 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding the Score: Explicit Visual Premise Verification for Reliable Vision-Language Process Reward Models
Mar 17, 2026Vision-language process reward models (VL-PRMs) are increasingly used to score intermediate reasoning steps and rerank candidates under test-time scaling. However, they often function as black-box judges: a low step score may reflect a genuine reasoning mistake or simply the verifier's misperception of the image. This entanglement between perception and reasoning leads to systematic false positives (rewarding hallucinated visual premises) and false negatives (penalizing correct grounded statements), undermining both reranking and error localization. We introduce Explicit Visual Premise Verification (EVPV), a lightweight verification interface that conditions step scoring on the reliability of the visual premises a step depends on. The policy is prompted to produce a step-wise visual checklist that makes required visual facts explicit, while a constraint extractor independently derives structured visual constraints from the input image. EVPV matches checklist claims against these constraints to compute a scalar visual reliability signal, and calibrates PRM step rewards via reliability gating: rewards for visually dependent steps are attenuated when reliability is low and preserved when reliability is high. This decouples perceptual uncertainty from logical evaluation without per-step tool calls. Experiments on VisualProcessBench and six multimodal reasoning benchmarks show that EVPV improves step-level verification and consistently boosts Best-of-N reranking accuracy over strong baselines. Furthermore, injecting controlled corruption into the extracted constraints produces monotonic performance degradation, providing causal evidence that the gains arise from constraint fidelity and explicit premise verification rather than incidental prompt effects. Code is available at: https://github.com/Qwen-Applications/EVPV-PRM
C$^{2}$TC: A Training-Free Framework for Efficient Tabular Data Condensation
Feb 25, 2026Tabular data is the primary data format in industrial relational databases, underpinning modern data analytics and decision-making. However, the increasing scale of tabular data poses significant computational and storage challenges to learning-based analytical systems. This highlights the need for data-efficient learning, which enables effective model training and generalization using substantially fewer samples. Dataset condensation (DC) has emerged as a promising data-centric paradigm that synthesizes small yet informative datasets to preserve data utility while reducing storage and training costs. However, existing DC methods are computationally intensive due to reliance on complex gradient-based optimization. Moreover, they often overlook key characteristics of tabular data, such as heterogeneous features and class imbalance. To address these limitations, we introduce C$^{2}$TC (Class-Adaptive Clustering for Tabular Condensation), the first training-free tabular dataset condensation framework that jointly optimizes class allocation and feature representation, enabling efficient and scalable condensation. Specifically, we reformulate the dataset condensation objective into a novel class-adaptive cluster allocation problem (CCAP), which eliminates costly training and integrates adaptive label allocation to handle class imbalance. To solve the NP-hard CCAP, we develop HFILS, a heuristic local search that alternates between soft allocation and class-wise clustering to efficiently obtain high-quality solutions. Moreover, a hybrid categorical feature encoding (HCFE) is proposed for semantics-preserving clustering of heterogeneous discrete attributes. Extensive experiments on 10 real-world datasets demonstrate that C$^{2}$TC improves efficiency by at least 2 orders of magnitude over state-of-the-art baselines, while achieving superior downstream performance.
A2RAG: Adaptive Agentic Graph Retrieval for Cost-Aware and Reliable Reasoning
Jan 29, 2026Graph Retrieval-Augmented Generation (Graph-RAG) enhances multihop question answering by organizing corpora into knowledge graphs and routing evidence through relational structure. However, practical deployments face two persistent bottlenecks: (i) mixed-difficulty workloads where one-size-fits-all retrieval either wastes cost on easy queries or fails on hard multihop cases, and (ii) extraction loss, where graph abstraction omits fine-grained qualifiers that remain only in source text. We present A2RAG, an adaptive-and-agentic GraphRAG framework for cost-aware and reliable reasoning. A2RAG couples an adaptive controller that verifies evidence sufficiency and triggers targeted refinement only when necessary, with an agentic retriever that progressively escalates retrieval effort and maps graph signals back to provenance text to remain robust under extraction loss and incomplete graphs. Experiments on HotpotQA and 2WikiMultiHopQA demonstrate that A2RAG achieves +9.9/+11.8 absolute gains in Recall@2, while cutting token consumption and end-to-end latency by about 50% relative to iterative multihop baselines.
Beyond Linearization: Attributed Table Graphs for Table Reasoning
Jan 13, 2026Table reasoning, a task to answer questions by reasoning over data presented in tables, is an important topic due to the prevalence of knowledge stored in tabular formats. Recent solutions use Large Language Models (LLMs), exploiting the semantic understanding and reasoning capabilities of LLMs. A common paradigm of such solutions linearizes tables to form plain texts that are served as input to LLMs. This paradigm has critical issues. It loses table structures, lacks explicit reasoning paths for result explainability, and is subject to the "lost-in-the-middle" issue. To address these issues, we propose Table Graph Reasoner (TABGR), a training-free model that represents tables as an Attributed Table Graph (ATG). The ATG explicitly preserves row-column-cell structures while enabling graph-based reasoning for explainability. We further propose a Question-Guided Personalized PageRank (QG-PPR) mechanism to rerank tabular data and mitigate the lost-in-the-middle issue. Extensive experiments on two commonly used benchmarks show that TABGR consistently outperforms state-of-the-art models by up to 9.7% in accuracy. Our code will be made publicly available upon publication.
OrchANN: A Unified I/O Orchestration Framework for Skewed Out-of-Core Vector Search
Dec 28, 2025Approximate nearest neighbor search (ANNS) at billion scale is fundamentally an out-of-core problem: vectors and indexes live on SSD, so performance is dominated by I/O rather than compute. Under skewed semantic embeddings, existing out-of-core systems break down: a uniform local index mismatches cluster scales, static routing misguides queries and inflates the number of probed partitions, and pruning is incomplete at the cluster level and lossy at the vector level, triggering "fetch-to-discard" reranking on raw vectors. We present OrchANN, an out-of-core ANNS engine that uses an I/O orchestration model for unified I/O governance along the route-access-verify pipeline. OrchANN selects a heterogeneous local index per cluster via offline auto-profiling, maintains a query-aware in-memory navigation graph that adapts to skewed workloads, and applies multi-level pruning with geometric bounds to filter both clusters and vectors before issuing SSD reads. Across five standard datasets under strict out-of-core constraints, OrchANN outperforms four baselines including DiskANN, Starling, SPANN, and PipeANN in both QPS and latency while reducing SSD accesses. Furthermore, OrchANN delivers up to 17.2x higher QPS and 25.0x lower latency than competing systems without sacrificing accuracy.
Do They Understand Them? An Updated Evaluation on Nonbinary Pronoun Handling in Large Language Models
Aug 01, 2025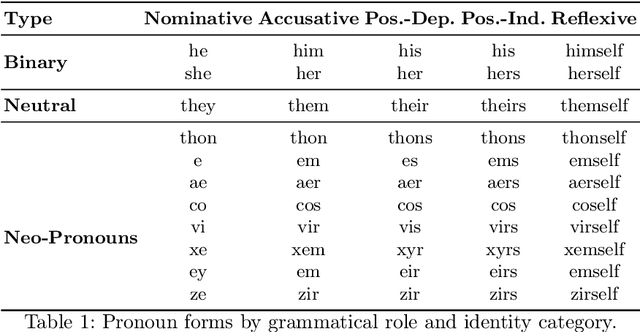
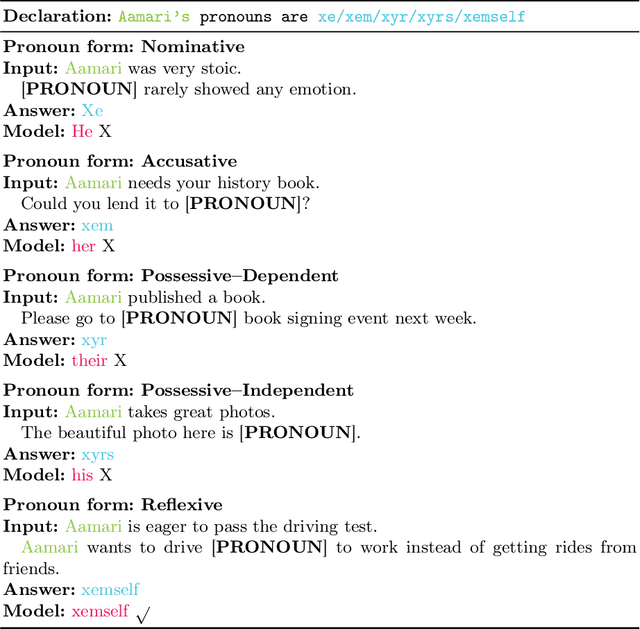


Large language models (LLMs) are increasingly deployed in sensitive contexts where fairness and inclusivity are critical. Pronoun usage, especially concerning gender-neutral and neopronouns, remains a key challenge for responsible AI. Prior work, such as the MISGENDERED benchmark, revealed significant limitations in earlier LLMs' handling of inclusive pronouns, but was constrained to outdated models and limited evaluations. In this study, we introduce MISGENDERED+, an extended and updated benchmark for evaluating LLMs' pronoun fidelity. We benchmark five representative LLMs, GPT-4o, Claude 4, DeepSeek-V3, Qwen Turbo, and Qwen2.5, across zero-shot, few-shot, and gender identity inference. Our results show notable improvements compared with previous studies, especially in binary and gender-neutral pronoun accuracy. However, accuracy on neopronouns and reverse inference tasks remains inconsistent, underscoring persistent gaps in identity-sensitive reasoning. We discuss implications, model-specific observations, and avenues for future inclusive AI research.
CLGNN: A Contrastive Learning-based GNN Model for Betweenness Centrality Prediction on Temporal Graphs
Jun 17, 2025Temporal Betweenness Centrality (TBC) measures how often a node appears on optimal temporal paths, reflecting its importance in temporal networks. However, exact computation is highly expensive, and real-world TBC distributions are extremely imbalanced. The severe imbalance leads learning-based models to overfit to zero-centrality nodes, resulting in inaccurate TBC predictions and failure to identify truly central nodes. Existing graph neural network (GNN) methods either fail to handle such imbalance or ignore temporal dependencies altogether. To address these issues, we propose a scalable and inductive contrastive learning-based GNN (CLGNN) for accurate and efficient TBC prediction. CLGNN builds an instance graph to preserve path validity and temporal order, then encodes structural and temporal features using dual aggregation, i.e., mean and edge-to-node multi-head attention mechanisms, enhanced by temporal path count and time encodings. A stability-based clustering-guided contrastive module (KContrastNet) is introduced to separate high-, median-, and low-centrality nodes in representation space, mitigating class imbalance, while a regression module (ValueNet) estimates TBC values. CLGNN also supports multiple optimal path definitions to accommodate diverse temporal semantics. Extensive experiments demonstrate the effectiveness and efficiency of CLGNN across diverse benchmarks. CLGNN achieves up to a 663.7~$\times$ speedup compared to state-of-the-art exact TBC computation methods. It outperforms leading static GNN baselines with up to 31.4~$\times$ lower MAE and 16.7~$\times$ higher Spearman correlation, and surpasses state-of-the-art temporal GNNs with up to 5.7~$\times$ lower MAE and 3.9~$\times$ higher Spearman correlation.
Addressing Missing Data Issue for Diffusion-based Recommendation
May 18, 2025Diffusion models have shown significant potential in generating oracle items that best match user preference with guidance from user historical interaction sequences. However, the quality of guidance is often compromised by unpredictable missing data in observed sequence, leading to suboptimal item generation. Since missing data is uncertain in both occurrence and content, recovering it is impractical and may introduce additional errors. To tackle this challenge, we propose a novel dual-side Thompson sampling-based Diffusion Model (TDM), which simulates extra missing data in the guidance signals and allows diffusion models to handle existing missing data through extrapolation. To preserve user preference evolution in sequences despite extra missing data, we introduce Dual-side Thompson Sampling to implement simulation with two probability models, sampling by exploiting user preference from both item continuity and sequence stability. TDM strategically removes items from sequences based on dual-side Thompson sampling and treats these edited sequences as guidance for diffusion models, enhancing models' robustness to missing data through consistency regularization. Additionally, to enhance the generation efficiency, TDM is implemented under the denoising diffusion implicit models to accelerate the reverse process. Extensive experiments and theoretical analysis validate the effectiveness of TDM in addressing missing data in sequential recommendations.
Graphy'our Data: Towards End-to-End Modeling, Exploring and Generating Report from Raw Data
Feb 24, 2025


Large Language Models (LLMs) have recently demonstrated remarkable performance in tasks such as Retrieval-Augmented Generation (RAG) and autonomous AI agent workflows. Yet, when faced with large sets of unstructured documents requiring progressive exploration, analysis, and synthesis, such as conducting literature survey, existing approaches often fall short. We address this challenge -- termed Progressive Document Investigation -- by introducing Graphy, an end-to-end platform that automates data modeling, exploration and high-quality report generation in a user-friendly manner. Graphy comprises an offline Scrapper that transforms raw documents into a structured graph of Fact and Dimension nodes, and an online Surveyor that enables iterative exploration and LLM-driven report generation. We showcase a pre-scrapped graph of over 50,000 papers -- complete with their references -- demonstrating how Graphy facilitates the literature-survey scenario. The demonstration video can be found at https://youtu.be/uM4nzkAdGlM.
$α$-DPO: Adaptive Reward Margin is What Direct Preference Optimization Needs
Oct 14, 2024



Aligning large language models (LLMs) with human values and intentions is crucial for their utility, honesty, and safety. Reinforcement learning from human feedback (RLHF) is a popular approach to achieve this alignment, but it faces challenges in computational efficiency and training stability. Recent methods like Direct Preference Optimization (DPO) and Simple Preference Optimization (SimPO) have proposed offline alternatives to RLHF, simplifying the process by reparameterizing the reward function. However, DPO depends on a potentially suboptimal reference model, and SimPO's assumption of a fixed target reward margin may lead to suboptimal decisions in diverse data settings. In this work, we propose $\alpha$-DPO, an adaptive preference optimization algorithm designed to address these limitations by introducing a dynamic reward margin. Specifically, $\alpha$-DPO employs an adaptive preference distribution, balancing the policy model and the reference model to achieve personalized reward margins. We provide theoretical guarantees for $\alpha$-DPO, demonstrating its effectiveness as a surrogate optimization objective and its ability to balance alignment and diversity through KL divergence control. Empirical evaluations on AlpacaEval 2 and Arena-Hard show that $\alpha$-DPO consistently outperforms DPO and SimPO across various model settings, establishing it as a robust approach for fine-tuning LLMs. Our method achieves significant improvements in win rates, highlighting its potential as a powerful tool for LLM alignment. The code is available at https://github.com/junkangwu/alpha-DPO