 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Vector Prompt Interfaces Should Be Exposed to Enable Customization of Large Language Models
Mar 04, 2026As large language models (LLMs) transition from research prototypes to real-world systems, customization has emerged as a central bottleneck. While text prompts can already customize LLM behavior, we argue that text-only prompting does not constitute a suitable control interface for scalable, stable, and inference-only customization. This position paper argues that model providers should expose \emph{vector prompt inputs} as part of the public interface for customizing LLMs. We support this position with diagnostic evidence showing that vector prompt tuning continues to improve with increasing supervision whereas text-based prompt optimization saturates early, and that vector prompts exhibit dense, global attention patterns indicative of a distinct control mechanism. We further discuss why inference-only customization is increasingly important under realistic deployment constraints, and why exposing vector prompts need not fundamentally increase model leakage risk under a standard black-box threat model. We conclude with a call to action for the community to rethink prompt interfaces as a core component of LLM customization.
AudioCapBench: Quick Evaluation on Audio Captioning across Sound, Music, and Speech
Feb 27, 2026We introduce AudioCapBench, a benchmark for evaluating audio captioning capabilities of large multimodal models. \method covers three distinct audio domains, including environmental sound, music, and speech, with 1,000 curated evaluation samples drawn from established datasets. We evaluate 13 models across two providers (OpenAI, Google Gemini) using both reference-based metrics (METEOR, BLEU, ROUGE-L) and an LLM-as-Judge framework that scores predictions on three orthogonal dimensions: \textit{accuracy} (semantic correctness), \textit{completeness} (coverage of reference content), and \textit{hallucination} (absence of fabricated content). Our results reveal that Gemini models generally outperform OpenAI models on overall captioning quality, with Gemini~3~Pro achieving the highest overall score (6.00/10), while OpenAI models exhibit lower hallucination rates. All models perform best on speech captioning and worst on music captioning. We release the benchmark as well as evaluation code to facilitate reproducible audio understanding research.
LoCoBench-Agent: An Interactive Benchmark for LLM Agents in Long-Context Software Engineering
Nov 17, 2025



As large language models (LLMs) evolve into sophisticated autonomous agents capable of complex software development tasks, evaluating their real-world capabilities becomes critical. While existing benchmarks like LoCoBench~\cite{qiu2025locobench} assess long-context code understanding, they focus on single-turn evaluation and cannot capture the multi-turn interactive nature, tool usage patterns, and adaptive reasoning required by real-world coding agents. We introduce \textbf{LoCoBench-Agent}, a comprehensive evaluation framework specifically designed to assess LLM agents in realistic, long-context software engineering workflows. Our framework extends LoCoBench's 8,000 scenarios into interactive agent environments, enabling systematic evaluation of multi-turn conversations, tool usage efficiency, error recovery, and architectural consistency across extended development sessions. We also introduce an evaluation methodology with 9 metrics across comprehension and efficiency dimensions. Our framework provides agents with 8 specialized tools (file operations, search, code analysis) and evaluates them across context lengths ranging from 10K to 1M tokens, enabling precise assessment of long-context performance. Through systematic evaluation of state-of-the-art models, we reveal several key findings: (1) agents exhibit remarkable long-context robustness; (2) comprehension-efficiency trade-off exists with negative correlation, where thorough exploration increases comprehension but reduces efficiency; and (3) conversation efficiency varies dramatically across models, with strategic tool usage patterns differentiating high-performing agents. As the first long-context LLM agent benchmark for software engineering, LoCoBench-Agent establishes a rigorous foundation for measuring agent capabilities, identifying performance gaps, and advancing autonomous software development at scale.
GeoGNN: Quantifying and Mitigating Semantic Drift in Text-Attributed Graphs
Nov 12, 2025Graph neural networks (GNNs) on text--attributed graphs (TAGs) typically encode node texts using pretrained language models (PLMs) and propagate these embeddings through linear neighborhood aggregation. However, the representation spaces of modern PLMs are highly non--linear and geometrically structured, where textual embeddings reside on curved semantic manifolds rather than flat Euclidean spaces. Linear aggregation on such manifolds inevitably distorts geometry and causes semantic drift--a phenomenon where aggregated representations deviate from the intrinsic manifold, losing semantic fidelity and expressive power. To quantitatively investigate this problem, this work introduces a local PCA--based metric that measures the degree of semantic drift and provides the first quantitative framework to analyze how different aggregation mechanisms affect manifold structure. Building upon these insights, we propose Geodesic Aggregation, a manifold--aware mechanism that aggregates neighbor information along geodesics via log--exp mappings on the unit sphere, ensuring that representations remain faithful to the semantic manifold during message passing. We further develop GeoGNN, a practical instantiation that integrates spherical attention with manifold interpolation. Extensive experiments across four benchmark datasets and multiple text encoders show that GeoGNN substantially mitigates semantic drift and consistently outperforms strong baselines, establishing the importance of manifold--aware aggregation in text--attributed graph learning.
LoCoBench: A Benchmark for Long-Context Large Language Models in Complex Software Engineering
Sep 11, 2025
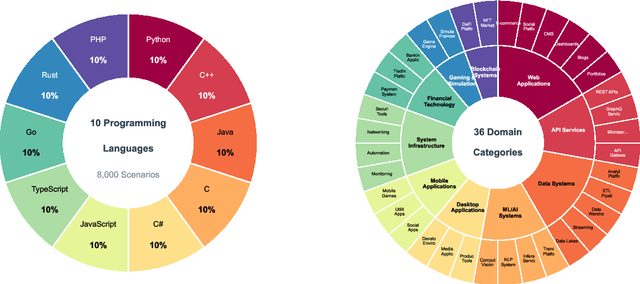

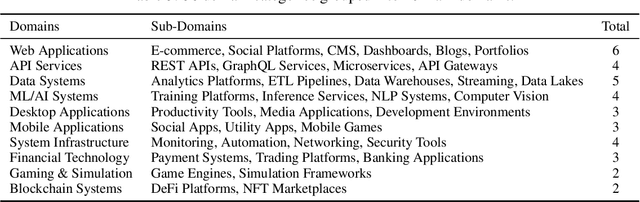
The emergence of long-context language models with context windows extending to millions of tokens has created new opportunities for sophisticated code understanding and software development evaluation. We propose LoCoBench, a comprehensive benchmark specifically designed to evaluate long-context LLMs in realistic, complex software development scenarios. Unlike existing code evaluation benchmarks that focus on single-function completion or short-context tasks, LoCoBench addresses the critical evaluation gap for long-context capabilities that require understanding entire codebases, reasoning across multiple files, and maintaining architectural consistency across large-scale software systems. Our benchmark provides 8,000 evaluation scenarios systematically generated across 10 programming languages, with context lengths spanning 10K to 1M tokens, a 100x variation that enables precise assessment of long-context performance degradation in realistic software development settings. LoCoBench introduces 8 task categories that capture essential long-context capabilities: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis. Through a 5-phase pipeline, we create diverse, high-quality scenarios that challenge LLMs to reason about complex codebases at unprecedented scale. We introduce a comprehensive evaluation framework with 17 metrics across 4 dimensions, including 8 new evaluation metrics, combined in a LoCoBench Score (LCBS). Our evaluation of state-of-the-art long-context models reveals substantial performance gaps, demonstrating that long-context understanding in complex software development represents a significant unsolved challenge that demands more attention. LoCoBench is released at: https://github.com/SalesforceAIResearch/LoCoBench.
PersonaBench: Evaluating AI Models on Understanding Personal Information through Accessing (Synthetic) Private User Data
Feb 28, 2025Personalization is critical in AI assistants, particularly in the context of private AI models that work with individual users. A key scenario in this domain involves enabling AI models to access and interpret a user's private data (e.g., conversation history, user-AI interactions, app usage) to understand personal details such as biographical information, preferences, and social connections. However, due to the sensitive nature of such data, there are no publicly available datasets that allow us to assess an AI model's ability to understand users through direct access to personal information. To address this gap, we introduce a synthetic data generation pipeline that creates diverse, realistic user profiles and private documents simulating human activities. Leveraging this synthetic data, we present PersonaBench, a benchmark designed to evaluate AI models' performance in understanding personal information derived from simulated private user data. We evaluate Retrieval-Augmented Generation (RAG) pipelines using questions directly related to a user's personal information, supported by the relevant private documents provided to the models. Our results reveal that current retrieval-augmented AI models struggle to answer private questions by extracting personal information from user documents, highlighting the need for improved methodologies to enhance personalization capabilities in AI.
SpecTool: A Benchmark for Characterizing Errors in Tool-Use LLMs
Nov 20, 2024



Evaluating the output of Large Language Models (LLMs) is one of the most critical aspects of building a performant compound AI system. Since the output from LLMs propagate to downstream steps, identifying LLM errors is crucial to system performance. A common task for LLMs in AI systems is tool use. While there are several benchmark environments for evaluating LLMs on this task, they typically only give a success rate without any explanation of the failure cases. To solve this problem, we introduce SpecTool, a new benchmark to identify error patterns in LLM output on tool-use tasks. Our benchmark data set comprises of queries from diverse environments that can be used to test for the presence of seven newly characterized error patterns. Using SPECTOOL , we show that even the most prominent LLMs exhibit these error patterns in their outputs. Researchers can use the analysis and insights from SPECTOOL to guide their error mitigation strategies.
PRACT: Optimizing Principled Reasoning and Acting of LLM Agent
Oct 24, 2024



We introduce the Principled Reasoning and Acting (PRAct) framework, a novel method for learning and enforcing action principles from trajectory data. Central to our approach is the use of text gradients from a reflection and optimization engine to derive these action principles. To adapt action principles to specific task requirements, we propose a new optimization framework, Reflective Principle Optimization (RPO). After execution, RPO employs a reflector to critique current action principles and an optimizer to update them accordingly. We develop the RPO framework under two scenarios: Reward-RPO, which uses environmental rewards for reflection, and Self-RPO, which conducts self-reflection without external rewards. Additionally, two RPO methods, RPO-Traj and RPO-Batch, is introduced to adapt to different settings. Experimental results across four environments demonstrate that the PRAct agent, leveraging the RPO framework, effectively learns and applies action principles to enhance performance.
xLAM: A Family of Large Action Models to Empower AI Agent Systems
Sep 05, 2024



Autonomous agents powered by large language models (LLMs) have attracted significant research interest. However, the open-source community faces many challenges in developing specialized models for agent tasks, driven by the scarcity of high-quality agent datasets and the absence of standard protocols in this area. We introduce and publicly release xLAM, a series of large action models designed for AI agent tasks. The xLAM series includes five models with both dense and mixture-of-expert architectures, ranging from 1B to 8x22B parameters, trained using a scalable, flexible pipeline that unifies, augments, and synthesizes diverse datasets to enhance AI agents' generalizability and performance across varied environments. Our experimental results demonstrate that xLAM consistently delivers exceptional performance across multiple agent ability benchmarks, notably securing the 1st position on the Berkeley Function-Calling Leaderboard, outperforming GPT-4, Claude-3, and many other models in terms of tool use. By releasing the xLAM series, we aim to advance the performance of open-source LLMs for autonomous AI agents, potentially accelerating progress and democratizing access to high-performance models for agent tasks. Models are available at https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4
Diversity Empowers Intelligence: Integrating Expertise of Software Engineering Agents
Aug 13, 2024Large language model (LLM) agents have shown great potential in solving real-world software engineering (SWE) problems. The most advanced open-source SWE agent can resolve over 27% of real GitHub issues in SWE-Bench Lite. However, these sophisticated agent frameworks exhibit varying strengths, excelling in certain tasks while underperforming in others. To fully harness the diversity of these agents, we propose DEI (Diversity Empowered Intelligence), a framework that leverages their unique expertise. DEI functions as a meta-module atop existing SWE agent frameworks, managing agent collectives for enhanced problem-solving. Experimental results show that a DEI-guided committee of agents is able to surpass the best individual agent's performance by a large margin. For instance, a group of open-source SWE agents, with a maximum individual resolve rate of 27.3% on SWE-Bench Lite, can achieve a 34.3% resolve rate with DEI, making a 25% improvement and beating most closed-source solutions. Our best-performing group excels with a 55% resolve rate, securing the highest ranking on SWE-Bench Lite. Our findings contribute to the growing body of research on collaborative AI systems and their potential to solve complex software engineering challenges.