 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Co-Training with Explainable Cell Graph Ensembling for Histopathological Image Classification
Aug 24, 2023



Convolutional neural networks excel in histopathological image classification, yet their pixel-level focus hampers explainability. Conversely, emerging graph convolutional networks spotlight cell-level features and medical implications. However, limited by their shallowness and suboptimal use of high-dimensional pixel data, GCNs underperform in multi-class histopathological image classification. To make full use of pixel-level and cell-level features dynamically, we propose an asymmetric co-training framework combining a deep graph convolutional network and a convolutional neural network for multi-class histopathological image classification. To improve the explainability of the entire framework by embedding morphological and topological distribution of cells, we build a 14-layer deep graph convolutional network to handle cell graph data. For the further utilization and dynamic interactions between pixel-level and cell-level information, we also design a co-training strategy to integrate the two asymmetric branches. Notably, we collect a private clinically acquired dataset termed LUAD7C, including seven subtypes of lung adenocarcinoma, which is rare and more challenging. We evaluated our approach on the private LUAD7C and public colorectal cancer datasets, showcasing its superior performance, explainability, and generalizability in multi-class histopathological image classification.
i2LQR: Iterative LQR for Iterative Tasks in Dynamic Environments
Mar 17, 2023



This work introduces a novel control strategy called Iterative Linear Quadratic Regulator for Iterative Tasks (i2LQR), which aims to pursue optimal performance for iterative tasks in a dynamic environment. The proposed algorithm is reference-free and utilizes historical data from previous iterations to enhance the performance of the autonomous system. Unlike existing algorithms, the i2LQR computes the optimal solution in an iterative manner at each timestamp, rendering it well-suited for iterative tasks with changing constraints at different iterations. To evaluate the performance of the proposed algorithm, we conduct numerical simulations for an iterative task aimed at minimizing completion time. The results show that i2LQR achieves the optimal performance as the state-of-the-art algorithm in static environments, and outperforms the state-of-the-art algorithm in dynamic environments with both static and dynamics obstacles.
Robust and Versatile Bipedal Jumping Control through Multi-Task Reinforcement Learning
Feb 19, 2023



This work aims to push the limits of agility for bipedal robots by enabling a torque-controlled bipedal robot to perform robust and versatile dynamic jumps in the real world. We present a multi-task reinforcement learning framework to train the robot to accomplish a large variety of jumping tasks, such as jumping to different locations and directions. To improve performance on these challenging tasks, we develop a new policy structure that encodes the robot's long-term input/output (I/O) history while also providing direct access to its short-term I/O history. In order to train a versatile multi-task policy, we utilize a multi-stage training scheme that includes different training stages for different objectives. After multi-stage training, the multi-task policy can be directly transferred to Cassie, a physical bipedal robot. Training on different tasks and exploring more diverse scenarios leads to highly robust policies that can exploit the diverse set of learned skills to recover from perturbations or poor landings during real-world deployment. Such robustness in the proposed multi-task policy enables Cassie to succeed in completing a variety of challenging jump tasks in the real world, such as standing long jumps, jumping onto elevated platforms, and multi-axis jumps.
Walking in Narrow Spaces: Safety-critical Locomotion Control for Quadrupedal Robots with Duality-based Optimization
Dec 29, 2022This paper presents a safety-critical locomotion control framework for quadrupedal robots. Our goal is to enable quadrupedal robots to safely navigate in cluttered environments. To tackle this, we introduce exponential Discrete Control Barrier Functions (exponential DCBFs) with duality-based obstacle avoidance constraints into a Nonlinear Model Predictive Control (NMPC) with Whole-Body Control (WBC) framework for quadrupedal locomotion control. This enables us to use polytopes to describe the shapes of the robot and obstacles for collision avoidance while doing locomotion control of quadrupedal robots. Compared to most prior work, especially using CBFs, that utilize spherical and conservative approximation for obstacle avoidance, this work demonstrates a quadrupedal robot autonomously and safely navigating through very tight spaces in the real world. (Our open-source code is available at github.com/HybridRobotics/quadruped_nmpc_dcbf_duality, and the video is available at youtu.be/p1gSQjwXm1Q.)
Creating a Dynamic Quadrupedal Robotic Goalkeeper with Reinforcement Learning
Oct 10, 2022
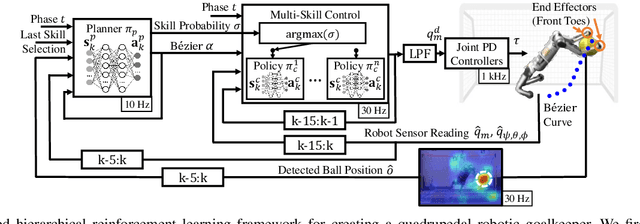
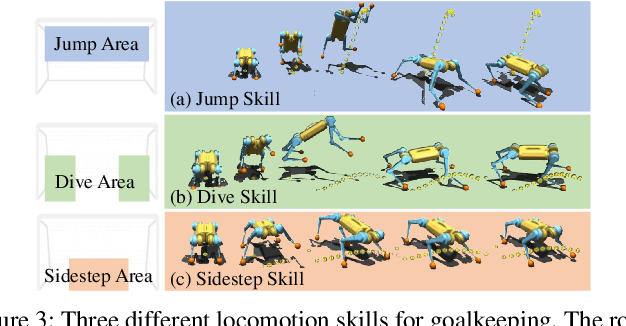
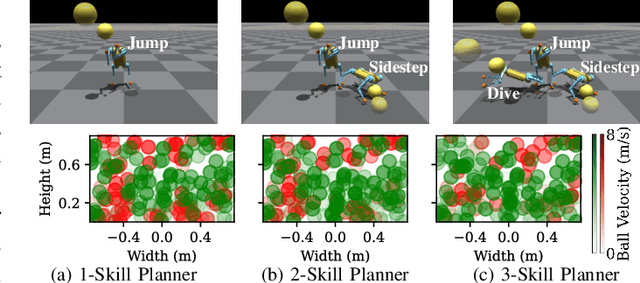
We present a reinforcement learning (RL) framework that enables quadrupedal robots to perform soccer goalkeeping tasks in the real world. Soccer goalkeeping using quadrupeds is a challenging problem, that combines highly dynamic locomotion with precise and fast non-prehensile object (ball) manipulation. The robot needs to react to and intercept a potentially flying ball using dynamic locomotion maneuvers in a very short amount of time, usually less than one second. In this paper, we propose to address this problem using a hierarchical model-free RL framework. The first component of the framework contains multiple control policies for distinct locomotion skills, which can be used to cover different regions of the goal. Each control policy enables the robot to track random parametric end-effector trajectories while performing one specific locomotion skill, such as jump, dive, and sidestep. These skills are then utilized by the second part of the framework which is a high-level planner to determine a desired skill and end-effector trajectory in order to intercept a ball flying to different regions of the goal. We deploy the proposed framework on a Mini Cheetah quadrupedal robot and demonstrate the effectiveness of our framework for various agile interceptions of a fast-moving ball in the real world.
GenLoco: Generalized Locomotion Controllers for Quadrupedal Robots
Sep 12, 2022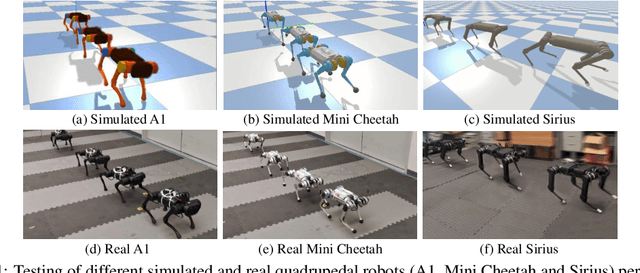

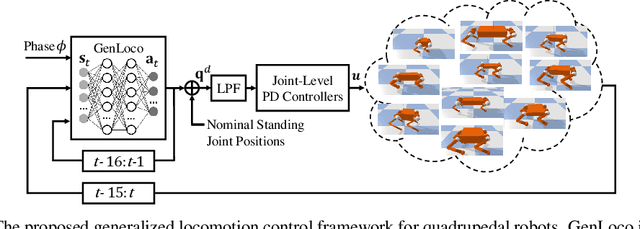

Recent years have seen a surge in commercially-available and affordable quadrupedal robots, with many of these platforms being actively used in research and industry. As the availability of legged robots grows, so does the need for controllers that enable these robots to perform useful skills. However, most learning-based frameworks for controller development focus on training robot-specific controllers, a process that needs to be repeated for every new robot. In this work, we introduce a framework for training generalized locomotion (GenLoco) controllers for quadrupedal robots. Our framework synthesizes general-purpose locomotion controllers that can be deployed on a large variety of quadrupedal robots with similar morphologies. We present a simple but effective morphology randomization method that procedurally generates a diverse set of simulated robots for training. We show that by training a controller on this large set of simulated robots, our models acquire more general control strategies that can be directly transferred to novel simulated and real-world robots with diverse morphologies, which were not observed during training.
Hierarchical Reinforcement Learning for Precise Soccer Shooting Skills using a Quadrupedal Robot
Aug 01, 2022
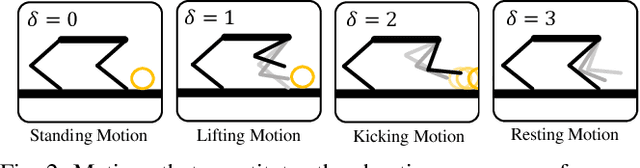
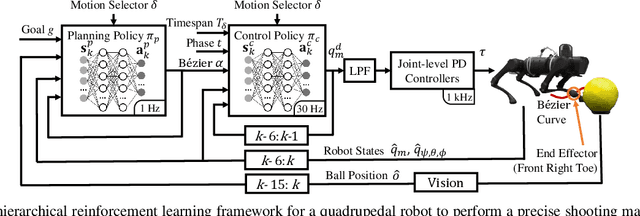
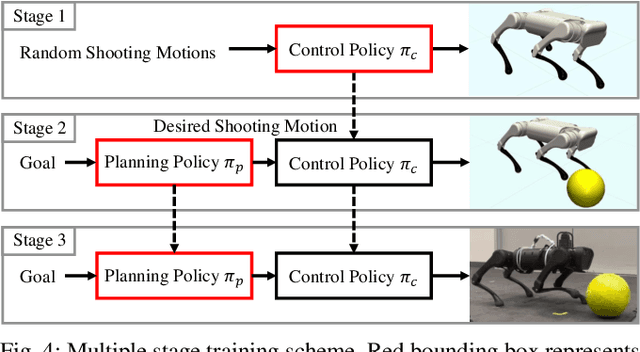
We address the problem of enabling quadrupedal robots to perform precise shooting skills in the real world using reinforcement learning. Developing algorithms to enable a legged robot to shoot a soccer ball to a given target is a challenging problem that combines robot motion control and planning into one task. To solve this problem, we need to consider the dynamics limitation and motion stability during the control of a dynamic legged robot. Moreover, we need to consider motion planning to shoot the hard-to-model deformable ball rolling on the ground with uncertain friction to a desired location. In this paper, we propose a hierarchical framework that leverages deep reinforcement learning to train (a) a robust motion control policy that can track arbitrary motions and (b) a planning policy to decide the desired kicking motion to shoot a soccer ball to a target. We deploy the proposed framework on an A1 quadrupedal robot and enable it to accurately shoot the ball to random targets in the real world.
Key-frame Guided Network for Thyroid Nodule Recognition using Ultrasound Videos
Jun 30, 2022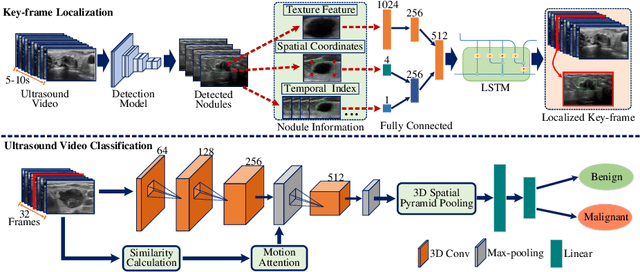
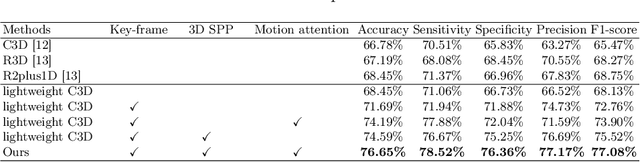
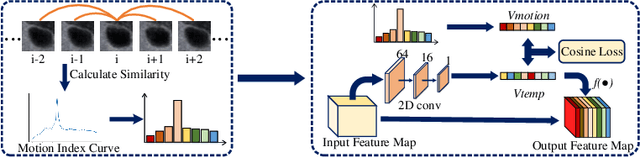
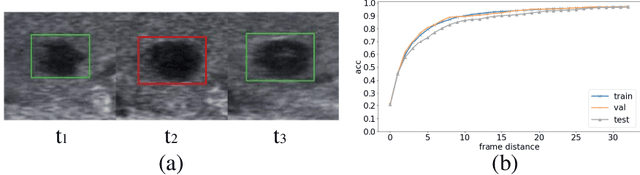
Ultrasound examination is widely used in the clinical diagnosis of thyroid nodules (benign/malignant). However, the accuracy relies heavily on radiologist experience. Although deep learning techniques have been investigated for thyroid nodules recognition. Current solutions are mainly based on static ultrasound images, with limited temporal information used and inconsistent with clinical diagnosis. This paper proposes a novel method for the automated recognition of thyroid nodules through an exhaustive exploration of ultrasound videos and key-frames. We first propose a detection-localization framework to automatically identify the clinical key-frame with a typical nodule in each ultrasound video. Based on the localized key-frame, we develop a key-frame guided video classification model for thyroid nodule recognition. Besides, we introduce a motion attention module to help the network focus on significant frames in an ultrasound video, which is consistent with clinical diagnosis. The proposed thyroid nodule recognition framework is validated on clinically collected ultrasound videos, demonstrating superior performance compared with other state-of-the-art methods.
Collaborative Navigation and Manipulation of a Cable-towed Load by Multiple Quadrupedal Robots
Jun 29, 2022
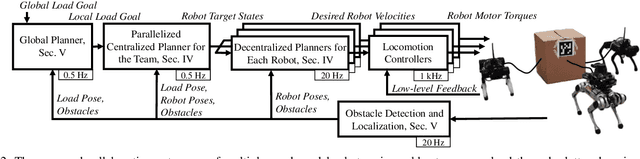
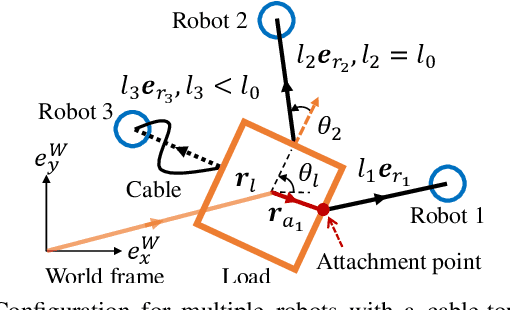
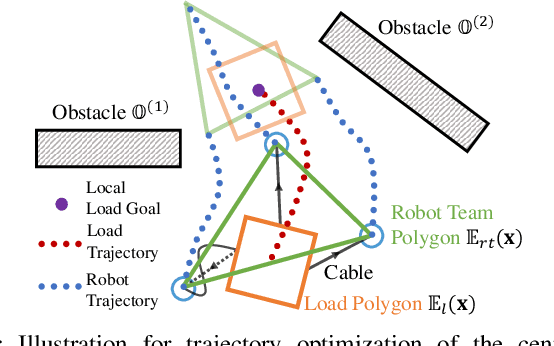
This paper tackles the problem of robots collaboratively towing a load with cables to a specified goal location while avoiding collisions in real time. The introduction of cables (as opposed to rigid links) enables the robotic team to travel through narrow spaces by changing its intrinsic dimensions through slack/taut switches of the cable. However, this is a challenging problem because of the hybrid mode switches and the dynamical coupling among multiple robots and the load. Previous attempts at addressing such a problem were performed offline and do not consider avoiding obstacles online. In this paper, we introduce a cascaded planning scheme with a parallelized centralized trajectory optimization that deals with hybrid mode switches. We additionally develop a set of decentralized planners per robot, which enables our approach to solve the problem of collaborative load manipulation online. We develop and demonstrate one of the first collaborative autonomy framework that is able to move a cable-towed load, which is too heavy to move by a single robot, through narrow spaces with real-time feedback and reactive planning in experiments.
Adapting Rapid Motor Adaptation for Bipedal Robots
May 30, 2022
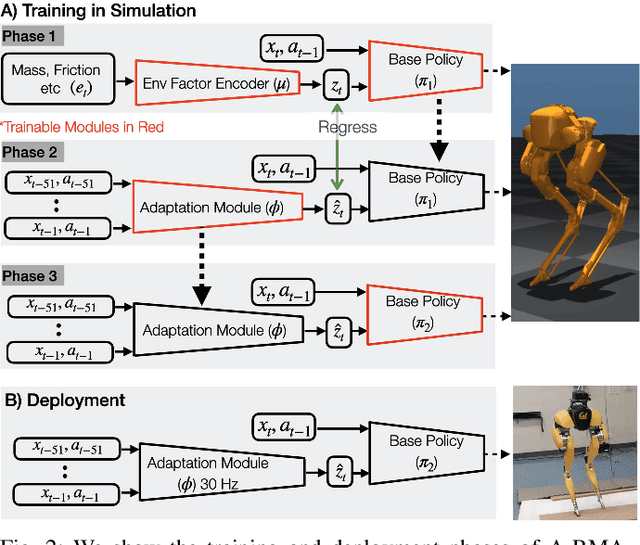
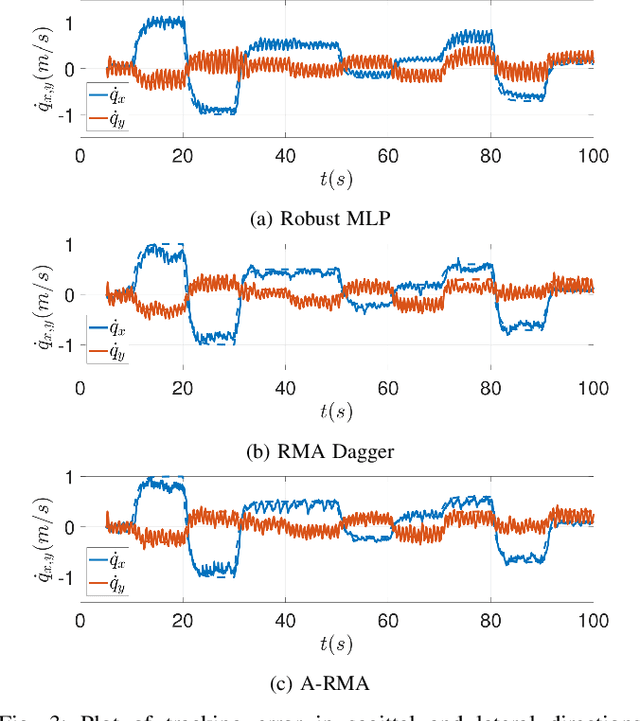
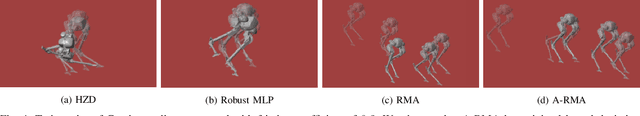
Recent advances in legged locomotion have enabled quadrupeds to walk on challenging terrains. However, bipedal robots are inherently more unstable and hence it's harder to design walking controllers for them. In this work, we leverage recent advances in rapid adaptation for locomotion control, and extend them to work on bipedal robots. Similar to existing works, we start with a base policy which produces actions while taking as input an estimated extrinsics vector from an adaptation module. This extrinsics vector contains information about the environment and enables the walking controller to rapidly adapt online. However, the extrinsics estimator could be imperfect, which might lead to poor performance of the base policy which expects a perfect estimator. In this paper, we propose A-RMA (Adapting RMA), which additionally adapts the base policy for the imperfect extrinsics estimator by finetuning it using model-free RL. We demonstrate that A-RMA outperforms a number of RL-based baseline controllers and model-based controllers in simulation, and show zero-shot deployment of a single A-RMA policy to enable a bipedal robot, Cassie, to walk in a variety of different scenarios in the real world beyond what it has seen during training. Videos and results at https://ashish-kmr.github.io/a-rma/