 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDASH: Fast Differentiable Architecture Search for Hybrid Attention in Minutes on a Single GPU
May 20, 2026Hybrid attention architectures are becoming an increasingly important paradigm for improving LLM inference efficiency while preserving model quality, making hybrid architecture design a central problem. Existing designs often rely on manual empirical rules or proxy-based selector signals for layer-wise operator allocation. Recent NAS-style systems such as Jet-Nemotron demonstrate the promise of automated hybrid architecture search. However, Jet-Nemotron's PostNAS search stages alone use 200B tokens, making such search pipelines difficult to use as routine methods for hybrid architecture design. We introduce DASH, a fast differentiable search framework for hybrid attention architecture design, which relaxes discrete layer-wise attention operator placement into continuous architecture logits, prepares reusable teacher-aligned linear candidates, and performs architecture-only search with model and operator weights frozen to significantly enhance search efficiency. On Qwen2.5-3B-Instruct, DASH consistently outperforms a comprehensive suite of existing selector-style hybrid attention design baselines, showing that direct differentiable search can discover stronger hybrid architectures. Moreover, DASH achieves stronger RULER performance than released Jet-Nemotron models while remaining competitive on overlapping short-context and general benchmarks. Notably, each DASH search run uses only 12.3M tokens and takes about 20 minutes on a single RTX Pro 6000 GPU, corresponding to merely 0.006% of the PostNAS search tokens reported by Jet-Nemotron. These results suggest that high-quality hybrid attention architectures can be obtained through minutes-level differentiable search, providing a promising direction for hybrid architecture design.
Oxygen vacancies modulated VO2 for neurons and Spiking Neural Network construction
Apr 16, 2024



Artificial neuronal devices are the basic building blocks for neuromorphic computing systems, which have been motivated by realistic brain emulation. Aiming for these applications, various device concepts have been proposed to mimic the neuronal dynamics and functions. While till now, the artificial neuron devices with high efficiency, high stability and low power consumption are still far from practical application. Due to the special insulator-metal phase transition, Vanadium Dioxide (VO2) has been considered as an idea candidate for neuronal device fabrication. However, its intrinsic insulating state requires the VO2 neuronal device to be driven under large bias voltage, resulting in high power consumption and low frequency. Thus in the current study, we have addressed this challenge by preparing oxygen vacancies modulated VO2 film(VO2-x) and fabricating the VO2-x neuronal devices for Spiking Neural Networks (SNNs) construction. Results indicate the neuron devices can be operated under lower voltage with improved processing speed. The proposed VO2-x based back-propagation SNNs (BP-SNNs) system, trained with the MNIST dataset, demonstrates excellent accuracy in image recognition. Our study not only demonstrates the VO2-x based neurons and SNN system for practical application, but also offers an effective way to optimize the future neuromorphic computing systems by defect engineering strategy.
STURE: Spatial-Temporal Mutual Representation Learning for Robust Data Association in Online Multi-Object Tracking
Jan 19, 2022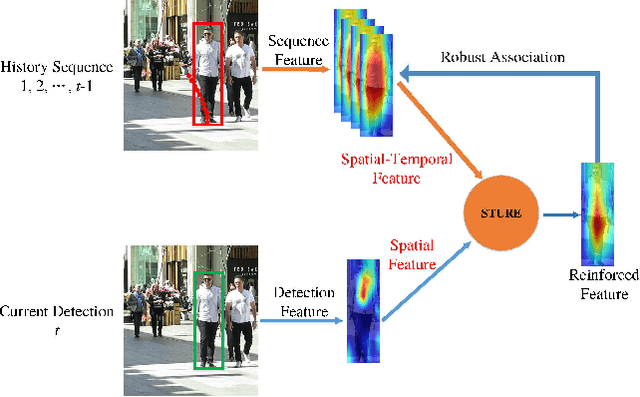
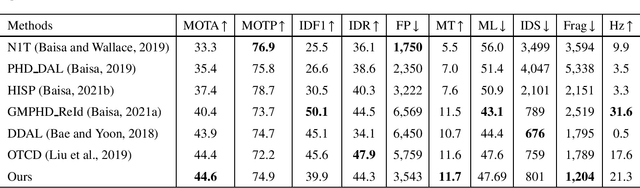
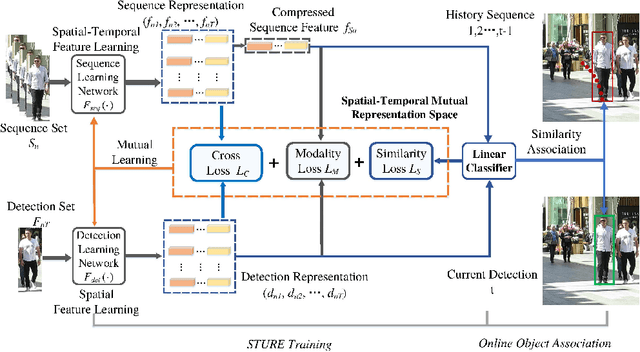
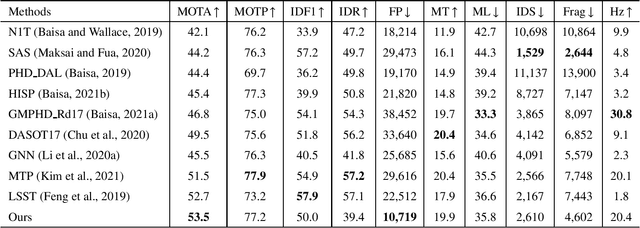
Online multi-object tracking (MOT) is a longstanding task for computer vision and intelligent vehicle platform. At present, the main paradigm is tracking-by-detection, and the main difficulty of this paradigm is how to associate the current candidate detection with the historical tracklets. However, in the MOT scenarios, each historical tracklet is composed of an object sequence, while each candidate detection is just a flat image, which lacks the temporal features of the object sequence. The feature difference between current candidate detection and historical tracklets makes the object association much harder. Therefore, we propose a Spatial-Temporal Mutual {Representation} Learning (STURE) approach which learns spatial-temporal representations between current candidate detection and historical sequence in a mutual representation space. For the historical trackelets, the detection learning network is forced to match the representations of sequence learning network in a mutual representation space. The proposed approach is capable of extracting more distinguishing detection and sequence representations by using various designed losses in object association. As a result, spatial-temporal feature is learned mutually to reinforce the current detection features, and the feature difference can be relieved. To prove the robustness of the STURE, it is applied to the public MOT challenge benchmarks and performs well compared with various state-of-the-art online MOT trackers based on identity-preserving metrics.