 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Low-Level Visual Hallucinations Requires Self-Awareness: Database, Model and Training Strategy
Mar 27, 2025



The rapid development of multimodal large language models has resulted in remarkable advancements in visual perception and understanding, consolidating several tasks into a single visual question-answering framework. However, these models are prone to hallucinations, which limit their reliability as artificial intelligence systems. While this issue is extensively researched in natural language processing and image captioning, there remains a lack of investigation of hallucinations in Low-level Visual Perception and Understanding (HLPU), especially in the context of image quality assessment tasks. We consider that these hallucinations arise from an absence of clear self-awareness within the models. To address this issue, we first introduce the HLPU instruction database, the first instruction database specifically focused on hallucinations in low-level vision tasks. This database contains approximately 200K question-answer pairs and comprises four subsets, each covering different types of instructions. Subsequently, we propose the Self-Awareness Failure Elimination (SAFEQA) model, which utilizes image features, salient region features and quality features to improve the perception and comprehension abilities of the model in low-level vision tasks. Furthermore, we propose the Enhancing Self-Awareness Preference Optimization (ESA-PO) framework to increase the model's awareness of knowledge boundaries, thereby mitigating the incidence of hallucination. Finally, we conduct comprehensive experiments on low-level vision tasks, with the results demonstrating that our proposed method significantly enhances self-awareness of the model in these tasks and reduces hallucinations. Notably, our proposed method improves both accuracy and self-awareness of the proposed model and outperforms close-source models in terms of various evaluation metrics.
An Optimization-Based Inverse Kinematics Solver for Continuum Manipulators in Intricate Environments
Oct 27, 2024



Continuum manipulators have gained significant attention as a promising alternative to rigid manipulators, offering notable advantages in terms of flexibility and adaptability within intricate workspace. However, the broader application of high degree-of-freedom (DoF) continuum manipulators in intricate environments with multiple obstacles necessitates the development of an efficient inverse kinematics (IK) solver specifically tailored for such scenarios. Existing IK methods face challenges in terms of computational cost and solution guarantees for high DoF continuum manipulators, particularly within intricate workspace that obstacle avoidance is needed. To address these challenges, we have developed a novel IK solver for continuum manipulators that incorporates obstacle avoidance and other constraints like length, orientation, etc., in intricate environments, drawing inspiration from optimization-based path planning methods. Through simulations, our proposed method showcases superior flexibility, efficiency with increasing DoF, and robust performance within highly unstructured workspace, achieved with acceptable latency.
AIM 2024 Challenge on Video Super-Resolution Quality Assessment: Methods and Results
Oct 05, 2024



This paper presents the Video Super-Resolution (SR) Quality Assessment (QA) Challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. The task of this challenge was to develop an objective QA method for videos upscaled 2x and 4x by modern image- and video-SR algorithms. QA methods were evaluated by comparing their output with aggregate subjective scores collected from >150,000 pairwise votes obtained through crowd-sourced comparisons across 52 SR methods and 1124 upscaled videos. The goal was to advance the state-of-the-art in SR QA, which had proven to be a challenging problem with limited applicability of traditional QA methods. The challenge had 29 registered participants, and 5 teams had submitted their final results, all outperforming the current state-of-the-art. All data, including the private test subset, has been made publicly available on the challenge homepage at https://challenges.videoprocessing.ai/challenges/super-resolution-metrics-challenge.html
Explore the Hallucination on Low-level Perception for MLLMs
Sep 15, 2024



The rapid development of Multi-modality Large Language Models (MLLMs) has significantly influenced various aspects of industry and daily life, showcasing impressive capabilities in visual perception and understanding. However, these models also exhibit hallucinations, which limit their reliability as AI systems, especially in tasks involving low-level visual perception and understanding. We believe that hallucinations stem from a lack of explicit self-awareness in these models, which directly impacts their overall performance. In this paper, we aim to define and evaluate the self-awareness of MLLMs in low-level visual perception and understanding tasks. To this end, we present QL-Bench, a benchmark settings to simulate human responses to low-level vision, investigating self-awareness in low-level visual perception through visual question answering related to low-level attributes such as clarity and lighting. Specifically, we construct the LLSAVisionQA dataset, comprising 2,990 single images and 1,999 image pairs, each accompanied by an open-ended question about its low-level features. Through the evaluation of 15 MLLMs, we demonstrate that while some models exhibit robust low-level visual capabilities, their self-awareness remains relatively underdeveloped. Notably, for the same model, simpler questions are often answered more accurately than complex ones. However, self-awareness appears to improve when addressing more challenging questions. We hope that our benchmark will motivate further research, particularly focused on enhancing the self-awareness of MLLMs in tasks involving low-level visual perception and understanding.
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024



Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
How is Visual Attention Influenced by Text Guidance? Database and Model
Apr 12, 2024



The analysis and prediction of visual attention have long been crucial tasks in the fields of computer vision and image processing. In practical applications, images are generally accompanied by various text descriptions, however, few studies have explored the influence of text descriptions on visual attention, let alone developed visual saliency prediction models considering text guidance. In this paper, we conduct a comprehensive study on text-guided image saliency (TIS) from both subjective and objective perspectives. Specifically, we construct a TIS database named SJTU-TIS, which includes 1200 text-image pairs and the corresponding collected eye-tracking data. Based on the established SJTU-TIS database, we analyze the influence of various text descriptions on visual attention. Then, to facilitate the development of saliency prediction models considering text influence, we construct a benchmark for the established SJTU-TIS database using state-of-the-art saliency models. Finally, considering the effect of text descriptions on visual attention, while most existing saliency models ignore this impact, we further propose a text-guided saliency (TGSal) prediction model, which extracts and integrates both image features and text features to predict the image saliency under various text-description conditions. Our proposed model significantly outperforms the state-of-the-art saliency models on both the SJTU-TIS database and the pure image saliency databases in terms of various evaluation metrics. The SJTU-TIS database and the code of the proposed TGSal model will be released at: https://github.com/IntMeGroup/TGSal.
TikTokActions: A TikTok-Derived Video Dataset for Human Action Recognition
Feb 14, 2024



The increasing variety and quantity of tagged multimedia content on platforms such as TikTok provides an opportunity to advance computer vision modeling. We have curated a distinctive dataset of 283,582 unique video clips categorized under 386 hashtags relating to modern human actions. We release this dataset as a valuable resource for building domain-specific foundation models for human movement modeling tasks such as action recognition. To validate this dataset, which we name TikTokActions, we perform two sets of experiments. First, we pretrain the state-of-the-art VideoMAEv2 with a ViT-base backbone on TikTokActions subset, and then fine-tune and evaluate on popular datasets such as UCF101 and the HMDB51. We find that the performance of the model pre-trained using our Tik-Tok dataset is comparable to models trained on larger action recognition datasets (95.3% on UCF101 and 53.24% on HMDB51). Furthermore, our investigation into the relationship between pre-training dataset size and fine-tuning performance reveals that beyond a certain threshold, the incremental benefit of larger training sets diminishes. This work introduces a useful TikTok video dataset that is available for public use and provides insights into the marginal benefit of increasing pre-training dataset sizes for video-based foundation models.
Hierarchical Reinforcement Learning for Precise Soccer Shooting Skills using a Quadrupedal Robot
Aug 01, 2022
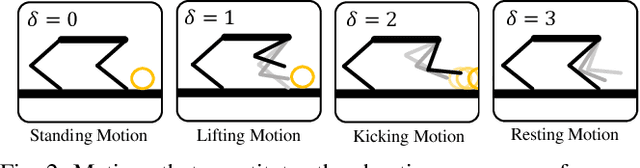
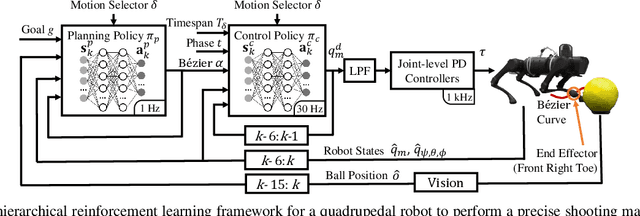
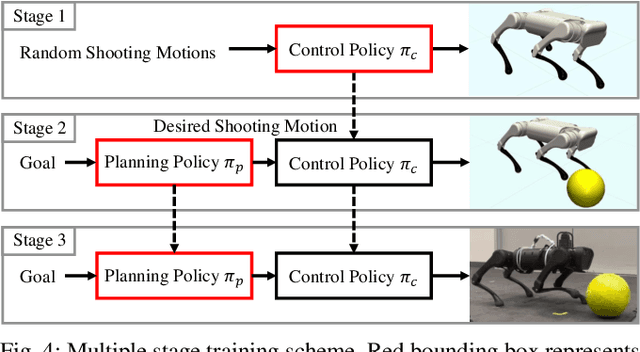
We address the problem of enabling quadrupedal robots to perform precise shooting skills in the real world using reinforcement learning. Developing algorithms to enable a legged robot to shoot a soccer ball to a given target is a challenging problem that combines robot motion control and planning into one task. To solve this problem, we need to consider the dynamics limitation and motion stability during the control of a dynamic legged robot. Moreover, we need to consider motion planning to shoot the hard-to-model deformable ball rolling on the ground with uncertain friction to a desired location. In this paper, we propose a hierarchical framework that leverages deep reinforcement learning to train (a) a robust motion control policy that can track arbitrary motions and (b) a planning policy to decide the desired kicking motion to shoot a soccer ball to a target. We deploy the proposed framework on an A1 quadrupedal robot and enable it to accurately shoot the ball to random targets in the real world.
A Validated Physical Model For Real-Time Simulation of Soft Robotic Snakes
Apr 05, 2019
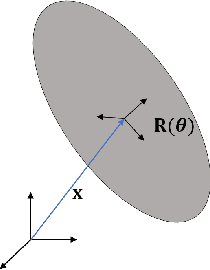


In this work we present a framework that is capable of accurately representing soft robotic actuators in a multiphysics environment in real-time. We propose a constraint-based dynamics model of a 1-dimensional pneumatic soft actuator that accounts for internal pressure forces, as well as the effect of actuator latency and damping under inflation and deflation and demonstrate its accuracy a full soft robotic snake with the composition of multiple 1D actuators. We verify our model's accuracy in static deformation and dynamic locomotion open-loop control experiments. To achieve real-time performance we leverage the parallel computation power of GPUs to allow interactive control and feedback.