 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIDE: Strategic Trajectory Reasoning via Discriminative Estimation for Verifiable Reinforcement Learning
Jun 14, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become an effective post-training paradigm for improving the reasoning abilities of large language models. However, existing RLVR methods typically rely on final-answer correctness to assign trajectory-level rewards, providing sparse supervision and treating all tokens uniformly regardless of their actual contribution to reasoning. Although recent studies introduce intermediate signals such as process rewards, high-entropy tokens, and semantic uncertainty, these signals are often not inherently verifiable and may fail to distinguish beneficial strategic patterns from harmful ones. To address this limitation, we propose STRIDE (Strategic Trajectory Reasoning with Discriminative Estimation), a fine-grained RLVR framework that derives strategic reasoning supervision from verifiable outcomes. STRIDE contrasts successful and failed trajectories within each response group to estimate the outcome-discriminative preference of each $n$-gram strategic pattern, and further combines this signal with reasoning saliency entropy to identify decision-relevant strategic patterns. These patterns are assigned differentiated advantage values during RL optimization, enabling more precise credit assignment while preserving the verifiability of RLVR. Extensive experiments demonstrate that STRIDE consistently improves reasoning performance across diverse models, tasks, and extended settings, including VLMs and agent-based systems.
On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
Jun 01, 2026Parameter-efficient fine-tuning (PEFT) is usually treated as a cheaper alternative to full fine-tuning. We study a broader role: small trainable adapters as persistent local state on top of strong shared foundation models. In this framing, the base model provides shared competence while adapters carry instance-specific behavior such as preferences, skills, tool habits, and memory-like updates. We organize the problem around three scaling axes: Scale Up, where stronger shared priors make small local updates more useful; Scale Down, where we study how small adapters can be while remaining reliable; and Scale Out, where many persistent adapted instances coexist. MinT provides one infrastructure example for managing adapter identity, revision, provenance, evaluation, and serving residency. Together, the results suggest that PEFT can be a compact substrate for persistent personal models rather than only a budget substitute for full fine-tuning.
GUI Agents for Continual Game Generation
May 27, 2026Generating a game is not the same as making one that can be played. Despite advances in code generation, existing approaches treat game generation as one-shot translation from prompt to artifact, leaving interaction-level failures undetected. We argue that evaluating and improving game generation requires a player, and study two roles for graphical user interface (GUI) agents in this process: (1) as an objective evaluator, for which we introduce PlaytestArena, a new evaluation environment that pairs 200 browser-based game generation tasks across eight genres with rubrics of expected in-play behaviors, adjudicated by a GUI agent that loads each build in a browser and plays it; and (2) as a subjective playtester, for which we propose Play2Code, where a game agent and a GUI agent operate in a sustained loop with shared memory, turning game generation into a dialogue between coding and playing. Our experiments show that even frontier models struggle to generate playable games directly, while Play2Code achieves a 66.8\% rubric pass-rate, improving over single-pass and agentic-coding baselines by 37.1 and 14.6 points respectively. Further analysis shows that GUI playtester feedback is more traceable than a human report, yet idiosyncratic in ways reminiscent of human testers, establishing game playtesting as a critical testbed for interactive code generation. Our project website is available at https://continual-game-generation.vercel.app/.
MinT: Managed Infrastructure for Training and Serving Millions of LLMs
May 13, 2026We present MindLab Toolkit (MinT), a managed infrastructure system for Low-Rank Adaptation (LoRA) post-training and online serving. MinT targets a setting where many trained policies are produced over a small number of expensive base-model deployments. Instead of materializing each policy as a merged full checkpoint, MinT keeps the base model resident and moves exported LoRA adapter revisions through rollout, update, export, evaluation, serving, and rollback, hiding distributed training, serving, scheduling, and data movement behind a service interface. MinT scales this path along three axes. Scale Up extends LoRA RL to frontier-scale dense and MoE architectures, including MLA and DSA attention paths, with training and serving validated beyond 1T total parameters. Scale Down moves only the exported LoRA adapter, which can be under 1% of base-model size in rank-1 settings; adapter-only handoff reduces the measured step by 18.3x on a 4B dense model and 2.85x on a 30B MoE, while concurrent multi-policy GRPO shortens wall time by 1.77x and 1.45x without raising peak memory. Scale Out separates durable policy addressability from CPU/GPU working sets: a tensor-parallel deployment supports 10^6-scale addressable catalogs (measured single-engine sweeps through 100K) and thousand-adapter active waves at cluster scale, with cold loading treated as scheduled service work and packed MoE LoRA tensors improving live engine loading by 8.5-8.7x. MinT thus manages million-scale LoRA policy catalogs while training and serving selected adapter revisions over shared 1T-class base models.
SuperFlow: Training Flow Matching Models with RL on the Fly
Dec 17, 2025Recent progress in flow-based generative models and reinforcement learning (RL) has improved text-image alignment and visual quality. However, current RL training for flow models still has two main problems: (i) GRPO-style fixed per-prompt group sizes ignore variation in sampling importance across prompts, which leads to inefficient sampling and slower training; and (ii) trajectory-level advantages are reused as per-step estimates, which biases credit assignment along the flow. We propose SuperFlow, an RL training framework for flow-based models that adjusts group sizes with variance-aware sampling and computes step-level advantages in a way that is consistent with continuous-time flow dynamics. Empirically, SuperFlow reaches promising performance while using only 5.4% to 56.3% of the original training steps and reduces training time by 5.2% to 16.7% without any architectural changes. On standard text-to-image (T2I) tasks, including text rendering, compositional image generation, and human preference alignment, SuperFlow improves over SD3.5-M by 4.6% to 47.2%, and over Flow-GRPO by 1.7% to 16.0%.
MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
Nov 18, 2025



Evaluating the robustness of Large Vision-Language Models (LVLMs) is essential for their continued development and responsible deployment in real-world applications. However, existing robustness benchmarks typically focus on hallucination or misleading textual inputs, while largely overlooking the equally critical challenge posed by misleading visual inputs in assessing visual understanding. To fill this important gap, we introduce MVI-Bench, the first comprehensive benchmark specially designed for evaluating how Misleading Visual Inputs undermine the robustness of LVLMs. Grounded in fundamental visual primitives, the design of MVI-Bench centers on three hierarchical levels of misleading visual inputs: Visual Concept, Visual Attribute, and Visual Relationship. Using this taxonomy, we curate six representative categories and compile 1,248 expertly annotated VQA instances. To facilitate fine-grained robustness evaluation, we further introduce MVI-Sensitivity, a novel metric that characterizes LVLM robustness at a granular level. Empirical results across 18 state-of-the-art LVLMs uncover pronounced vulnerabilities to misleading visual inputs, and our in-depth analyses on MVI-Bench provide actionable insights that can guide the development of more reliable and robust LVLMs. The benchmark and codebase can be accessed at https://github.com/chenyil6/MVI-Bench.
CoT-X: An Adaptive Framework for Cross-Model Chain-of-Thought Transfer and Optimization
Nov 07, 2025



Chain-of-Thought (CoT) reasoning enhances the problem-solving ability of large language models (LLMs) but leads to substantial inference overhead, limiting deployment in resource-constrained settings. This paper investigates efficient CoT transfer across models of different scales and architectures through an adaptive reasoning summarization framework. The proposed method compresses reasoning traces via semantic segmentation with importance scoring, budget-aware dynamic compression, and coherence reconstruction, preserving critical reasoning steps while significantly reducing token usage. Experiments on 7{,}501 medical examination questions across 10 specialties show up to 40% higher accuracy than truncation under the same token budgets. Evaluations on 64 model pairs from eight LLMs (1.5B-32B parameters, including DeepSeek-R1 and Qwen3) confirm strong cross-model transferability. Furthermore, a Gaussian Process-based Bayesian optimization module reduces evaluation cost by 84% and reveals a power-law relationship between model size and cross-domain robustness. These results demonstrate that reasoning summarization provides a practical path toward efficient CoT transfer, enabling advanced reasoning under tight computational constraints. Code will be released upon publication.
R2I-Bench: Benchmarking Reasoning-Driven Text-to-Image Generation
May 29, 2025

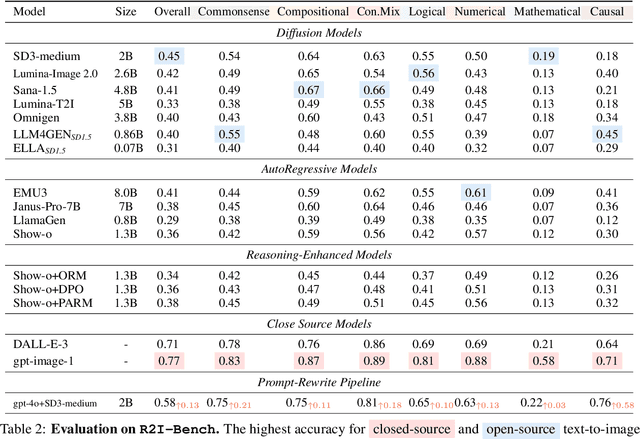

Reasoning is a fundamental capability often required in real-world text-to-image (T2I) generation, e.g., generating ``a bitten apple that has been left in the air for more than a week`` necessitates understanding temporal decay and commonsense concepts. While recent T2I models have made impressive progress in producing photorealistic images, their reasoning capability remains underdeveloped and insufficiently evaluated. To bridge this gap, we introduce R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation. R2I-Bench comprises meticulously curated data instances, spanning core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design R2IScore, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality. Extensive experiments with 16 representative T2I models, including a strong pipeline-based framework that decouples reasoning and generation using the state-of-the-art language and image generation models, demonstrate consistently limited reasoning performance, highlighting the need for more robust, reasoning-aware architectures in the next generation of T2I systems. Project Page: https://r2i-bench.github.io
EvoFlow: Evolving Diverse Agentic Workflows On The Fly
Feb 11, 2025



The past two years have witnessed the evolution of large language model (LLM)-based multi-agent systems from labor-intensive manual design to partial automation (\textit{e.g.}, prompt engineering, communication topology) and eventually to fully automated design. However, existing agentic automation pipelines often lack LLM heterogeneity and focus on single-objective performance optimization, limiting their potential to combine weaker models for more customized and cost-effective solutions. To address this challenge, we propose EvoFlow, a niching evolutionary algorithm-based framework to automatically search a population of heterogeneous and complexity-adaptive agentic workflows, rather than a single homogeneous, complex workflow. Technically, EvoFlow performs \textit{(1) tag-based retrieval} to extract parent workflows from an agentic population, evolves new workflows through \textit{(2) crossover} and \textit{(3) mutation}, and employs \textit{(4) niching-based selection} to maintain population diversity and quality. Extensive evaluations across seven benchmarks demonstrate that EvoFlow is: \textbf{(I) diverse}, evolving a population of workflows ranging from simple I/O tasks to complex multi-turn interactions; \textbf{(II) high-performing}, outperforming previous handcrafted and automated workflows by $1.23\%\sim29.86\%$; \textbf{(III) economical}, surpassing powerful \llmname{o1-preview} at $12.4\%$ of its inference cost using weaker open-source models.