 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSToM:Causal-oriented Steering for Intrinsic Theory-of-Mind Alignment in Large Language Models
Apr 11, 2026Theory of Mind (ToM), the ability to attribute mental states to others, is a hallmark of social intelligence. While large language models (LLMs) demonstrate promising performance on standard ToM benchmarks, we observe that they often fail to generalize to complex task-specific scenarios, relying heavily on prompt scaffolding to mimic reasoning. The critical misalignment between the internal knowledge and external behavior raises a fundamental question: Do LLMs truly possess intrinsic cognition, and can they externalize this internal knowledge into stable, high-quality behaviors? To answer this, we introduce CoSToM (Causal-oriented Steering for ToM alignment), a framework that transitions from mechanistic interpretation to active intervention. First, we employ causal tracing to map the internal distribution of ToM features, empirically uncovering the internal layers' characteristics in encoding fundamental ToM semantics. Building on this insight, we implement a lightweight alignment framework via targeted activation steering within these ToM-critical layers. Experiments demonstrate that CoSToM significantly enhances human-like social reasoning capabilities and downstream dialogue quality.
code_transformed: The Influence of Large Language Models on Code
Jun 13, 2025Coding remains one of the most fundamental modes of interaction between humans and machines. With the rapid advancement of Large Language Models (LLMs), code generation capabilities have begun to significantly reshape programming practices. This development prompts a central question: Have LLMs transformed code style, and how can such transformation be characterized? In this paper, we present a pioneering study that investigates the impact of LLMs on code style, with a focus on naming conventions, complexity, maintainability, and similarity. By analyzing code from over 19,000 GitHub repositories linked to arXiv papers published between 2020 and 2025, we identify measurable trends in the evolution of coding style that align with characteristics of LLM-generated code. For instance, the proportion of snake\_case variable names in Python code increased from 47% in Q1 2023 to 51% in Q1 2025. Furthermore, we investigate how LLMs approach algorithmic problems by examining their reasoning processes. Given the diversity of LLMs and usage scenarios, among other factors, it is difficult or even impossible to precisely estimate the proportion of code generated or assisted by LLMs. Our experimental results provide the first large-scale empirical evidence that LLMs affect real-world programming style.
CODESYNC: Synchronizing Large Language Models with Dynamic Code Evolution at Scale
Feb 23, 2025Large Language Models (LLMs) have exhibited exceptional performance in software engineering yet face challenges in adapting to continually evolving code knowledge, particularly regarding the frequent updates of third-party library APIs. This limitation, stemming from static pre-training datasets, often results in non-executable code or implementations with suboptimal safety and efficiency. To this end, this paper introduces CODESYNC, a data engine for identifying outdated code patterns and collecting real-time code knowledge updates from Python third-party libraries. Building upon CODESYNC, we develop CODESYNCBENCH, a comprehensive benchmark for assessing LLMs' ability to stay synchronized with code evolution, which covers real-world updates for 220 APIs from six Python libraries. Our benchmark offers 3,300 test cases across three evaluation tasks and an update-aware instruction tuning dataset consisting of 2,200 training samples. Extensive experiments on 14 state-of-the-art LLMs reveal that they struggle with dynamic code evolution, even with the support of advanced knowledge updating methods (e.g., DPO, ORPO, and SimPO). We believe that our benchmark can offer a strong foundation for the development of more effective methods for real-time code knowledge updating in the future. The experimental code and dataset are publicly available at: https://github.com/Lucky-voyage/Code-Sync.
Hyperbolic Hypergraph Neural Networks for Multi-Relational Knowledge Hypergraph Representation
Dec 11, 2024



Knowledge hypergraphs generalize knowledge graphs using hyperedges to connect multiple entities and depict complicated relations. Existing methods either transform hyperedges into an easier-to-handle set of binary relations or view hyperedges as isolated and ignore their adjacencies. Both approaches have information loss and may potentially lead to the creation of sub-optimal models. To fix these issues, we propose the Hyperbolic Hypergraph Neural Network (H2GNN), whose essential component is the hyper-star message passing, a novel scheme motivated by a lossless expansion of hyperedges into hierarchies. It implements a direct embedding that consciously incorporates adjacent entities, hyper-relations, and entity position-aware information. As the name suggests, H2GNN operates in the hyperbolic space, which is more adept at capturing the tree-like hierarchy. We compare H2GNN with 15 baselines on knowledge hypergraphs, and it outperforms state-of-the-art approaches in both node classification and link prediction tasks.
CANDY: A Benchmark for Continuous Approximate Nearest Neighbor Search with Dynamic Data Ingestion
Jun 28, 2024



Approximate K Nearest Neighbor (AKNN) algorithms play a pivotal role in various AI applications, including information retrieval, computer vision, and natural language processing. Although numerous AKNN algorithms and benchmarks have been developed recently to evaluate their effectiveness, the dynamic nature of real-world data presents significant challenges that existing benchmarks fail to address. Traditional benchmarks primarily assess retrieval effectiveness in static contexts and often overlook update efficiency, which is crucial for handling continuous data ingestion. This limitation results in an incomplete assessment of an AKNN algorithms ability to adapt to changing data patterns, thereby restricting insights into their performance in dynamic environments. To address these gaps, we introduce CANDY, a benchmark tailored for Continuous Approximate Nearest Neighbor Search with Dynamic Data Ingestion. CANDY comprehensively assesses a wide range of AKNN algorithms, integrating advanced optimizations such as machine learning-driven inference to supplant traditional heuristic scans, and improved distance computation methods to reduce computational overhead. Our extensive evaluations across diverse datasets demonstrate that simpler AKNN baselines often surpass more complex alternatives in terms of recall and latency. These findings challenge established beliefs about the necessity of algorithmic complexity for high performance. Furthermore, our results underscore existing challenges and illuminate future research opportunities. We have made the datasets and implementation methods available at: https://github.com/intellistream/candy.
Generalization-Enhanced Code Vulnerability Detection via Multi-Task Instruction Fine-Tuning
Jun 06, 2024



Code Pre-trained Models (CodePTMs) based vulnerability detection have achieved promising results over recent years. However, these models struggle to generalize as they typically learn superficial mapping from source code to labels instead of understanding the root causes of code vulnerabilities, resulting in poor performance in real-world scenarios beyond the training instances. To tackle this challenge, we introduce VulLLM, a novel framework that integrates multi-task learning with Large Language Models (LLMs) to effectively mine deep-seated vulnerability features. Specifically, we construct two auxiliary tasks beyond the vulnerability detection task. First, we utilize the vulnerability patches to construct a vulnerability localization task. Second, based on the vulnerability features extracted from patches, we leverage GPT-4 to construct a vulnerability interpretation task. VulLLM innovatively augments vulnerability classification by leveraging generative LLMs to understand complex vulnerability patterns, thus compelling the model to capture the root causes of vulnerabilities rather than overfitting to spurious features of a single task. The experiments conducted on six large datasets demonstrate that VulLLM surpasses seven state-of-the-art models in terms of effectiveness, generalization, and robustness.
Iterative Refinement of Project-Level Code Context for Precise Code Generation with Compiler Feedback
Apr 02, 2024



Large language models (LLMs) have shown remarkable progress in automated code generation. Yet, incorporating LLM-based code generation into real-life software projects poses challenges, as the generated code may contain errors in API usage, class, data structure, or missing project-specific information. As much of this project-specific context cannot fit into the prompts of LLMs, we must find ways to allow the model to explore the project-level code context. To this end, this paper puts forward a novel approach, termed ProCoder, which iteratively refines the project-level code context for precise code generation, guided by the compiler feedback. In particular, ProCoder first leverages compiler techniques to identify a mismatch between the generated code and the project's context. It then iteratively aligns and fixes the identified errors using information extracted from the code repository. We integrate ProCoder with two representative LLMs, i.e., GPT-3.5-Turbo and Code Llama (13B), and apply it to Python code generation. Experimental results show that ProCoder significantly improves the vanilla LLMs by over 80% in generating code dependent on project context, and consistently outperforms the existing retrieval-based code generation baselines.
Scalable Optimal Margin Distribution Machine
May 08, 2023Optimal margin Distribution Machine (ODM) is a newly proposed statistical learning framework rooting in the novel margin theory, which demonstrates better generalization performance than the traditional large margin based counterparts. Nonetheless, it suffers from the ubiquitous scalability problem regarding both computation time and memory as other kernel methods. This paper proposes a scalable ODM, which can achieve nearly ten times speedup compared to the original ODM training method. For nonlinear kernels, we propose a novel distribution-aware partition method to make the local ODM trained on each partition be close and converge fast to the global one. When linear kernel is applied, we extend a communication efficient SVRG method to accelerate the training further. Extensive empirical studies validate that our proposed method is highly computational efficient and almost never worsen the generalization.
Semantic and Syntactic Enhanced Aspect Sentiment Triplet Extraction
Jun 07, 2021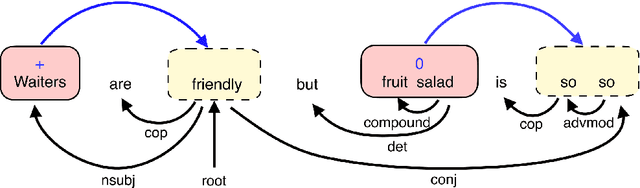

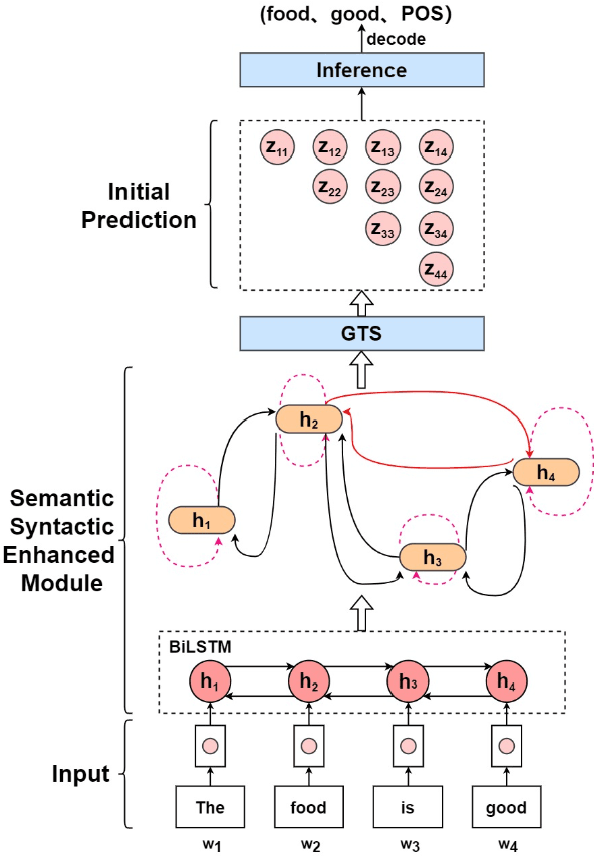
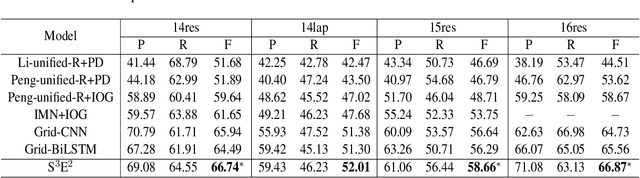
Aspect Sentiment Triplet Extraction (ASTE) aims to extract triplets from sentences, where each triplet includes an entity, its associated sentiment, and the opinion span explaining the reason for the sentiment. Most existing research addresses this problem in a multi-stage pipeline manner, which neglects the mutual information between such three elements and has the problem of error propagation. In this paper, we propose a Semantic and Syntactic Enhanced aspect Sentiment triplet Extraction model (S3E2) to fully exploit the syntactic and semantic relationships between the triplet elements and jointly extract them. Specifically, we design a Graph-Sequence duel representation and modeling paradigm for the task of ASTE: we represent the semantic and syntactic relationships between word pairs in a sentence by graph and encode it by Graph Neural Networks (GNNs), as well as modeling the original sentence by LSTM to preserve the sequential information. Under this setting, we further apply a more efficient inference strategy for the extraction of triplets. Extensive evaluations on four benchmark datasets show that S3E2 significantly outperforms existing approaches, which proves our S3E2's superiority and flexibility in an end-to-end fashion.