 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Feb 26, 2025



While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
CODESYNC: Synchronizing Large Language Models with Dynamic Code Evolution at Scale
Feb 23, 2025Large Language Models (LLMs) have exhibited exceptional performance in software engineering yet face challenges in adapting to continually evolving code knowledge, particularly regarding the frequent updates of third-party library APIs. This limitation, stemming from static pre-training datasets, often results in non-executable code or implementations with suboptimal safety and efficiency. To this end, this paper introduces CODESYNC, a data engine for identifying outdated code patterns and collecting real-time code knowledge updates from Python third-party libraries. Building upon CODESYNC, we develop CODESYNCBENCH, a comprehensive benchmark for assessing LLMs' ability to stay synchronized with code evolution, which covers real-world updates for 220 APIs from six Python libraries. Our benchmark offers 3,300 test cases across three evaluation tasks and an update-aware instruction tuning dataset consisting of 2,200 training samples. Extensive experiments on 14 state-of-the-art LLMs reveal that they struggle with dynamic code evolution, even with the support of advanced knowledge updating methods (e.g., DPO, ORPO, and SimPO). We believe that our benchmark can offer a strong foundation for the development of more effective methods for real-time code knowledge updating in the future. The experimental code and dataset are publicly available at: https://github.com/Lucky-voyage/Code-Sync.
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Feb 20, 2025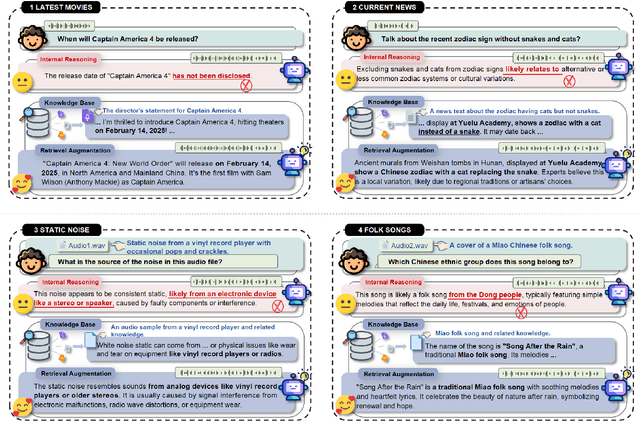
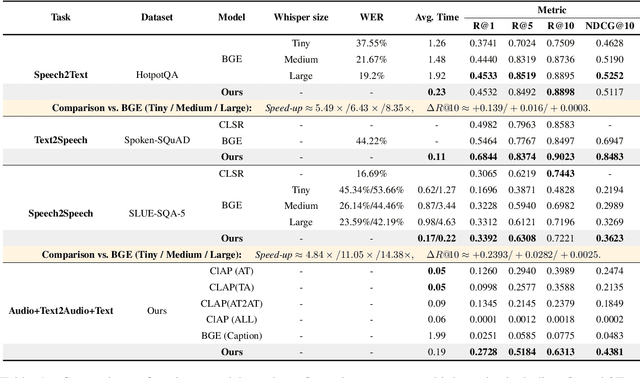
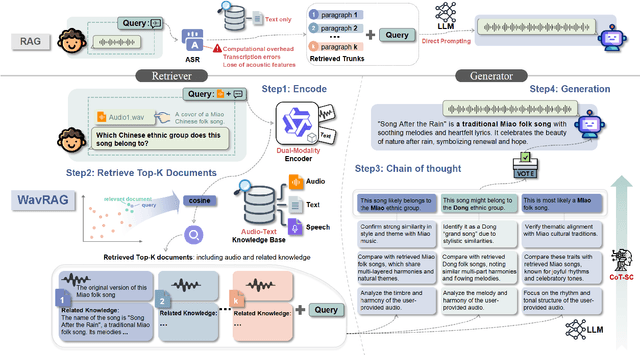
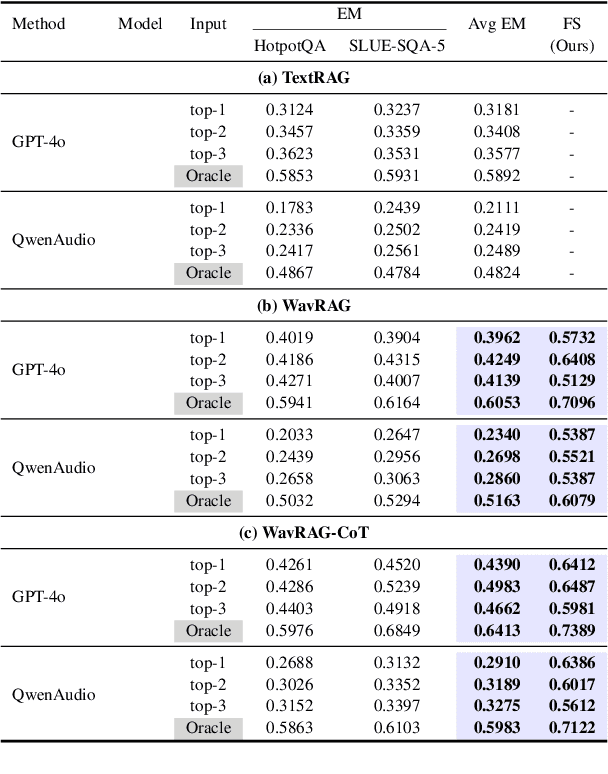
Retrieval Augmented Generation (RAG) has gained widespread adoption owing to its capacity to empower large language models (LLMs) to integrate external knowledge. However, existing RAG frameworks are primarily designed for text-based LLMs and rely on Automatic Speech Recognition to process speech input, which discards crucial audio information, risks transcription errors, and increases computational overhead. Therefore, we introduce WavRAG, the first retrieval augmented generation framework with native, end-to-end audio support. WavRAG offers two key features: 1) Bypassing ASR, WavRAG directly processes raw audio for both embedding and retrieval. 2) WavRAG integrates audio and text into a unified knowledge representation. Specifically, we propose the WavRetriever to facilitate the retrieval from a text-audio hybrid knowledge base, and further enhance the in-context capabilities of spoken dialogue models through the integration of chain-of-thought reasoning. In comparison to state-of-the-art ASR-Text RAG pipelines, WavRAG achieves comparable retrieval performance while delivering a 10x acceleration. Furthermore, WavRAG's unique text-audio hybrid retrieval capability extends the boundaries of RAG to the audio modality.
EAGER-LLM: Enhancing Large Language Models as Recommenders through Exogenous Behavior-Semantic Integration
Feb 20, 2025Large language models (LLMs) are increasingly leveraged as foundational backbones in the development of advanced recommender systems, offering enhanced capabilities through their extensive knowledge and reasoning. Existing llm-based recommender systems (RSs) often face challenges due to the significant differences between the linguistic semantics of pre-trained LLMs and the collaborative semantics essential for RSs. These systems use pre-trained linguistic semantics but learn collaborative semantics from scratch via the llm-Backbone. However, LLMs are not designed for recommendations, leading to inefficient collaborative learning, weak result correlations, and poor integration of traditional RS features. To address these challenges, we propose EAGER-LLM, a decoder-only llm-based generative recommendation framework that integrates endogenous and exogenous behavioral and semantic information in a non-intrusive manner. Specifically, we propose 1)dual-source knowledge-rich item indices that integrates indexing sequences for exogenous signals, enabling efficient link-wide processing; 2)non-invasive multiscale alignment reconstruction tasks guide the model toward a deeper understanding of both collaborative and semantic signals; 3)an annealing adapter designed to finely balance the model's recommendation performance with its comprehension capabilities. We demonstrate EAGER-LLM's effectiveness through rigorous testing on three public benchmarks.
Enhancing Expressive Voice Conversion with Discrete Pitch-Conditioned Flow Matching Model
Feb 08, 2025



This paper introduces PFlow-VC, a conditional flow matching voice conversion model that leverages fine-grained discrete pitch tokens and target speaker prompt information for expressive voice conversion (VC). Previous VC works primarily focus on speaker conversion, with further exploration needed in enhancing expressiveness (such as prosody and emotion) for timbre conversion. Unlike previous methods, we adopt a simple and efficient approach to enhance the style expressiveness of voice conversion models. Specifically, we pretrain a self-supervised pitch VQVAE model to discretize speaker-irrelevant pitch information and leverage a masked pitch-conditioned flow matching model for Mel-spectrogram synthesis, which provides in-context pitch modeling capabilities for the speaker conversion model, effectively improving the voice style transfer capacity. Additionally, we improve timbre similarity by combining global timbre embeddings with time-varying timbre tokens. Experiments on unseen LibriTTS test-clean and emotional speech dataset ESD show the superiority of the PFlow-VC model in both timbre conversion and style transfer. Audio samples are available on the demo page https://speechai-demo.github.io/PFlow-VC/.
Low-rank Prompt Interaction for Continual Vision-Language Retrieval
Jan 24, 2025



Research on continual learning in multi-modal tasks has been receiving increasing attention. However, most existing work overlooks the explicit cross-modal and cross-task interactions. In this paper, we innovatively propose the Low-rank Prompt Interaction (LPI) to address this general problem of multi-modal understanding, which considers both cross-modal and cross-task interactions. Specifically, as for the former, we employ multi-modal correlation modules for corresponding Transformer layers. Considering that the training parameters scale to the number of layers and tasks, we propose low-rank interaction-augmented decomposition to avoid memory explosion while enhancing the cross-modal association through sharing and separating common-specific low-rank factors. In addition, due to the multi-modal semantic differences carried by the low-rank initialization, we adopt hierarchical low-rank contrastive learning to ensure training robustness. As for the latter, we initially employ a visual analysis and identify that different tasks have clear distinctions in proximity. Therefore, we introduce explicit task contrastive constraints in the prompt learning process based on task semantic distances. Experiments on two retrieval tasks show performance improvements with the introduction of a minimal number of parameters, demonstrating the effectiveness of our method. Code is available at https://github.com/Kelvin-ywc/LPI.
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.
Orient Anything: Learning Robust Object Orientation Estimation from Rendering 3D Models
Dec 24, 2024Orientation is a key attribute of objects, crucial for understanding their spatial pose and arrangement in images. However, practical solutions for accurate orientation estimation from a single image remain underexplored. In this work, we introduce Orient Anything, the first expert and foundational model designed to estimate object orientation in a single- and free-view image. Due to the scarcity of labeled data, we propose extracting knowledge from the 3D world. By developing a pipeline to annotate the front face of 3D objects and render images from random views, we collect 2M images with precise orientation annotations. To fully leverage the dataset, we design a robust training objective that models the 3D orientation as probability distributions of three angles and predicts the object orientation by fitting these distributions. Besides, we employ several strategies to improve synthetic-to-real transfer. Our model achieves state-of-the-art orientation estimation accuracy in both rendered and real images and exhibits impressive zero-shot ability in various scenarios. More importantly, our model enhances many applications, such as comprehension and generation of complex spatial concepts and 3D object pose adjustment.
FADA: Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation
Dec 22, 2024



Diffusion-based audio-driven talking avatar methods have recently gained attention for their high-fidelity, vivid, and expressive results. However, their slow inference speed limits practical applications. Despite the development of various distillation techniques for diffusion models, we found that naive diffusion distillation methods do not yield satisfactory results. Distilled models exhibit reduced robustness with open-set input images and a decreased correlation between audio and video compared to teacher models, undermining the advantages of diffusion models. To address this, we propose FADA (Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation). We first designed a mixed-supervised loss to leverage data of varying quality and enhance the overall model capability as well as robustness. Additionally, we propose a multi-CFG distillation with learnable tokens to utilize the correlation between audio and reference image conditions, reducing the threefold inference runs caused by multi-CFG with acceptable quality degradation. Extensive experiments across multiple datasets show that FADA generates vivid videos comparable to recent diffusion model-based methods while achieving an NFE speedup of 4.17-12.5 times. Demos are available at our webpage http://fadavatar.github.io.
Speech Watermarking with Discrete Intermediate Representations
Dec 18, 2024Speech watermarking techniques can proactively mitigate the potential harmful consequences of instant voice cloning techniques. These techniques involve the insertion of signals into speech that are imperceptible to humans but can be detected by algorithms. Previous approaches typically embed watermark messages into continuous space. However, intuitively, embedding watermark information into robust discrete latent space can significantly improve the robustness of watermarking systems. In this paper, we propose DiscreteWM, a novel speech watermarking framework that injects watermarks into the discrete intermediate representations of speech. Specifically, we map speech into discrete latent space with a vector-quantized autoencoder and inject watermarks by changing the modular arithmetic relation of discrete IDs. To ensure the imperceptibility of watermarks, we also propose a manipulator model to select the candidate tokens for watermark embedding. Experimental results demonstrate that our framework achieves state-of-the-art performance in robustness and imperceptibility, simultaneously. Moreover, our flexible frame-wise approach can serve as an efficient solution for both voice cloning detection and information hiding. Additionally, DiscreteWM can encode 1 to 150 bits of watermark information within a 1-second speech clip, indicating its encoding capacity. Audio samples are available at https://DiscreteWM.github.io/discrete_wm.