 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedFM-Robust: Benchmarking Robustness of Medical Foundation Models
May 21, 2026Medical foundation models (MedFMs) have emerged as transformative tools in healthcare, demonstrating capabilities across diverse clinical applications. These models can be broadly categorized into two paradigms: Medical Vision-Language Models (Med-VLMs) and segmentation foundation models. Med-VLMs range from medical-specialized models such as LLaVA-Med and MedGemma, to general-purpose models like GPT-4o and Gemini, all capable of medical image understanding tasks including visual question answering (VQA), report generation, and visual grounding. Concurrently, the Segment Anything Model (SAM) has catalyzed a new generation of medical segmentation models, with adaptations like SAM-Med2D and MedSAM. The widespread clinical deployment of these models thus necessitates rigorous evaluation of their reliability under real-world conditions.
The Compositional Architecture of Regret in Large Language Models
Jun 18, 2025



Regret in Large Language Models refers to their explicit regret expression when presented with evidence contradicting their previously generated misinformation. Studying the regret mechanism is crucial for enhancing model reliability and helps in revealing how cognition is coded in neural networks. To understand this mechanism, we need to first identify regret expressions in model outputs, then analyze their internal representation. This analysis requires examining the model's hidden states, where information processing occurs at the neuron level. However, this faces three key challenges: (1) the absence of specialized datasets capturing regret expressions, (2) the lack of metrics to find the optimal regret representation layer, and (3) the lack of metrics for identifying and analyzing regret neurons. Addressing these limitations, we propose: (1) a workflow for constructing a comprehensive regret dataset through strategically designed prompting scenarios, (2) the Supervised Compression-Decoupling Index (S-CDI) metric to identify optimal regret representation layers, and (3) the Regret Dominance Score (RDS) metric to identify regret neurons and the Group Impact Coefficient (GIC) to analyze activation patterns. Our experimental results successfully identified the optimal regret representation layer using the S-CDI metric, which significantly enhanced performance in probe classification experiments. Additionally, we discovered an M-shaped decoupling pattern across model layers, revealing how information processing alternates between coupling and decoupling phases. Through the RDS metric, we categorized neurons into three distinct functional groups: regret neurons, non-regret neurons, and dual neurons.
Variable-frame CNNLSTM for Breast Nodule Classification using Ultrasound Videos
Feb 17, 2025



The intersection of medical imaging and artificial intelligence has become an important research direction in intelligent medical treatment, particularly in the analysis of medical images using deep learning for clinical diagnosis. Despite the advances, existing keyframe classification methods lack extraction of time series features, while ultrasonic video classification based on three-dimensional convolution requires uniform frame numbers across patients, resulting in poor feature extraction efficiency and model classification performance. This study proposes a novel video classification method based on CNN and LSTM, introducing NLP's long and short sentence processing scheme into video classification for the first time. The method reduces CNN-extracted image features to 1x512 dimension, followed by sorting and compressing feature vectors for LSTM training. Specifically, feature vectors are sorted by patient video frame numbers and populated with padding value 0 to form variable batches, with invalid padding values compressed before LSTM training to conserve computing resources. Experimental results demonstrate that our variable-frame CNNLSTM method outperforms other approaches across all metrics, showing improvements of 3-6% in F1 score and 1.5% in specificity compared to keyframe methods. The variable-frame CNNLSTM also achieves better accuracy and precision than equal-frame CNNLSTM. These findings validate the effectiveness of our approach in classifying variable-frame ultrasound videos and suggest potential applications in other medical imaging modalities.
Key-frame Guided Network for Thyroid Nodule Recognition using Ultrasound Videos
Jun 30, 2022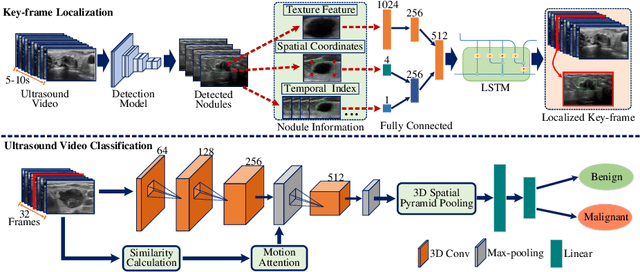
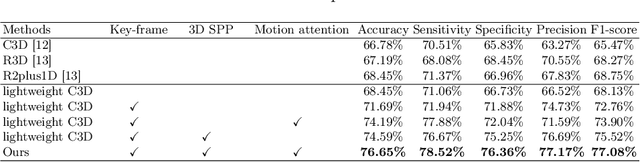
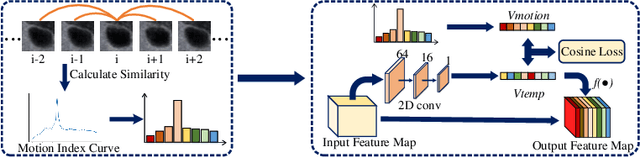
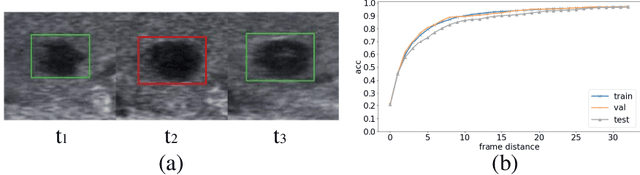
Ultrasound examination is widely used in the clinical diagnosis of thyroid nodules (benign/malignant). However, the accuracy relies heavily on radiologist experience. Although deep learning techniques have been investigated for thyroid nodules recognition. Current solutions are mainly based on static ultrasound images, with limited temporal information used and inconsistent with clinical diagnosis. This paper proposes a novel method for the automated recognition of thyroid nodules through an exhaustive exploration of ultrasound videos and key-frames. We first propose a detection-localization framework to automatically identify the clinical key-frame with a typical nodule in each ultrasound video. Based on the localized key-frame, we develop a key-frame guided video classification model for thyroid nodule recognition. Besides, we introduce a motion attention module to help the network focus on significant frames in an ultrasound video, which is consistent with clinical diagnosis. The proposed thyroid nodule recognition framework is validated on clinically collected ultrasound videos, demonstrating superior performance compared with other state-of-the-art methods.