 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefine-by-Align: Reference-Guided Artifacts Refinement through Semantic Alignment
Nov 30, 2024


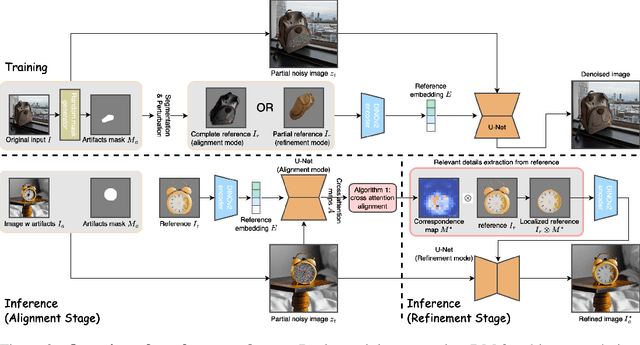
Personalized image generation has emerged from the recent advancements in generative models. However, these generated personalized images often suffer from localized artifacts such as incorrect logos, reducing fidelity and fine-grained identity details of the generated results. Furthermore, there is little prior work tackling this problem. To help improve these identity details in the personalized image generation, we introduce a new task: reference-guided artifacts refinement. We present Refine-by-Align, a first-of-its-kind model that employs a diffusion-based framework to address this challenge. Our model consists of two stages: Alignment Stage and Refinement Stage, which share weights of a unified neural network model. Given a generated image, a masked artifact region, and a reference image, the alignment stage identifies and extracts the corresponding regional features in the reference, which are then used by the refinement stage to fix the artifacts. Our model-agnostic pipeline requires no test-time tuning or optimization. It automatically enhances image fidelity and reference identity in the generated image, generalizing well to existing models on various tasks including but not limited to customization, generative compositing, view synthesis, and virtual try-on. Extensive experiments and comparisons demonstrate that our pipeline greatly pushes the boundary of fine details in the image synthesis models.
FINECAPTION: Compositional Image Captioning Focusing on Wherever You Want at Any Granularity
Nov 23, 2024



The advent of large Vision-Language Models (VLMs) has significantly advanced multimodal tasks, enabling more sophisticated and accurate reasoning across various applications, including image and video captioning, visual question answering, and cross-modal retrieval. Despite their superior capabilities, VLMs struggle with fine-grained image regional composition information perception. Specifically, they have difficulty accurately aligning the segmentation masks with the corresponding semantics and precisely describing the compositional aspects of the referred regions. However, compositionality - the ability to understand and generate novel combinations of known visual and textual components - is critical for facilitating coherent reasoning and understanding across modalities by VLMs. To address this issue, we propose FINECAPTION, a novel VLM that can recognize arbitrary masks as referential inputs and process high-resolution images for compositional image captioning at different granularity levels. To support this endeavor, we introduce COMPOSITIONCAP, a new dataset for multi-grained region compositional image captioning, which introduces the task of compositional attribute-aware regional image captioning. Empirical results demonstrate the effectiveness of our proposed model compared to other state-of-the-art VLMs. Additionally, we analyze the capabilities of current VLMs in recognizing various visual prompts for compositional region image captioning, highlighting areas for improvement in VLM design and training.
Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-stage Image-to-3D Generation
Nov 21, 2024



Existing feed-forward image-to-3D methods mainly rely on 2D multi-view diffusion models that cannot guarantee 3D consistency. These methods easily collapse when changing the prompt view direction and mainly handle object-centric prompt images. In this paper, we propose a novel single-stage 3D diffusion model, DiffusionGS, for object and scene generation from a single view. DiffusionGS directly outputs 3D Gaussian point clouds at each timestep to enforce view consistency and allow the model to generate robustly given prompt views of any directions, beyond object-centric inputs. Plus, to improve the capability and generalization ability of DiffusionGS, we scale up 3D training data by developing a scene-object mixed training strategy. Experiments show that our method enjoys better generation quality (2.20 dB higher in PSNR and 23.25 lower in FID) and over 5x faster speed (~6s on an A100 GPU) than SOTA methods. The user study and text-to-3D applications also reveals the practical values of our method. Our Project page at https://caiyuanhao1998.github.io/project/DiffusionGS/ shows the video and interactive generation results.
Thinking Outside the BBox: Unconstrained Generative Object Compositing
Sep 11, 2024Compositing an object into an image involves multiple non-trivial sub-tasks such as object placement and scaling, color/lighting harmonization, viewpoint/geometry adjustment, and shadow/reflection generation. Recent generative image compositing methods leverage diffusion models to handle multiple sub-tasks at once. However, existing models face limitations due to their reliance on masking the original object during training, which constrains their generation to the input mask. Furthermore, obtaining an accurate input mask specifying the location and scale of the object in a new image can be highly challenging. To overcome such limitations, we define a novel problem of unconstrained generative object compositing, i.e., the generation is not bounded by the mask, and train a diffusion-based model on a synthesized paired dataset. Our first-of-its-kind model is able to generate object effects such as shadows and reflections that go beyond the mask, enhancing image realism. Additionally, if an empty mask is provided, our model automatically places the object in diverse natural locations and scales, accelerating the compositing workflow. Our model outperforms existing object placement and compositing models in various quality metrics and user studies.
WAS: Dataset and Methods for Artistic Text Segmentation
Jul 31, 2024



Accurate text segmentation results are crucial for text-related generative tasks, such as text image generation, text editing, text removal, and text style transfer. Recently, some scene text segmentation methods have made significant progress in segmenting regular text. However, these methods perform poorly in scenarios containing artistic text. Therefore, this paper focuses on the more challenging task of artistic text segmentation and constructs a real artistic text segmentation dataset. One challenge of the task is that the local stroke shapes of artistic text are changeable with diversity and complexity. We propose a decoder with the layer-wise momentum query to prevent the model from ignoring stroke regions of special shapes. Another challenge is the complexity of the global topological structure. We further design a skeleton-assisted head to guide the model to focus on the global structure. Additionally, to enhance the generalization performance of the text segmentation model, we propose a strategy for training data synthesis, based on the large multi-modal model and the diffusion model. Experimental results show that our proposed method and synthetic dataset can significantly enhance the performance of artistic text segmentation and achieve state-of-the-art results on other public datasets.
Establishing Rigorous and Cost-effective Clinical Trials for Artificial Intelligence Models
Jul 11, 2024



A profound gap persists between artificial intelligence (AI) and clinical practice in medicine, primarily due to the lack of rigorous and cost-effective evaluation methodologies. State-of-the-art and state-of-the-practice AI model evaluations are limited to laboratory studies on medical datasets or direct clinical trials with no or solely patient-centered controls. Moreover, the crucial role of clinicians in collaborating with AI, pivotal for determining its impact on clinical practice, is often overlooked. For the first time, we emphasize the critical necessity for rigorous and cost-effective evaluation methodologies for AI models in clinical practice, featuring patient/clinician-centered (dual-centered) AI randomized controlled trials (DC-AI RCTs) and virtual clinician-based in-silico trials (VC-MedAI) as an effective proxy for DC-AI RCTs. Leveraging 7500 diagnosis records from two-phase inaugural DC-AI RCTs across 14 medical centers with 125 clinicians, our results demonstrate the necessity of DC-AI RCTs and the effectiveness of VC-MedAI. Notably, VC-MedAI performs comparably to human clinicians, replicating insights and conclusions from prospective DC-AI RCTs. We envision DC-AI RCTs and VC-MedAI as pivotal advancements, presenting innovative and transformative evaluation methodologies for AI models in clinical practice, offering a preclinical-like setting mirroring conventional medicine, and reshaping development paradigms in a cost-effective and fast-iterative manner. Chinese Clinical Trial Registration: ChiCTR2400086816.
SwapAnything: Enabling Arbitrary Object Swapping in Personalized Visual Editing
Apr 08, 2024



Effective editing of personal content holds a pivotal role in enabling individuals to express their creativity, weaving captivating narratives within their visual stories, and elevate the overall quality and impact of their visual content. Therefore, in this work, we introduce SwapAnything, a novel framework that can swap any objects in an image with personalized concepts given by the reference, while keeping the context unchanged. Compared with existing methods for personalized subject swapping, SwapAnything has three unique advantages: (1) precise control of arbitrary objects and parts rather than the main subject, (2) more faithful preservation of context pixels, (3) better adaptation of the personalized concept to the image. First, we propose targeted variable swapping to apply region control over latent feature maps and swap masked variables for faithful context preservation and initial semantic concept swapping. Then, we introduce appearance adaptation, to seamlessly adapt the semantic concept into the original image in terms of target location, shape, style, and content during the image generation process. Extensive results on both human and automatic evaluation demonstrate significant improvements of our approach over baseline methods on personalized swapping. Furthermore, SwapAnything shows its precise and faithful swapping abilities across single object, multiple objects, partial object, and cross-domain swapping tasks. SwapAnything also achieves great performance on text-based swapping and tasks beyond swapping such as object insertion.
IMPRINT: Generative Object Compositing by Learning Identity-Preserving Representation
Mar 15, 2024



Generative object compositing emerges as a promising new avenue for compositional image editing. However, the requirement of object identity preservation poses a significant challenge, limiting practical usage of most existing methods. In response, this paper introduces IMPRINT, a novel diffusion-based generative model trained with a two-stage learning framework that decouples learning of identity preservation from that of compositing. The first stage is targeted for context-agnostic, identity-preserving pretraining of the object encoder, enabling the encoder to learn an embedding that is both view-invariant and conducive to enhanced detail preservation. The subsequent stage leverages this representation to learn seamless harmonization of the object composited to the background. In addition, IMPRINT incorporates a shape-guidance mechanism offering user-directed control over the compositing process. Extensive experiments demonstrate that IMPRINT significantly outperforms existing methods and various baselines on identity preservation and composition quality.
PatSTEG: Modeling Formation Dynamics of Patent Citation Networks via The Semantic-Topological Evolutionary Graph
Feb 03, 2024Patent documents in the patent database (PatDB) are crucial for research, development, and innovation as they contain valuable technical information. However, PatDB presents a multifaceted challenge compared to publicly available preprocessed databases due to the intricate nature of the patent text and the inherent sparsity within the patent citation network. Although patent text analysis and citation analysis bring new opportunities to explore patent data mining, no existing work exploits the complementation of them. To this end, we propose a joint semantic-topological evolutionary graph learning approach (PatSTEG) to model the formation dynamics of patent citation networks. More specifically, we first create a real-world dataset of Chinese patents named CNPat and leverage its patent texts and citations to construct a patent citation network. Then, PatSTEG is modeled to study the evolutionary dynamics of patent citation formation by considering the semantic and topological information jointly. Extensive experiments are conducted on CNPat and public datasets to prove the superiority of PatSTEG over other state-of-the-art methods. All the results provide valuable references for patent literature research and technical exploration.
OpenClinicalAI: An Open and Dynamic Model for Alzheimer's Disease Diagnosis
Jul 03, 2023



Although Alzheimer's disease (AD) cannot be reversed or cured, timely diagnosis can significantly reduce the burden of treatment and care. Current research on AD diagnosis models usually regards the diagnosis task as a typical classification task with two primary assumptions: 1) All target categories are known a priori; 2) The diagnostic strategy for each patient is consistent, that is, the number and type of model input data for each patient are the same. However, real-world clinical settings are open, with complexity and uncertainty in terms of both subjects and the resources of the medical institutions. This means that diagnostic models may encounter unseen disease categories and need to dynamically develop diagnostic strategies based on the subject's specific circumstances and available medical resources. Thus, the AD diagnosis task is tangled and coupled with the diagnosis strategy formulation. To promote the application of diagnostic systems in real-world clinical settings, we propose OpenClinicalAI for direct AD diagnosis in complex and uncertain clinical settings. This is the first powerful end-to-end model to dynamically formulate diagnostic strategies and provide diagnostic results based on the subject's conditions and available medical resources. OpenClinicalAI combines reciprocally coupled deep multiaction reinforcement learning (DMARL) for diagnostic strategy formulation and multicenter meta-learning (MCML) for open-set recognition. The experimental results show that OpenClinicalAI achieves better performance and fewer clinical examinations than the state-of-the-art model. Our method provides an opportunity to embed the AD diagnostic system into the current health care system to cooperate with clinicians to improve current health care.