 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Robots to Span the Space of Functional Expressive Motion
Mar 04, 2022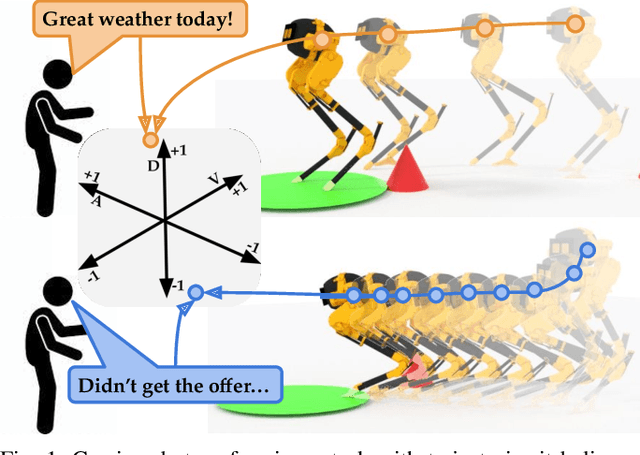
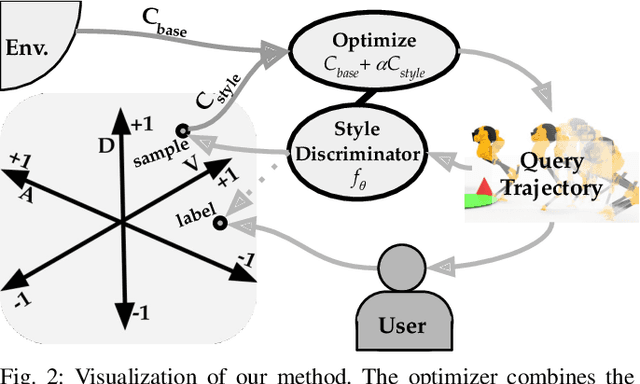
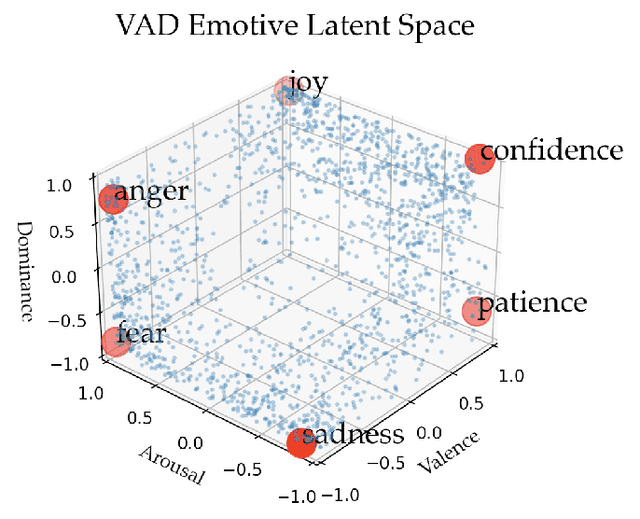

Our goal is to enable robots to perform functional tasks in emotive ways, be it in response to their users' emotional states, or expressive of their confidence levels. Prior work has proposed learning independent cost functions from user feedback for each target emotion, so that the robot may optimize it alongside task and environment specific objectives for any situation it encounters. However, this approach is inefficient when modeling multiple emotions and unable to generalize to new ones. In this work, we leverage the fact that emotions are not independent of each other: they are related through a latent space of Valence-Arousal-Dominance (VAD). Our key idea is to learn a model for how trajectories map onto VAD with user labels. Considering the distance between a trajectory's mapping and a target VAD allows this single model to represent cost functions for all emotions. As a result 1) all user feedback can contribute to learning about every emotion; 2) the robot can generate trajectories for any emotion in the space instead of only a few predefined ones; and 3) the robot can respond emotively to user-generated natural language by mapping it to a target VAD. We introduce a method that interactively learns to map trajectories to this latent space and test it in simulation and in a user study. In experiments, we use a simple vacuum robot as well as the Cassie biped.
Dynamically Switching Human Prediction Models for Efficient Planning
Mar 13, 2021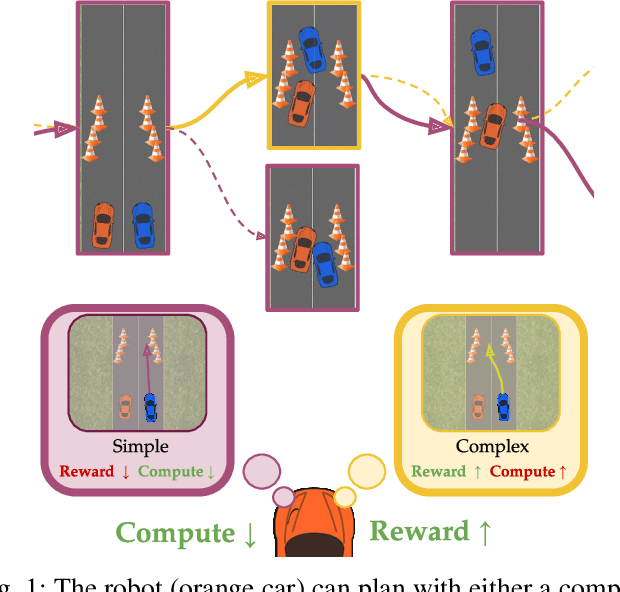
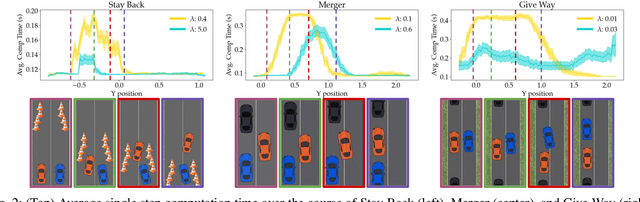
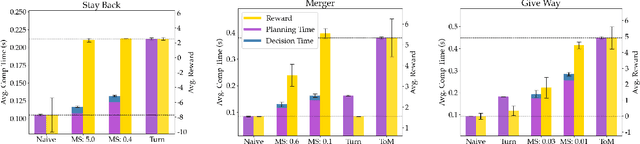
As environments involving both robots and humans become increasingly common, so does the need to account for people during planning. To plan effectively, robots must be able to respond to and sometimes influence what humans do. This requires a human model which predicts future human actions. A simple model may assume the human will continue what they did previously; a more complex one might predict that the human will act optimally, disregarding the robot; whereas an even more complex one might capture the robot's ability to influence the human. These models make different trade-offs between computational time and performance of the resulting robot plan. Using only one model of the human either wastes computational resources or is unable to handle critical situations. In this work, we give the robot access to a suite of human models and enable it to assess the performance-computation trade-off online. By estimating how an alternate model could improve human prediction and how that may translate to performance gain, the robot can dynamically switch human models whenever the additional computation is justified. Our experiments in a driving simulator showcase how the robot can achieve performance comparable to always using the best human model, but with greatly reduced computation.