 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavAlign: Enhancing Intelligence and Expressiveness in Spoken Dialogue Models via Adaptive Hybrid Post-Training
Apr 16, 2026End-to-end spoken dialogue models have garnered significant attention because they offer a higher potential ceiling in expressiveness and perceptual ability than cascaded systems. However, the intelligence and expressiveness of current open-source spoken dialogue models often remain below expectations. Motivated by the success of online reinforcement learning(RL) in other domains, one might attempt to directly apply preference optimization to spoken dialogue models, yet this transfer is non-trivial. We analyze these obstacles from the perspectives of reward modeling and rollout sampling, focusing on how sparse preference supervision interacts with dense speech generation under shared-parameter updates. Based on the analysis, we propose a modality-aware adaptive post-training recipe that makes RL practical for spoken dialogue: it constrains preference updates to the semantic channel and improves acoustic behavior via explicit anchoring, while dynamically regulating their mixture from rollout statistics to avoid unreliable preference gradients. We evaluate the method across multiple spoken dialogue benchmarks and representative architectures, and observe consistent improvements in semantic quality and speech expressiveness.
Dual-Axis Generative Reward Model Toward Semantic and Turn-taking Robustness in Interactive Spoken Dialogue Models
Apr 16, 2026Achieving seamless, human-like interaction remains a key challenge for full-duplex spoken dialogue models (SDMs). Reinforcement learning (RL) has substantially enhanced text- and vision-language models, while well-designed reward signals are crucial for the performance of RL. We consider RL a promising strategy to address the key challenge for SDMs. However, a fundamental barrier persists: prevailing automated metrics for assessing interaction quality rely on superficial proxies, such as behavioral statistics or timing-prediction accuracy, failing to provide reliable reward signals for RL. On the other hand, human evaluations, despite their richness, remain costly, inconsistent, and difficult to scale. We tackle this critical barrier by proposing a Dual-Axis Generative Reward Model, which is trained to understand complex interaction dynamics using a detailed taxonomy and an annotated dataset, produces a single score and, crucially, provides separate evaluations for semantic quality and interaction timing. Such dual outputs furnish precise diagnostic feedback for SDMs and deliver a dependable, instructive reward signal suitable for online reinforcement learning. Our model achieves state-of-the-art performance on interaction-quality assessment across a wide spectrum of datasets, spanning synthetic dialogues and complex real-world interactions.
MolMem: Memory-Augmented Agentic Reinforcement Learning for Sample-Efficient Molecular Optimization
Apr 14, 2026In drug discovery, molecular optimization aims to iteratively refine a lead compound to improve molecular properties while preserving structural similarity to the original molecule. However, each oracle evaluation is expensive, making sample efficiency a key challenge for existing methods under a limited oracle budget. Trial-and-error approaches require many oracle calls, while methods that leverage external knowledge tend to reuse familiar templates and struggle on challenging objectives. A key missing piece is long-term memory that can ground decisions and provide reusable insights for future optimizations. To address this, we present MolMem (\textbf{Mol}ecular optimization with \textbf{Mem}ory), a multi-turn agentic reinforcement learning (RL) framework with a dual-memory system. Specifically, MolMem uses Static Exemplar Memory to retrieve relevant exemplars for cold-start grounding, and Evolving Skill Memory to distill successful trajectories into reusable strategies. Built on this memory-augmented formulation, we train the policy with dense step-wise rewards, turning costly rollouts into long-term knowledge that improves future optimization. Extensive experiments show that MolMem achieves 90\% success on single-property tasks (1.5$\times$ over the best baseline) and 52\% on multi-property tasks using only 500 oracle calls. Our code is available at https://github.com/REAL-Lab-NU/MolMem.
GlassMol: Interpretable Molecular Property Prediction with Concept Bottleneck Models
Mar 01, 2026Machine learning accelerates molecular property prediction, yet state-of-the-art Large Language Models and Graph Neural Networks operate as black boxes. In drug discovery, where safety is critical, this opacity risks masking false correlations and excluding human expertise. Existing interpretability methods suffer from the effectiveness-trustworthiness trade-off: explanations may fail to reflect a model's true reasoning, degrade performance, or lack domain grounding. Concept Bottleneck Models (CBMs) offer a solution by projecting inputs to human-interpretable concepts before readout, ensuring that explanations are inherently faithful to the decision process. However, adapting CBMs to chemistry faces three challenges: the Relevance Gap (selecting task-relevant concepts from a large descriptor space), the Annotation Gap (obtaining concept supervision for molecular data), and the Capacity Gap (degrading performance due to bottleneck constraints). We introduce GlassMol, a model-agnostic CBM that addresses these gaps through automated concept curation and LLM-guided concept selection. Experiments across thirteen benchmarks demonstrate that \method generally matches or exceeds black-box baselines, suggesting that interpretability does not sacrifice performance and challenging the commonly assumed trade-off. Code is available at https://github.com/walleio/GlassMol.
RAPTOR: Ridge-Adaptive Logistic Probes
Jan 29, 2026Probing studies what information is encoded in a frozen LLM's layer representations by training a lightweight predictor on top of them. Beyond analysis, probes are often used operationally in probe-then-steer pipelines: a learned concept vector is extracted from a probe and injected via additive activation steering by adding it to a layer representation during the forward pass. The effectiveness of this pipeline hinges on estimating concept vectors that are accurate, directionally stable under ablation, and inexpensive to obtain. Motivated by these desiderata, we propose RAPTOR (Ridge-Adaptive Logistic Probe), a simple L2-regularized logistic probe whose validation-tuned ridge strength yields concept vectors from normalized weights. Across extensive experiments on instruction-tuned LLMs and human-written concept datasets, RAPTOR matches or exceeds strong baselines in accuracy while achieving competitive directional stability and substantially lower training cost; these quantitative results are supported by qualitative downstream steering demonstrations. Finally, using the Convex Gaussian Min-max Theorem (CGMT), we provide a mechanistic characterization of ridge logistic regression in an idealized Gaussian teacher-student model in the high-dimensional few-shot regime, explaining how penalty strength mediates probe accuracy and concept-vector stability and yielding structural predictions that qualitatively align with trends observed on real LLM embeddings.
Quantum Wavefront Correction via Machine Learning for Satellite-to-Earth CV-QKD
Aug 14, 2025



State-of-the-art free-space continuous-variable quantum key distribution (CV-QKD) protocols use phase reference pulses to modulate the wavefront of a real local oscillator at the receiver, thereby compensating for wavefront distortions caused by atmospheric turbulence. It is normally assumed that the wavefront distortion in these phase reference pulses is identical to the wavefront distortion in the quantum signals, which are multiplexed during transmission. However, in many real-world deployments, there can exist a relative wavefront error (WFE) between the reference pulses and quantum signals, which, among other deleterious effects, can severely limit secure key transfer in satellite-to-Earth CV-QKD. In this work, we introduce novel machine learning-based wavefront correction algorithms, which utilize multi-plane light conversion for decomposition of the reference pulses and quantum signals into the Hermite-Gaussian (HG) basis, then estimate the difference in HG mode phase measurements, effectively eliminating this problem. Through detailed simulations of the Earth-satellite channel, we demonstrate that our new algorithm can rapidly identify and compensate for any relative WFEs that may exist, whilst causing no harm when WFEs are similar across both the reference pulses and quantum signals. We quantify the gains available in our algorithm in terms of the CV-QKD secure key rate. We show channels where positive secure key rates are obtained using our algorithms, while information loss without wavefront correction would result in null key rates.
Spiking Transformers Need High Frequency Information
May 24, 2025Spiking Transformers offer an energy-efficient alternative to conventional deep learning by transmitting information solely through binary (0/1) spikes. However, there remains a substantial performance gap compared to artificial neural networks. A common belief is that their binary and sparse activation transmission leads to information loss, thus degrading feature representation and accuracy. In this work, however, we reveal for the first time that spiking neurons preferentially propagate low-frequency information. We hypothesize that the rapid dissipation of high-frequency components is the primary cause of performance degradation. For example, on Cifar-100, adopting Avg-Pooling (low-pass) for token mixing lowers performance to 76.73%; interestingly, replacing it with Max-Pooling (high-pass) pushes the top-1 accuracy to 79.12%, surpassing the well-tuned Spikformer baseline by 0.97%. Accordingly, we introduce Max-Former that restores high-frequency signals through two frequency-enhancing operators: extra Max-Pooling in patch embedding and Depth-Wise Convolution in place of self-attention. Notably, our Max-Former (63.99 M) hits the top-1 accuracy of 82.39% on ImageNet, showing a +7.58% improvement over Spikformer with comparable model size (74.81%, 66.34 M). We hope this simple yet effective solution inspires future research to explore the distinctive nature of spiking neural networks, beyond the established practice in standard deep learning.
A Survey of Large Language Models for Text-Guided Molecular Discovery: from Molecule Generation to Optimization
May 22, 2025Large language models (LLMs) are introducing a paradigm shift in molecular discovery by enabling text-guided interaction with chemical spaces through natural language, symbolic notations, with emerging extensions to incorporate multi-modal inputs. To advance the new field of LLM for molecular discovery, this survey provides an up-to-date and forward-looking review of the emerging use of LLMs for two central tasks: molecule generation and molecule optimization. Based on our proposed taxonomy for both problems, we analyze representative techniques in each category, highlighting how LLM capabilities are leveraged across different learning settings. In addition, we include the commonly used datasets and evaluation protocols. We conclude by discussing key challenges and future directions, positioning this survey as a resource for researchers working at the intersection of LLMs and molecular science. A continuously updated reading list is available at https://github.com/REAL-Lab-NU/Awesome-LLM-Centric-Molecular-Discovery.
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Feb 20, 2025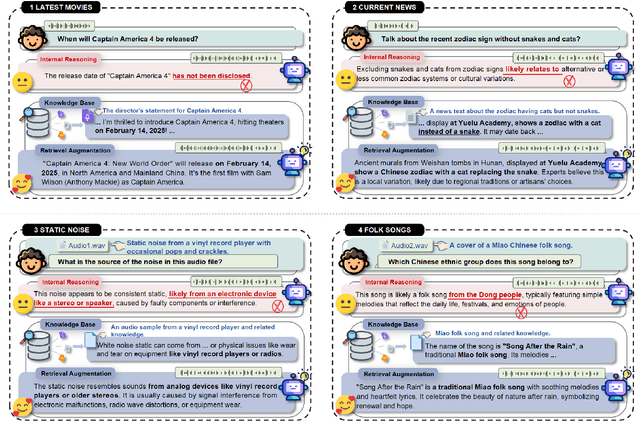
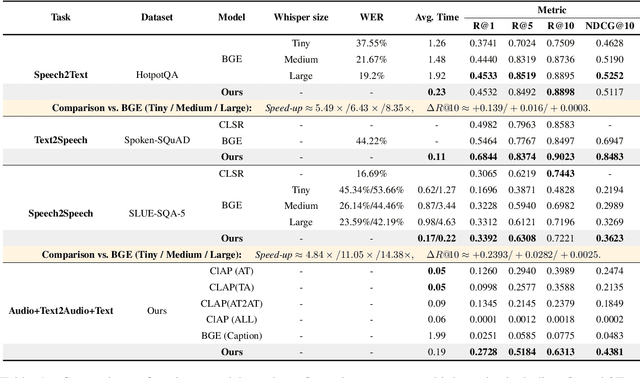
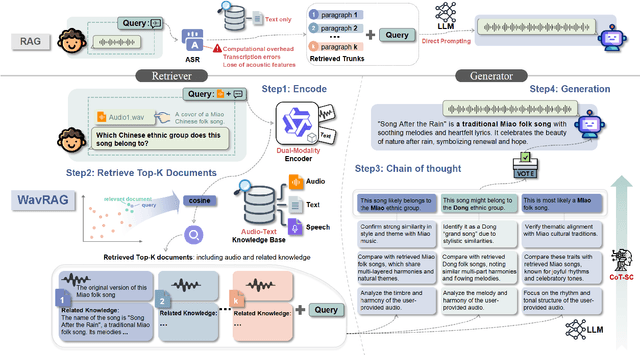
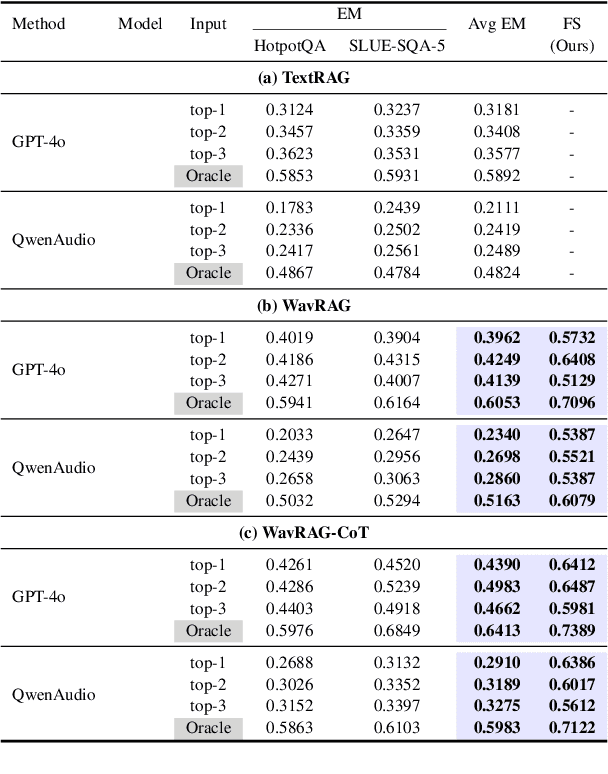
Retrieval Augmented Generation (RAG) has gained widespread adoption owing to its capacity to empower large language models (LLMs) to integrate external knowledge. However, existing RAG frameworks are primarily designed for text-based LLMs and rely on Automatic Speech Recognition to process speech input, which discards crucial audio information, risks transcription errors, and increases computational overhead. Therefore, we introduce WavRAG, the first retrieval augmented generation framework with native, end-to-end audio support. WavRAG offers two key features: 1) Bypassing ASR, WavRAG directly processes raw audio for both embedding and retrieval. 2) WavRAG integrates audio and text into a unified knowledge representation. Specifically, we propose the WavRetriever to facilitate the retrieval from a text-audio hybrid knowledge base, and further enhance the in-context capabilities of spoken dialogue models through the integration of chain-of-thought reasoning. In comparison to state-of-the-art ASR-Text RAG pipelines, WavRAG achieves comparable retrieval performance while delivering a 10x acceleration. Furthermore, WavRAG's unique text-audio hybrid retrieval capability extends the boundaries of RAG to the audio modality.
Adaptive Calibration: A Unified Conversion Framework of Spiking Neural Network
Dec 18, 2024Spiking Neural Networks (SNNs) are seen as an energy-efficient alternative to traditional Artificial Neural Networks (ANNs), but the performance gap remains a challenge. While this gap is narrowing through ANN-to-SNN conversion, substantial computational resources are still needed, and the energy efficiency of converted SNNs cannot be ensured. To address this, we present a unified training-free conversion framework that significantly enhances both the performance and efficiency of converted SNNs. Inspired by the biological nervous system, we propose a novel Adaptive-Firing Neuron Model (AdaFire), which dynamically adjusts firing patterns across different layers to substantially reduce the Unevenness Error - the primary source of error of converted SNNs within limited inference timesteps. We further introduce two efficiency-enhancing techniques: the Sensitivity Spike Compression (SSC) technique for reducing spike operations, and the Input-aware Adaptive Timesteps (IAT) technique for decreasing latency. These methods collectively enable our approach to achieve state-of-the-art performance while delivering significant energy savings of up to 70.1%, 60.3%, and 43.1% on CIFAR-10, CIFAR-100, and ImageNet datasets, respectively. Extensive experiments across 2D, 3D, event-driven classification tasks, object detection, and segmentation tasks, demonstrate the effectiveness of our method in various domains. The code is available at: https://github.com/bic-L/burst-ann2snn.