 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging BCI and Communications: A MIMO Framework for EEG-to-ECoG Wireless Channel Modeling
May 16, 2025As a method to connect human brain and external devices, Brain-computer interfaces (BCIs) are receiving extensive research attention. Recently, the integration of communication theory with BCI has emerged as a popular trend, offering potential to enhance system performance and shape next-generation communications. A key challenge in this field is modeling the brain wireless communication channel between intracranial electrocorticography (ECoG) emitting neurons and extracranial electroencephalography (EEG) receiving electrodes. However, the complex physiology of brain challenges the application of traditional channel modeling methods, leaving relevant research in its infancy. To address this gap, we propose a frequency-division multiple-input multiple-output (MIMO) estimation framework leveraging simultaneous macaque EEG and ECoG recordings, while employing neurophysiology-informed regularization to suppress noise interference. This approach reveals profound similarities between neural signal propagation and multi-antenna communication systems. Experimental results show improved estimation accuracy over conventional methods while highlighting a trade-off between frequency resolution and temporal stability determined by signal duration. This work establish a conceptual bridge between neural interfacing and communication theory, accelerating synergistic developments in both fields.
HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data
Dec 23, 2024



In the domain of Multimodal Large Language Models (MLLMs), achieving human-centric video understanding remains a formidable challenge. Existing benchmarks primarily emphasize object and action recognition, often neglecting the intricate nuances of human emotions, behaviors, and speech visual alignment within video content. We present HumanVBench, an innovative benchmark meticulously crafted to bridge these gaps in the evaluation of video MLLMs. HumanVBench comprises 17 carefully designed tasks that explore two primary dimensions: inner emotion and outer manifestations, spanning static and dynamic, basic and complex, as well as single-modal and cross-modal aspects. With two advanced automated pipelines for video annotation and distractor-included QA generation, HumanVBench utilizes diverse state-of-the-art (SOTA) techniques to streamline benchmark data synthesis and quality assessment, minimizing human annotation dependency tailored to human-centric multimodal attributes. A comprehensive evaluation across 16 SOTA video MLLMs reveals notable limitations in current performance, especially in cross-modal and temporal alignment, underscoring the necessity for further refinement toward achieving more human-like understanding. HumanVBench is open-sourced to facilitate future advancements and real-world applications in video MLLMs.
Oxygen vacancies modulated VO2 for neurons and Spiking Neural Network construction
Apr 16, 2024



Artificial neuronal devices are the basic building blocks for neuromorphic computing systems, which have been motivated by realistic brain emulation. Aiming for these applications, various device concepts have been proposed to mimic the neuronal dynamics and functions. While till now, the artificial neuron devices with high efficiency, high stability and low power consumption are still far from practical application. Due to the special insulator-metal phase transition, Vanadium Dioxide (VO2) has been considered as an idea candidate for neuronal device fabrication. However, its intrinsic insulating state requires the VO2 neuronal device to be driven under large bias voltage, resulting in high power consumption and low frequency. Thus in the current study, we have addressed this challenge by preparing oxygen vacancies modulated VO2 film(VO2-x) and fabricating the VO2-x neuronal devices for Spiking Neural Networks (SNNs) construction. Results indicate the neuron devices can be operated under lower voltage with improved processing speed. The proposed VO2-x based back-propagation SNNs (BP-SNNs) system, trained with the MNIST dataset, demonstrates excellent accuracy in image recognition. Our study not only demonstrates the VO2-x based neurons and SNN system for practical application, but also offers an effective way to optimize the future neuromorphic computing systems by defect engineering strategy.
Federated Dynamic Neural Network for Deep MIMO Detection
Nov 24, 2021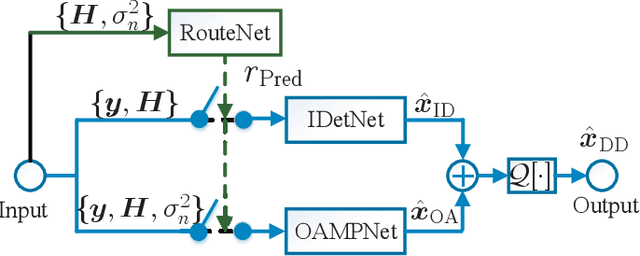
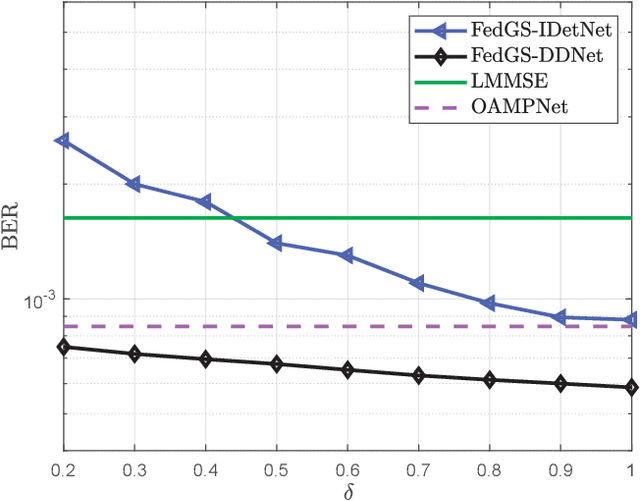
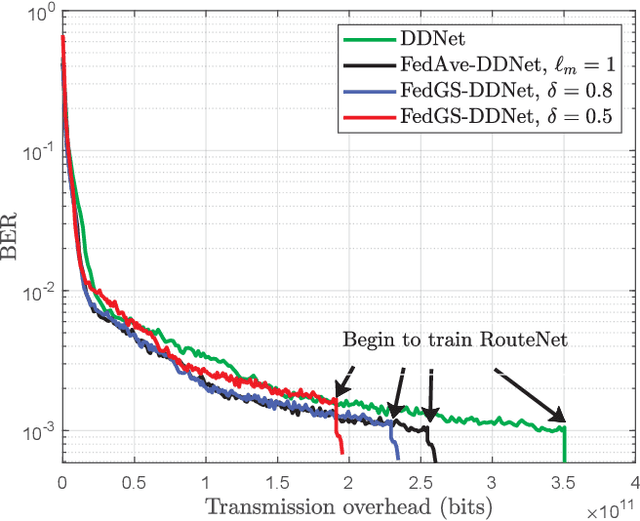
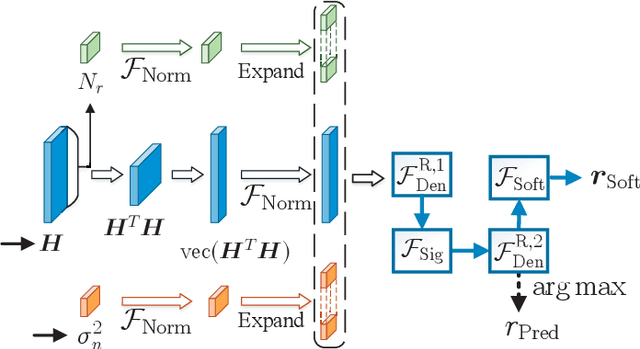
In this paper, we develop a dynamic detection network (DDNet) based detector for multiple-input multiple-output (MIMO) systems. By constructing an improved DetNet (IDetNet) detector and the OAMPNet detector as two independent network branches, the DDNet detector performs sample-wise dynamic routing to adaptively select a better one between the IDetNet and the OAMPNet detectors for every samples under different system conditions. To avoid the prohibitive transmission overhead of dataset collection in centralized learning (CL), we propose the federated averaging (FedAve)-DDNet detector, where all raw data are kept at local clients and only locally trained model parameters are transmitted to the central server for aggregation. To further reduce the transmission overhead, we develop the federated gradient sparsification (FedGS)-DDNet detector by randomly sampling gradients with elaborately calculated probability when uploading gradients to the central server. Based on simulation results, the proposed DDNet detector consistently outperforms other detectors under all system conditions thanks to the sample-wise dynamic routing. Moreover, the federated DDNet detectors, especially the FedGS-DDNet detector, can reduce the transmission overhead by at least 25.7\% while maintaining satisfactory detection accuracy.
Joint Channel Estimation and Mixed-ADCs Allocation for Massive MIMO via Deep Learning
Jun 08, 2021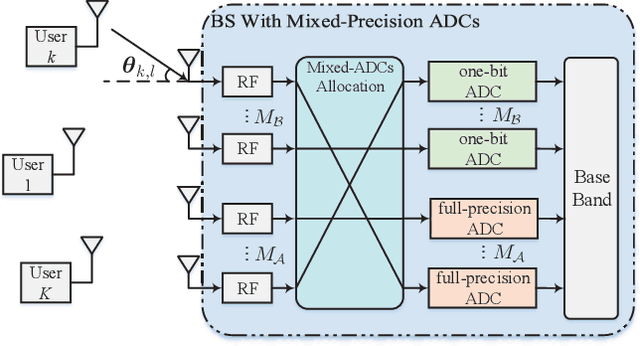
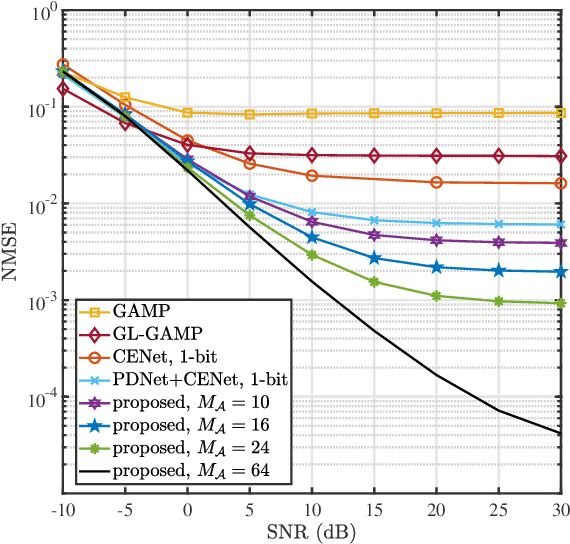
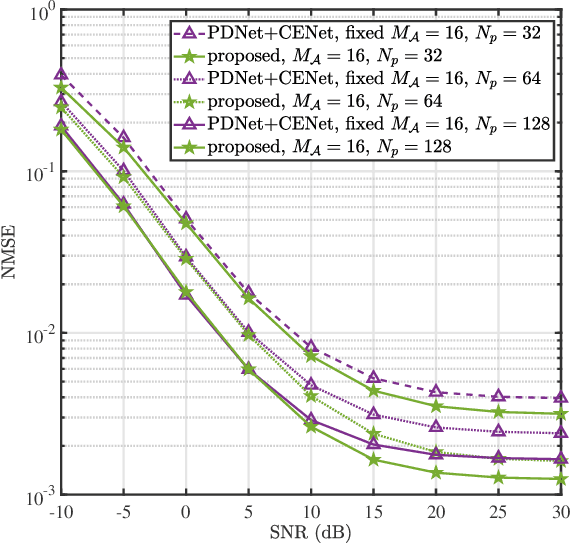
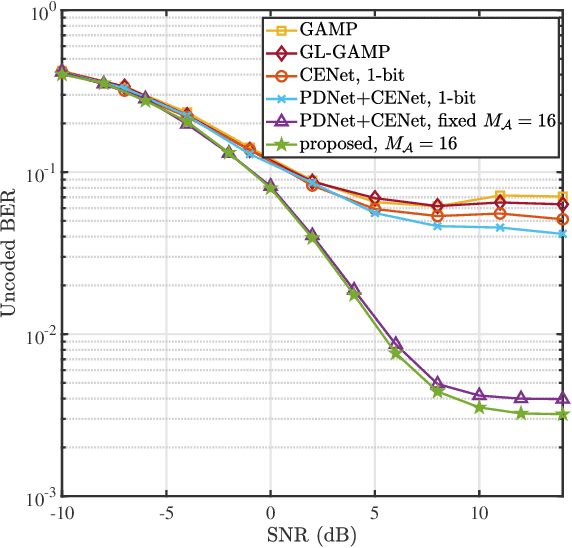
Millimeter wave (mmWave) multi-user massive multi-input multi-output (MIMO) is a promising technique for the next generation communication systems. However, the hardware cost and power consumption grow significantly as the number of radio frequency (RF) components increases, which hampers the deployment of practical massive MIMO systems. To address this issue and further facilitate the commercialization of massive MIMO, mixed analog-to-digital converters (ADCs) architecture has been considered, where parts of conventionally assumed full-resolution ADCs are replaced by one-bit ADCs. In this paper, we first propose a deep learning-based (DL) joint pilot design and channel estimation method for mixed-ADCs mmWave massive MIMO. Specifically, we devise a pilot design neural network whose weights directly represent the optimized pilots, and develop a Runge-Kutta model-driven densely connected network as the channel estimator. Instead of randomly assigning the mixed-ADCs, we then design a novel antenna selection network for mixed-ADCs allocation to further improve the channel estimation accuracy. Moreover, we adopt an autoencoder-inspired end-to-end architecture to jointly optimize the pilot design, channel estimation and mixed-ADCs allocation networks. Simulation results show that the proposed DL-based methods have advantages over the traditional channel estimators as well as the state-of-the-art networks.
Deep Unsupervised Learning for Joint Antenna Selection and Hybrid Beamforming
Jun 06, 2021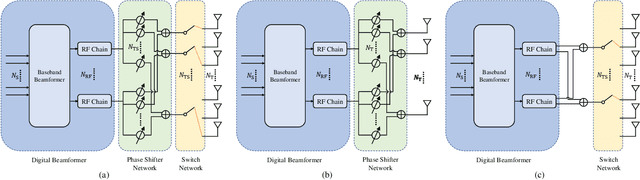
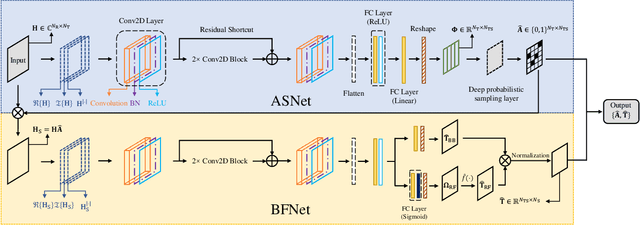
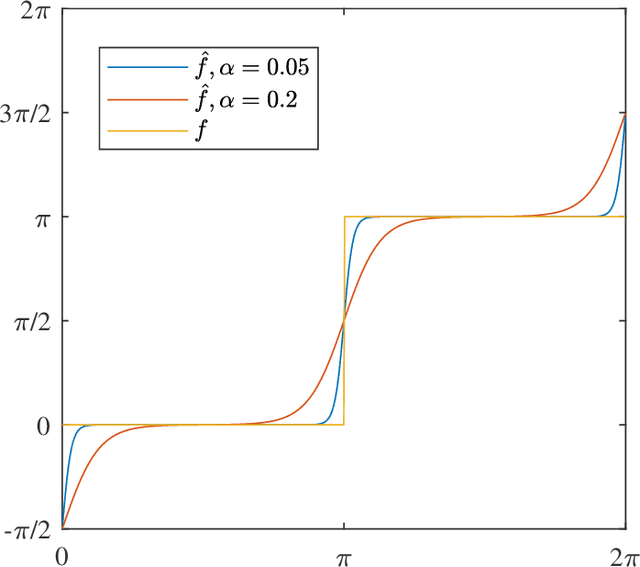
In this paper, we consider a massive multiple-input-multiple-output (MIMO) downlink system that improves the hardware efficiency by dynamically selecting the antenna subarray and utilizing 1-bit phase shifters for hybrid beamforming. To maximize the spectral efficiency, we propose a novel deep unsupervised learning-based approach that avoids the computationally prohibitive process of acquiring training labels. The proposed design has its input as the channel matrix and consists of two convolutional neural networks (CNNs). To enable unsupervised training, the problem constraints are embedded in the neural networks: the first CNN adopts deep probabilistic sampling, while the second CNN features a quantization layer designed for 1-bit phase shifters. The two networks can be trained jointly without labels by sharing an unsupervised loss function. We next propose a phased training approach to promote the convergence of the proposed networks. Simulation results demonstrate the advantage of the proposed approach over conventional optimization-based algorithms in terms of both achieved rate and computational complexity.
Deep Learning based Antenna Selection and CSI Extrapolation in Massive MIMO Systems
Jan 18, 2021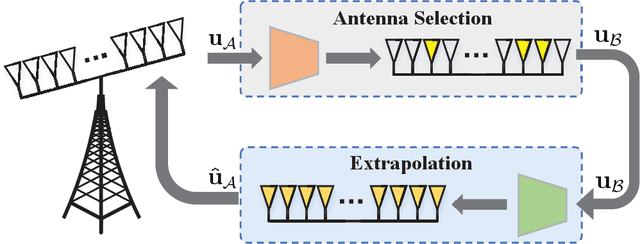
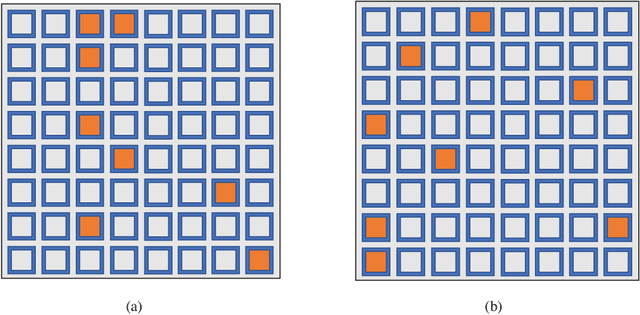
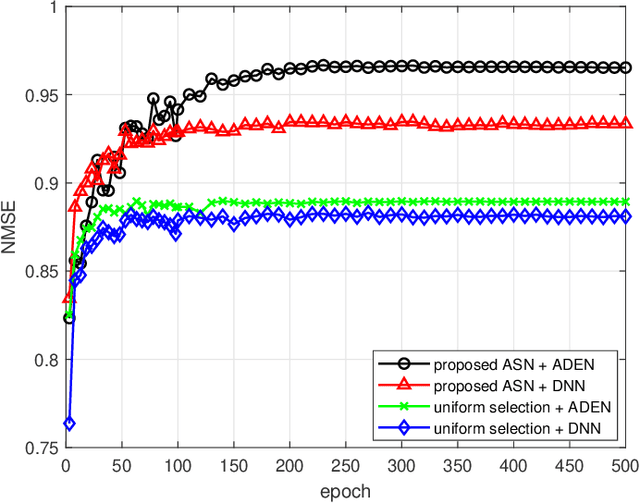
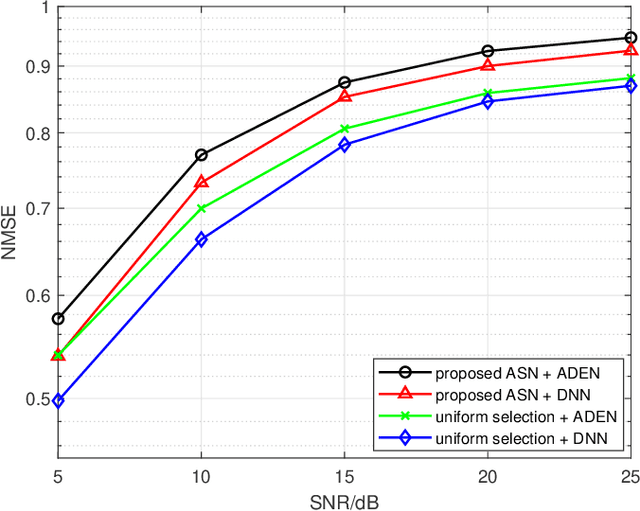
A critical bottleneck of massive multiple-input multiple-output (MIMO) system is the huge training overhead caused by downlink transmission, like channel estimation, downlink beamforming and covariance observation. In this paper, we propose to use the channel state information (CSI) of a small number of antennas to extrapolate the CSI of the other antennas and reduce the training overhead. Specifically, we design a deep neural network that we call an antenna domain extrapolation network (ADEN) that can exploit the correlation function among antennas. We then propose a deep learning (DL) based antenna selection network (ASN) that can select a limited antennas for optimizing the extrapolation, which is conventionally a type of combinatorial optimization and is difficult to solve. We trickly designed a constrained degradation algorithm to generate a differentiable approximation of the discrete antenna selection vector such that the back-propagation of the neural network can be guaranteed. Numerical results show that the proposed ADEN outperforms the traditional fully connected one, and the antenna selection scheme learned by ASN is much better than the trivially used uniform selection.