 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSteer: Text-Guided Flow Matching in Activation Space for Versatile LLM Steering
May 28, 2026Activation-based control steers large language models (LLMs) by intervening on their internal representations during inference, and has emerged as an effective paradigm for controlling behaviors such as persona and style. However, existing methods often rely on fixed steering directions or task-specific intervention modules, making them difficult to adapt to fine-grained concepts and compositional constraints. We propose UniSteer, a text-guided activation flow matching model that learns a conditional distribution over residual-stream activations from natural-language conditions. Instead of fitting a separate intervention for each target behavior, UniSteer learns a universal conditional velocity field in activation space. At inference time, UniSteer performs flow inversion by partially transporting a source activation toward a latent state and regenerating it under a target textual condition before injecting it back into the frozen LLM. The same conditional model supports activation-space classification by selecting the textual label with the lowest reconstruction energy. Experiments on three target LLMs show that UniSteer provides a unified interface across behavioral control, truthfulness steering, fine-grained concept steering, multi-constraint instruction following, and activation-space classification.
CompactRAG: Reducing LLM Calls and Token Overhead in Multi-Hop Question Answering
Feb 05, 2026Retrieval-augmented generation (RAG) has become a key paradigm for knowledge-intensive question answering. However, existing multi-hop RAG systems remain inefficient, as they alternate between retrieval and reasoning at each step, resulting in repeated LLM calls, high token consumption, and unstable entity grounding across hops. We propose CompactRAG, a simple yet effective framework that decouples offline corpus restructuring from online reasoning. In the offline stage, an LLM reads the corpus once and converts it into an atomic QA knowledge base, which represents knowledge as minimal, fine-grained question-answer pairs. In the online stage, complex queries are decomposed and carefully rewritten to preserve entity consistency, and are resolved through dense retrieval followed by RoBERTa-based answer extraction. Notably, during inference, the LLM is invoked only twice in total - once for sub-question decomposition and once for final answer synthesis - regardless of the number of reasoning hops. Experiments on HotpotQA, 2WikiMultiHopQA, and MuSiQue demonstrate that CompactRAG achieves competitive accuracy while substantially reducing token consumption compared to iterative RAG baselines, highlighting a cost-efficient and practical approach to multi-hop reasoning over large knowledge corpora. The implementation is available at GitHub.
No Free Lunch from Audio Pretraining in Bioacoustics: A Benchmark Study of Embeddings
Aug 13, 2025Bioacoustics, the study of animal sounds, offers a non-invasive method to monitor ecosystems. Extracting embeddings from audio-pretrained deep learning (DL) models without fine-tuning has become popular for obtaining bioacoustic features for tasks. However, a recent benchmark study reveals that while fine-tuned audio-pretrained VGG and transformer models achieve state-of-the-art performance in some tasks, they fail in others. This study benchmarks 11 DL models on the same tasks by reducing their learned embeddings' dimensionality and evaluating them through clustering. We found that audio-pretrained DL models 1) without fine-tuning even underperform fine-tuned AlexNet, 2) both with and without fine-tuning fail to separate the background from labeled sounds, but ResNet does, and 3) outperform other models when fewer background sounds are included during fine-tuning. This study underscores the necessity of fine-tuning audio-pretrained models and checking the embeddings after fine-tuning. Our codes are available: https://github.com/NeuroscienceAI/Audio\_Embeddings
Why Stop at One Error? Benchmarking LLMs as Data Science Code Debuggers for Multi-Hop and Multi-Bug Errors
Mar 28, 2025LLMs are transforming software development, yet current code generation and code repair benchmarks mainly assess syntactic and functional correctness in simple, single-error cases. LLMs' capabilities to autonomously find and fix runtime logical errors in complex data science code remain largely unexplored. To address this gap, we introduce DSDBench: the Data Science Debugging Benchmark, the first benchmark for systematic evaluation of LLMs on multi-hop error tracing and multi-bug detection in data science code debugging. DSDBench adapts datasets from existing data science task benchmarks, such as DABench and MatPlotBench, featuring realistic data science debugging tasks with automatically synthesized multi-hop, multi-bug code snippets. DSDBench includes 1,117 annotated samples with 741 cause-effect error pairs and runtime error messages. Evaluations of state-of-the-art LLMs on DSDBench show significant performance gaps, highlighting challenges in debugging logical runtime errors in data science code. DSDBench offers a crucial resource to evaluate and improve LLMs' debugging and reasoning capabilities, enabling more reliable AI-assisted data science in the future.DSDBench is publicly available at https://github.com/KevinCL16/DSDBench.
An Overall Real-Time Mechanism for Classification and Quality Evaluation of Rice
Feb 19, 2025



Rice is one of the most widely cultivated crops globally and has been developed into numerous varieties. The quality of rice during cultivation is primarily determined by its cultivar and characteristics. Traditionally, rice classification and quality assessment rely on manual visual inspection, a process that is both time-consuming and prone to errors. However, with advancements in machine vision technology, automating rice classification and quality evaluation based on its cultivar and characteristics has become increasingly feasible, enhancing both accuracy and efficiency. This study proposes a real-time evaluation mechanism for comprehensive rice grain assessment, integrating a one-stage object detection approach, a deep convolutional neural network, and traditional machine learning techniques. The proposed framework enables rice variety identification, grain completeness grading, and grain chalkiness evaluation. The rice grain dataset used in this study comprises approximately 20,000 images from six widely cultivated rice varieties in China. Experimental results demonstrate that the proposed mechanism achieves a mean average precision (mAP) of 99.14% in the object detection task and an accuracy of 97.89% in the classification task. Furthermore, the framework attains an average accuracy of 97.56% in grain completeness grading within the same rice variety, contributing to an effective quality evaluation system.
CamoTeacher: Dual-Rotation Consistency Learning for Semi-Supervised Camouflaged Object Detection
Aug 15, 2024



Existing camouflaged object detection~(COD) methods depend heavily on large-scale pixel-level annotations.However, acquiring such annotations is laborious due to the inherent camouflage characteristics of the objects.Semi-supervised learning offers a promising solution to this challenge.Yet, its application in COD is hindered by significant pseudo-label noise, both pixel-level and instance-level.We introduce CamoTeacher, a novel semi-supervised COD framework, utilizing Dual-Rotation Consistency Learning~(DRCL) to effectively address these noise issues.Specifically, DRCL minimizes pseudo-label noise by leveraging rotation views' consistency in pixel-level and instance-level.First, it employs Pixel-wise Consistency Learning~(PCL) to deal with pixel-level noise by reweighting the different parts within the pseudo-label.Second, Instance-wise Consistency Learning~(ICL) is used to adjust weights for pseudo-labels, which handles instance-level noise.Extensive experiments on four COD benchmark datasets demonstrate that the proposed CamoTeacher not only achieves state-of-the-art compared with semi-supervised learning methods, but also rivals established fully-supervised learning methods.Our code will be available soon.
MatPlotAgent: Method and Evaluation for LLM-Based Agentic Scientific Data Visualization
Feb 18, 2024



Scientific data visualization plays a crucial role in research by enabling the direct display of complex information and assisting researchers in identifying implicit patterns. Despite its importance, the use of Large Language Models (LLMs) for scientific data visualization remains rather unexplored. In this study, we introduce MatPlotAgent, an efficient model-agnostic LLM agent framework designed to automate scientific data visualization tasks. Leveraging the capabilities of both code LLMs and multi-modal LLMs, MatPlotAgent consists of three core modules: query understanding, code generation with iterative debugging, and a visual feedback mechanism for error correction. To address the lack of benchmarks in this field, we present MatPlotBench, a high-quality benchmark consisting of 100 human-verified test cases. Additionally, we introduce a scoring approach that utilizes GPT-4V for automatic evaluation. Experimental results demonstrate that MatPlotAgent can improve the performance of various LLMs, including both commercial and open-source models. Furthermore, the proposed evaluation method shows a strong correlation with human-annotated scores.
UltraLink: An Open-Source Knowledge-Enhanced Multilingual Supervised Fine-tuning Dataset
Feb 18, 2024



Open-source large language models (LLMs) have gained significant strength across diverse fields. Nevertheless, the majority of studies primarily concentrate on English, with only limited exploration into the realm of multilingual abilities. In this work, we therefore construct an open-source multilingual supervised fine-tuning dataset. Different from previous works that simply translate English instructions, we consider both the language-specific and language-agnostic abilities of LLMs. Firstly, we introduce a knowledge-grounded data augmentation approach to elicit more language-specific knowledge of LLMs, improving their ability to serve users from different countries. Moreover, we find modern LLMs possess strong cross-lingual transfer capabilities, thus repeatedly learning identical content in various languages is not necessary. Consequently, we can substantially prune the language-agnostic supervised fine-tuning (SFT) data without any performance degradation, making multilingual SFT more efficient. The resulting UltraLink dataset comprises approximately 1 million samples across five languages (i.e., En, Zh, Ru, Fr, Es), and the proposed data construction method can be easily extended to other languages. UltraLink-LM, which is trained on UltraLink, outperforms several representative baselines across many tasks.
Channel Estimation and Projection for RIS-assisted MIMO Using Zadoff-Chu Sequences
Feb 21, 2022

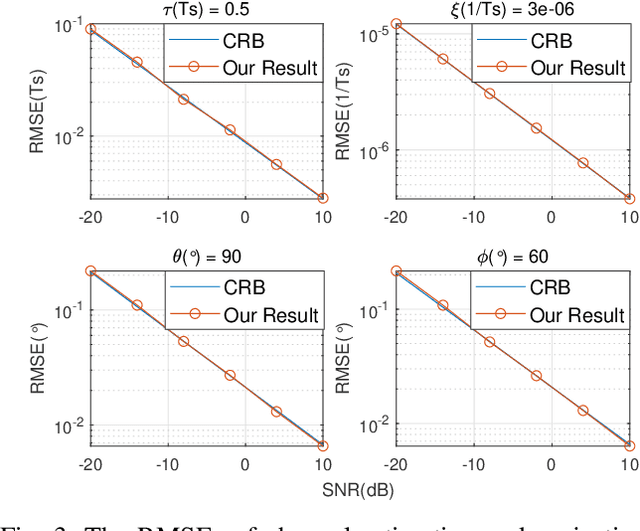
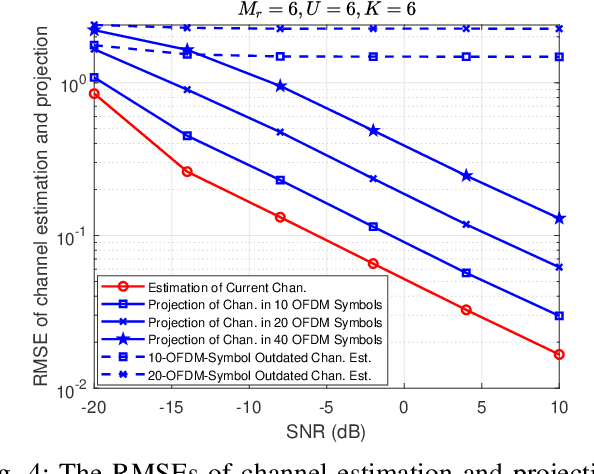
The reconfigurable intelligent surface (RIS) technology is a promising enabler for millimeter wave (mmWave) wireless communications, as it can potentially provide spectral efficiency comparable to the conventional massive multiple-input multiple-output (MIMO) but with significantly lower hardware complexity. In this paper, we focus on the estimation and projection of the uplink RIS-aided massive MIMO channel, which can be time-varying. We propose to let the user equipments (UE) transmit Zadoff-Chu (ZC) sequences and let the base station (BS) conduct maximum likelihood (ML) estimation of the uplink channel. The proposed scheme is computationally efficient: it uses ZC sequences to decouple the estimation of the frequency and time offsets; it uses the space-alternating generalized expectation-maximization (SAGE) method to reduce the high-dimensional problem due to the multipaths to multiple lower-dimensional ones per path. Owing to the estimation of the Doppler frequency offsets, the time-varying channel state can be projected, which can significantly lower the overhead of the pilots for channel estimation. The numerical simulations verify the effectiveness of the proposed scheme.