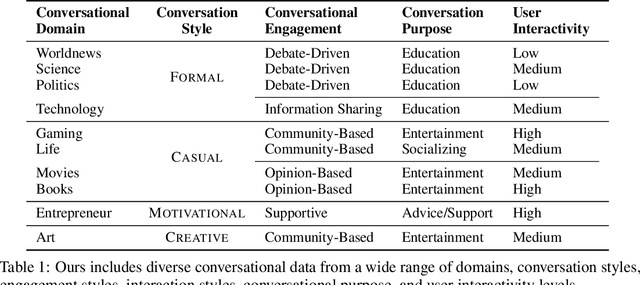


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.