 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiLMa-Res: A General Hierarchical Framework via Residual RL for Combining Quadrupedal Locomotion and Manipulation
Jul 09, 2024



This work presents HiLMa-Res, a hierarchical framework leveraging reinforcement learning to tackle manipulation tasks while performing continuous locomotion using quadrupedal robots. Unlike most previous efforts that focus on solving a specific task, HiLMa-Res is designed to be general for various loco-manipulation tasks that require quadrupedal robots to maintain sustained mobility. The novel design of this framework tackles the challenges of integrating continuous locomotion control and manipulation using legs. It develops an operational space locomotion controller that can track arbitrary robot end-effector (toe) trajectories while walking at different velocities. This controller is designed to be general to different downstream tasks, and therefore, can be utilized in high-level manipulation planning policy to address specific tasks. To demonstrate the versatility of this framework, we utilize HiLMa-Res to tackle several challenging loco-manipulation tasks using a quadrupedal robot in the real world. These tasks span from leveraging state-based policy to vision-based policy, from training purely from the simulation data to learning from real-world data. In these tasks, HiLMa-Res shows better performance than other methods.
Creating a Dynamic Quadrupedal Robotic Goalkeeper with Reinforcement Learning
Oct 10, 2022
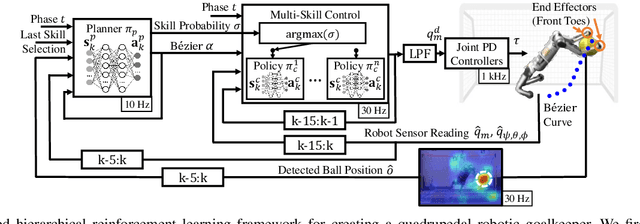
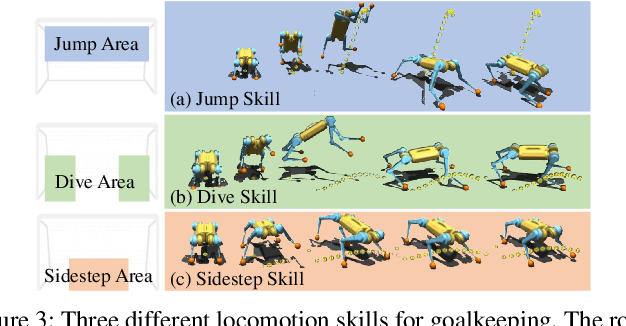
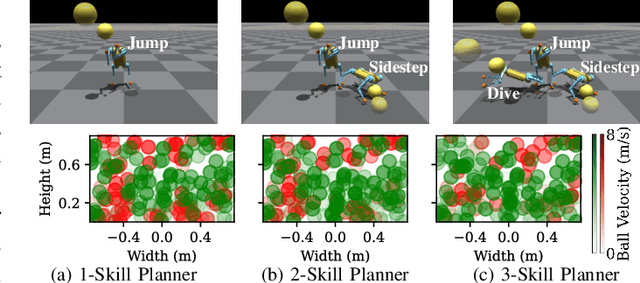
We present a reinforcement learning (RL) framework that enables quadrupedal robots to perform soccer goalkeeping tasks in the real world. Soccer goalkeeping using quadrupeds is a challenging problem, that combines highly dynamic locomotion with precise and fast non-prehensile object (ball) manipulation. The robot needs to react to and intercept a potentially flying ball using dynamic locomotion maneuvers in a very short amount of time, usually less than one second. In this paper, we propose to address this problem using a hierarchical model-free RL framework. The first component of the framework contains multiple control policies for distinct locomotion skills, which can be used to cover different regions of the goal. Each control policy enables the robot to track random parametric end-effector trajectories while performing one specific locomotion skill, such as jump, dive, and sidestep. These skills are then utilized by the second part of the framework which is a high-level planner to determine a desired skill and end-effector trajectory in order to intercept a ball flying to different regions of the goal. We deploy the proposed framework on a Mini Cheetah quadrupedal robot and demonstrate the effectiveness of our framework for various agile interceptions of a fast-moving ball in the real world.
Distribution Aware Metrics for Conditional Natural Language Generation
Sep 29, 2022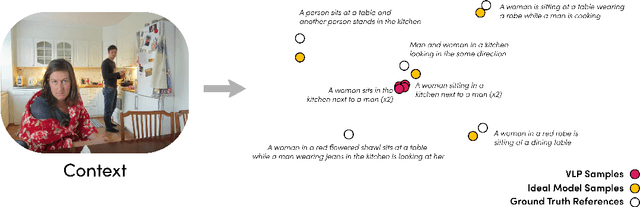
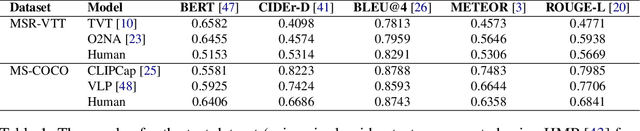
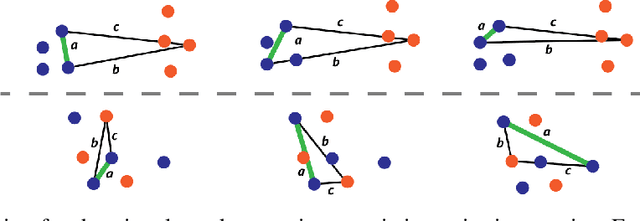

Traditional automated metrics for evaluating conditional natural language generation use pairwise comparisons between a single generated text and the best-matching gold-standard ground truth text. When multiple ground truths are available, scores are aggregated using an average or max operation across references. While this approach works well when diversity in the ground truth data (i.e. dispersion of the distribution of conditional texts) can be ascribed to noise, such as in automated speech recognition, it does not allow for robust evaluation in the case where diversity in the ground truths represents signal for the model. In this work we argue that existing metrics are not appropriate for domains such as visual description or summarization where ground truths are semantically diverse, and where the diversity in those captions captures useful additional information about the context. We propose a novel paradigm for multi-candidate evaluation of conditional language generation models, and a new family of metrics that compare the distributions of reference and model-generated caption sets using small sample sets of each. We demonstrate the utility of our approach with a case study in visual description: where we show that existing models optimize for single-description quality over diversity, and gain some insights into how sampling methods and temperature impact description quality and diversity.