 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
DiffSpectra: Molecular Structure Elucidation from Spectra using Diffusion Models
Jul 09, 2025Molecular structure elucidation from spectra is a foundational problem in chemistry, with profound implications for compound identification, synthesis, and drug development. Traditional methods rely heavily on expert interpretation and lack scalability. Pioneering machine learning methods have introduced retrieval-based strategies, but their reliance on finite libraries limits generalization to novel molecules. Generative models offer a promising alternative, yet most adopt autoregressive SMILES-based architectures that overlook 3D geometry and struggle to integrate diverse spectral modalities. In this work, we present DiffSpectra, a generative framework that directly infers both 2D and 3D molecular structures from multi-modal spectral data using diffusion models. DiffSpectra formulates structure elucidation as a conditional generation process. Its denoising network is parameterized by Diffusion Molecule Transformer, an SE(3)-equivariant architecture that integrates topological and geometric information. Conditioning is provided by SpecFormer, a transformer-based spectral encoder that captures intra- and inter-spectral dependencies from multi-modal spectra. Extensive experiments demonstrate that DiffSpectra achieves high accuracy in structure elucidation, recovering exact structures with 16.01% top-1 accuracy and 96.86% top-20 accuracy through sampling. The model benefits significantly from 3D geometric modeling, SpecFormer pre-training, and multi-modal conditioning. These results highlight the effectiveness of spectrum-conditioned diffusion modeling in addressing the challenge of molecular structure elucidation. To our knowledge, DiffSpectra is the first framework to unify multi-modal spectral reasoning and joint 2D/3D generative modeling for de novo molecular structure elucidation.
Accelerating Diffusion Large Language Models with SlowFast: The Three Golden Principles
Jun 12, 2025



Diffusion-based language models (dLLMs) have emerged as a promising alternative to traditional autoregressive LLMs by enabling parallel token generation and significantly reducing inference latency. However, existing sampling strategies for dLLMs, such as confidence-based or semi-autoregressive decoding, often suffer from static behavior, leading to suboptimal efficiency and limited flexibility. In this paper, we propose SlowFast Sampling, a novel dynamic sampling strategy that adaptively alternates between exploratory and accelerated decoding stages. Our method is guided by three golden principles: certainty principle, convergence principle, and positional principle, which govern when and where tokens can be confidently and efficiently decoded. We further integrate our strategy with dLLM-Cache to reduce redundant computation. Extensive experiments across benchmarks and models show that SlowFast Sampling achieves up to 15.63$\times$ speedup on LLaDA with minimal accuracy drop, and up to 34.22$\times$ when combined with caching. Notably, our approach outperforms strong autoregressive baselines like LLaMA3 8B in throughput, demonstrating that well-designed sampling can unlock the full potential of dLLMs for fast and high-quality generation.
KG-Infused RAG: Augmenting Corpus-Based RAG with External Knowledge Graphs
Jun 11, 2025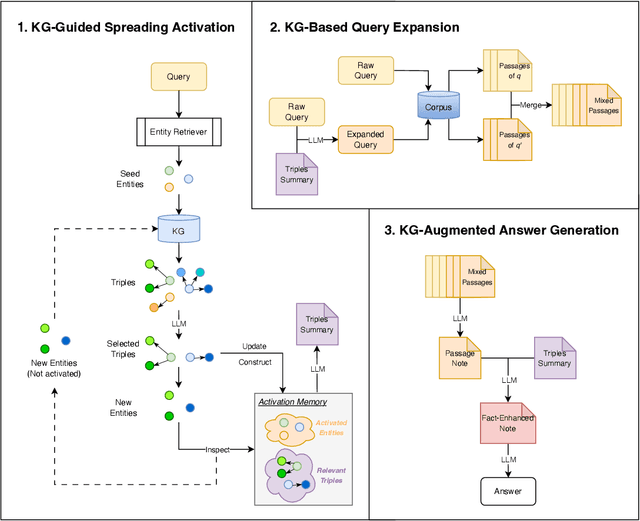
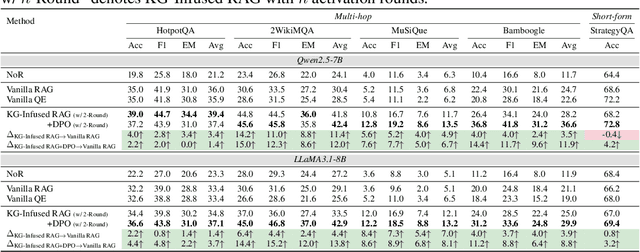
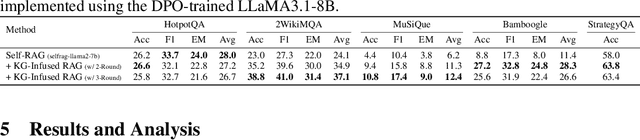
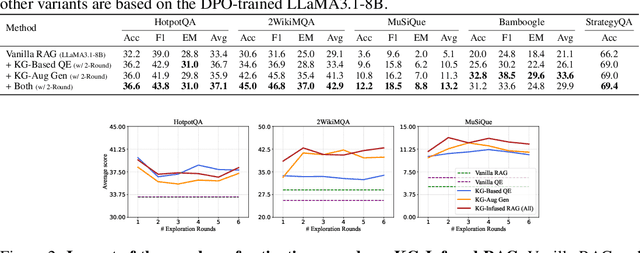
Retrieval-Augmented Generation (RAG) improves factual accuracy by grounding responses in external knowledge. However, existing methods typically rely on a single source, either unstructured text or structured knowledge. Moreover, they lack cognitively inspired mechanisms for activating relevant knowledge. To address these issues, we propose KG-Infused RAG, a framework that integrates KGs into RAG systems to implement spreading activation, a cognitive process that enables concept association and inference. KG-Infused RAG retrieves KG facts, expands the query accordingly, and enhances generation by combining corpus passages with structured facts, enabling interpretable, multi-source retrieval grounded in semantic structure. We further improve KG-Infused RAG via preference learning on sampled key stages in the pipeline. Experiments on five QA benchmarks show that KG-Infused RAG consistently outperforms vanilla RAG (by 3.8% to 13.8%). Additionally, when integrated into Self-RAG, KG-Infused RAG brings further performance gains, demonstrating its effectiveness and versatility as a plug-and-play enhancement module for corpus-based RAG methods.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Learning to Focus: Causal Attention Distillation via Gradient-Guided Token Pruning
Jun 09, 2025Large language models (LLMs) have demonstrated significant improvements in contextual understanding. However, their ability to attend to truly critical information during long-context reasoning and generation still falls behind the pace. Specifically, our preliminary experiments reveal that certain distracting patterns can misdirect the model's attention during inference, and removing these patterns substantially improves reasoning accuracy and generation quality. We attribute this phenomenon to spurious correlations in the training data, which obstruct the model's capacity to infer authentic causal instruction-response relationships. This phenomenon may induce redundant reasoning processes, potentially resulting in significant inference overhead and, more critically, the generation of erroneous or suboptimal responses. To mitigate this, we introduce a two-stage framework called Learning to Focus (LeaF) leveraging intervention-based inference to disentangle confounding factors. In the first stage, LeaF employs gradient-based comparisons with an advanced teacher to automatically identify confounding tokens based on causal relationships in the training corpus. Then, in the second stage, it prunes these tokens during distillation to enact intervention, aligning the student's attention with the teacher's focus distribution on truly critical context tokens. Experimental results demonstrate that LeaF not only achieves an absolute improvement in various mathematical reasoning and code generation benchmarks but also effectively suppresses attention to confounding tokens during inference, yielding a more interpretable and reliable reasoning model.
TextVidBench: A Benchmark for Long Video Scene Text Understanding
Jun 05, 2025Despite recent progress on the short-video Text-Visual Question Answering (ViteVQA) task - largely driven by benchmarks such as M4-ViteVQA - existing datasets still suffer from limited video duration and narrow evaluation scopes, making it difficult to adequately assess the growing capabilities of powerful multimodal large language models (MLLMs). To address these limitations, we introduce TextVidBench, the first benchmark specifically designed for long-video text question answering (>3 minutes). TextVidBench makes three key contributions: 1) Cross-domain long-video coverage: Spanning 9 categories (e.g., news, sports, gaming), with an average video length of 2306 seconds, enabling more realistic evaluation of long-video understanding. 2) A three-stage evaluation framework: "Text Needle-in-Haystack -> Temporal Grounding -> Text Dynamics Captioning". 3) High-quality fine-grained annotations: Containing over 5,000 question-answer pairs with detailed semantic labeling. Furthermore, we propose an efficient paradigm for improving large models through: (i) introducing the IT-Rope mechanism and temporal prompt engineering to enhance temporal perception, (ii) adopting non-uniform positional encoding to better handle long video sequences, and (iii) applying lightweight fine-tuning on video-text data. Extensive experiments on multiple public datasets as well as TextVidBench demonstrate that our new benchmark presents significant challenges to existing models, while our proposed method offers valuable insights into improving long-video scene text understanding capabilities.
ClueAnchor: Clue-Anchored Knowledge Reasoning Exploration and Optimization for Retrieval-Augmented Generation
May 30, 2025Retrieval-Augmented Generation (RAG) augments Large Language Models (LLMs) with external knowledge to improve factuality. However, existing RAG systems frequently underutilize the retrieved documents, failing to extract and integrate the key clues needed to support faithful and interpretable reasoning, especially in cases where relevant evidence is implicit, scattered, or obscured by noise. To address this issue, we propose ClueAnchor, a novel framework for enhancing RAG via clue-anchored reasoning exploration and optimization. ClueAnchor extracts key clues from retrieved content and generates multiple reasoning paths based on different knowledge configurations, optimizing the model by selecting the most effective one through reward-based preference optimization. Experiments show that ClueAnchor significantly outperforms prior RAG baselines in reasoning completeness and robustness. Further analysis confirms its strong resilience to noisy or partially relevant retrieved content, as well as its capability to identify supporting evidence even in the absence of explicit clue supervision during inference.
A*-Thought: Efficient Reasoning via Bidirectional Compression for Low-Resource Settings
May 30, 2025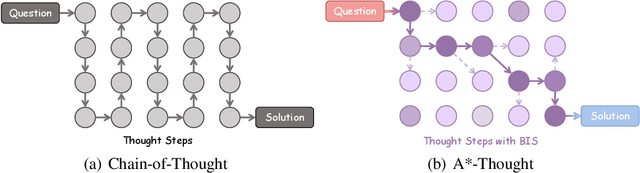
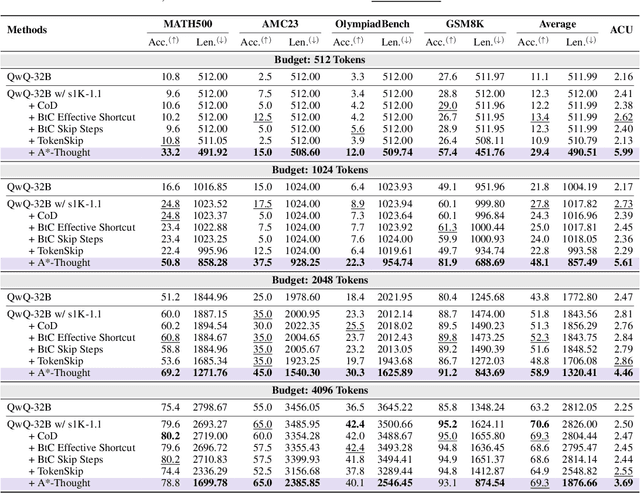
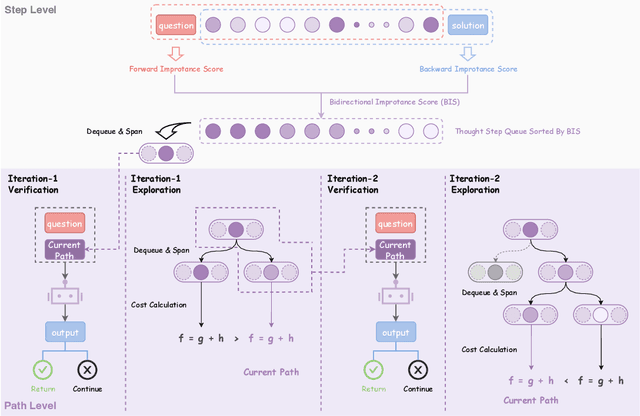

Large Reasoning Models (LRMs) achieve superior performance by extending the thought length. However, a lengthy thinking trajectory leads to reduced efficiency. Most of the existing methods are stuck in the assumption of overthinking and attempt to reason efficiently by compressing the Chain-of-Thought, but this often leads to performance degradation. To address this problem, we introduce A*-Thought, an efficient tree search-based unified framework designed to identify and isolate the most essential thoughts from the extensive reasoning chains produced by these models. It formulates the reasoning process of LRMs as a search tree, where each node represents a reasoning span in the giant reasoning space. By combining the A* search algorithm with a cost function specific to the reasoning path, it can efficiently compress the chain of thought and determine a reasoning path with high information density and low cost. In addition, we also propose a bidirectional importance estimation mechanism, which further refines this search process and enhances its efficiency beyond uniform sampling. Extensive experiments on several advanced math tasks show that A*-Thought effectively balances performance and efficiency over a huge search space. Specifically, A*-Thought can improve the performance of QwQ-32B by 2.39$\times$ with low-budget and reduce the length of the output token by nearly 50% with high-budget. The proposed method is also compatible with several other LRMs, demonstrating its generalization capability. The code can be accessed at: https://github.com/AI9Stars/AStar-Thought.
Cross-Task Experiential Learning on LLM-based Multi-Agent Collaboration
May 29, 2025Large Language Model-based multi-agent systems (MAS) have shown remarkable progress in solving complex tasks through collaborative reasoning and inter-agent critique. However, existing approaches typically treat each task in isolation, resulting in redundant computations and limited generalization across structurally similar tasks. To address this, we introduce multi-agent cross-task experiential learning (MAEL), a novel framework that endows LLM-driven agents with explicit cross-task learning and experience accumulation. We model the task-solving workflow on a graph-structured multi-agent collaboration network, where agents propagate information and coordinate via explicit connectivity. During the experiential learning phase, we quantify the quality for each step in the task-solving workflow and store the resulting rewards along with the corresponding inputs and outputs into each agent's individual experience pool. During inference, agents retrieve high-reward, task-relevant experiences as few-shot examples to enhance the effectiveness of each reasoning step, thereby enabling more accurate and efficient multi-agent collaboration. Experimental results on diverse datasets demonstrate that MAEL empowers agents to learn from prior task experiences effectively-achieving faster convergence and producing higher-quality solutions on current tasks.