 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Preference Optimization via Token-Level Reward Function Estimation
Aug 24, 2024



Recent advancements in large language model alignment leverage token-level supervisions to perform fine-grained preference optimization. However, existing token-level alignment methods either optimize on all available tokens, which can be noisy and inefficient, or perform selective training with complex and expensive key token selection strategies. In this work, we propose Selective Preference Optimization (SePO), a novel selective alignment strategy that centers on efficient key token selection. SePO proposes the first token selection method based on Direct Preference Optimization (DPO), which trains an oracle model to estimate a token-level reward function on the target data. This method applies to any existing alignment datasets with response-level annotations and enables cost-efficient token selection with small-scale oracle models and training data. The estimated reward function is then utilized to score all tokens within the target dataset, where only the key tokens are selected to supervise the target policy model with a reference model-free contrastive objective function. Extensive experiments on three public evaluation benchmarks show that SePO significantly outperforms competitive baseline methods by only optimizing 30% key tokens on the target dataset. SePO applications on weak-to-strong generalization show that weak oracle models effectively supervise strong policy models with up to 16.8x more parameters. SePO also effectively selects key tokens from out-of-distribution data to enhance strong policy models and alleviate the over-optimization problem.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024



Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
Diversity Empowers Intelligence: Integrating Expertise of Software Engineering Agents
Aug 13, 2024Large language model (LLM) agents have shown great potential in solving real-world software engineering (SWE) problems. The most advanced open-source SWE agent can resolve over 27% of real GitHub issues in SWE-Bench Lite. However, these sophisticated agent frameworks exhibit varying strengths, excelling in certain tasks while underperforming in others. To fully harness the diversity of these agents, we propose DEI (Diversity Empowered Intelligence), a framework that leverages their unique expertise. DEI functions as a meta-module atop existing SWE agent frameworks, managing agent collectives for enhanced problem-solving. Experimental results show that a DEI-guided committee of agents is able to surpass the best individual agent's performance by a large margin. For instance, a group of open-source SWE agents, with a maximum individual resolve rate of 27.3% on SWE-Bench Lite, can achieve a 34.3% resolve rate with DEI, making a 25% improvement and beating most closed-source solutions. Our best-performing group excels with a 55% resolve rate, securing the highest ranking on SWE-Bench Lite. Our findings contribute to the growing body of research on collaborative AI systems and their potential to solve complex software engineering challenges.
Personalized Multi-task Training for Recommender System
Jul 31, 2024



In the vast landscape of internet information, recommender systems (RecSys) have become essential for guiding users through a sea of choices aligned with their preferences. These systems have applications in diverse domains, such as news feeds, game suggestions, and shopping recommendations. Personalization is a key technique in RecSys, where modern methods leverage representation learning to encode user/item interactions into embeddings, forming the foundation for personalized recommendations. However, integrating information from multiple sources to enhance recommendation performance remains challenging. This paper introduces a novel approach named PMTRec, the first personalized multi-task learning algorithm to obtain comprehensive user/item embeddings from various information sources. Addressing challenges specific to personalized RecSys, we develop modules to handle personalized task weights, diverse task orientations, and variations in gradient magnitudes across tasks. PMTRec dynamically adjusts task weights based on gradient norms for each user/item, employs a Task Focusing module to align gradient combinations with the main recommendation task, and uses a Gradient Magnitude Balancing module to ensure balanced training across tasks. Through extensive experiments on three real-world datasets with different scales, we demonstrate that PMTRec significantly outperforms existing multi-task learning methods, showcasing its effectiveness in achieving enhanced recommendation accuracy by leveraging multiple tasks simultaneously. Our contributions open new avenues for advancing personalized multi-task training in recommender systems.
Auto DragGAN: Editing the Generative Image Manifold in an Autoregressive Manner
Jul 26, 2024



Pixel-level fine-grained image editing remains an open challenge. Previous works fail to achieve an ideal trade-off between control granularity and inference speed. They either fail to achieve pixel-level fine-grained control, or their inference speed requires optimization. To address this, this paper for the first time employs a regression-based network to learn the variation patterns of StyleGAN latent codes during the image dragging process. This method enables pixel-level precision in dragging editing with little time cost. Users can specify handle points and their corresponding target points on any GAN-generated images, and our method will move each handle point to its corresponding target point. Through experimental analysis, we discover that a short movement distance from handle points to target points yields a high-fidelity edited image, as the model only needs to predict the movement of a small portion of pixels. To achieve this, we decompose the entire movement process into multiple sub-processes. Specifically, we develop a transformer encoder-decoder based network named 'Latent Predictor' to predict the latent code motion trajectories from handle points to target points in an autoregressive manner. Moreover, to enhance the prediction stability, we introduce a component named 'Latent Regularizer', aimed at constraining the latent code motion within the distribution of natural images. Extensive experiments demonstrate that our method achieves state-of-the-art (SOTA) inference speed and image editing performance at the pixel-level granularity.
APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets
Jun 26, 2024



The advancement of function-calling agent models requires diverse, reliable, and high-quality datasets. This paper presents APIGen, an automated data generation pipeline designed to synthesize verifiable high-quality datasets for function-calling applications. We leverage APIGen and collect 3,673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, ensuring its reliability and correctness. We demonstrate that models trained with our curated datasets, even with only 7B parameters, can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models. Moreover, our 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku. We release a dataset containing 60,000 high-quality entries, aiming to advance the field of function-calling agent domains. The dataset is available on Huggingface: https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k and the project homepage: https://apigen-pipeline.github.io/
RAEmoLLM: Retrieval Augmented LLMs for Cross-Domain Misinformation Detection Using In-Context Learning based on Emotional Information
Jun 16, 2024Misinformation is prevalent in various fields such as education, politics, health, etc., causing significant harm to society. However, current methods for cross-domain misinformation detection rely on time and resources consuming fine-tuning and complex model structures. With the outstanding performance of LLMs, many studies have employed them for misinformation detection. Unfortunately, they focus on in-domain tasks and do not incorporate significant sentiment and emotion features (which we jointly call affect). In this paper, we propose RAEmoLLM, the first retrieval augmented (RAG) LLMs framework to address cross-domain misinformation detection using in-context learning based on affective information. It accomplishes this by applying an emotion-aware LLM to construct a retrieval database of affective embeddings. This database is used by our retrieval module to obtain source-domain samples, which are subsequently used for the inference module's in-context few-shot learning to detect target domain misinformation. We evaluate our framework on three misinformation benchmarks. Results show that RAEmoLLM achieves significant improvements compared to the zero-shot method on three datasets, with the highest increases of 20.69%, 23.94%, and 39.11% respectively. This work will be released on https://github.com/lzw108/RAEmoLLM.
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Jun 12, 2024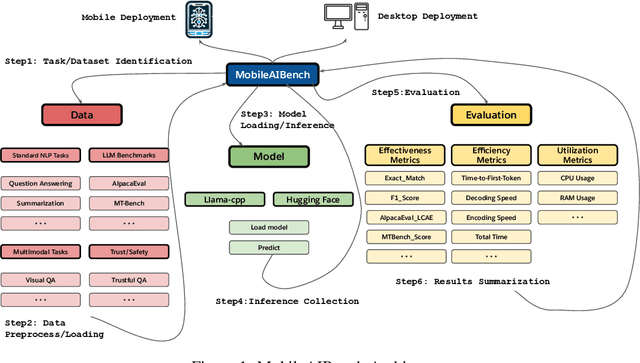



The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
Oxygen vacancies modulated VO2 for neurons and Spiking Neural Network construction
Apr 16, 2024



Artificial neuronal devices are the basic building blocks for neuromorphic computing systems, which have been motivated by realistic brain emulation. Aiming for these applications, various device concepts have been proposed to mimic the neuronal dynamics and functions. While till now, the artificial neuron devices with high efficiency, high stability and low power consumption are still far from practical application. Due to the special insulator-metal phase transition, Vanadium Dioxide (VO2) has been considered as an idea candidate for neuronal device fabrication. However, its intrinsic insulating state requires the VO2 neuronal device to be driven under large bias voltage, resulting in high power consumption and low frequency. Thus in the current study, we have addressed this challenge by preparing oxygen vacancies modulated VO2 film(VO2-x) and fabricating the VO2-x neuronal devices for Spiking Neural Networks (SNNs) construction. Results indicate the neuron devices can be operated under lower voltage with improved processing speed. The proposed VO2-x based back-propagation SNNs (BP-SNNs) system, trained with the MNIST dataset, demonstrates excellent accuracy in image recognition. Our study not only demonstrates the VO2-x based neurons and SNN system for practical application, but also offers an effective way to optimize the future neuromorphic computing systems by defect engineering strategy.
Instruction-based Hypergraph Pretraining
Mar 28, 2024Pretraining has been widely explored to augment the adaptability of graph learning models to transfer knowledge from large datasets to a downstream task, such as link prediction or classification. However, the gap between training objectives and the discrepancy between data distributions in pretraining and downstream tasks hinders the transfer of the pretrained knowledge. Inspired by instruction-based prompts widely used in pretrained language models, we introduce instructions into graph pretraining. In this paper, we propose a novel pretraining framework named Instruction-based Hypergraph Pretraining. To overcome the discrepancy between pretraining and downstream tasks, text-based instructions are applied to provide explicit guidance on specific tasks for representation learning. Compared to learnable prompts, whose effectiveness depends on the quality and the diversity of training data, text-based instructions intrinsically encapsulate task information and support the model to generalize beyond the structure seen during pretraining. To capture high-order relations with task information in a context-aware manner, a novel prompting hypergraph convolution layer is devised to integrate instructions into information propagation in hypergraphs. Extensive experiments conducted on three public datasets verify the superiority of IHP in various scenarios.