 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConflated Inverse Modeling to Generate Diverse and Temperature-Change Inducing Urban Vegetation Patterns
Apr 14, 2026Urban areas are increasingly vulnerable to thermal extremes driven by rapid urbanization and climate change. Traditionally, thermal extremes have been monitored using Earth-observing satellites and numerical modeling frameworks. For example, land surface temperature derived from Landsat or Sentinel imagery is commonly used to characterize surface heating patterns. These approaches operate as forward models, translating radiative observations or modeled boundary conditions into estimates of surface thermal states. While forward models can predict land surface temperature from vegetation and urban form, the inverse problem of determining spatial vegetation configurations that achieve a desired regional temperature shift remains largely unexplored. This task is inherently underdetermined, as multiple spatial vegetation patterns can yield similar aggregated temperature responses. Conventional regression and deterministic neural networks fail to capture this ambiguity and often produce averaged solutions, particularly under data-scarce conditions. We propose a conflated inverse modeling framework that combines a predictive forward model with a diffusion-based generative inverse model to produce diverse, physically plausible image-based vegetation patterns conditioned on specific temperature goals. Our framework maintains control over thermal outcomes while enabling diverse spatial vegetation configurations, even when such combinations are absent from training data. Altogether, this work introduces a controllable inverse modeling approach for urban climate adaptation that accounts for the inherent diversity of the problem. Code is available at the GitHub repository.
MMIG-Bench: Towards Comprehensive and Explainable Evaluation of Multi-Modal Image Generation Models
May 26, 2025Recent multimodal image generators such as GPT-4o, Gemini 2.0 Flash, and Gemini 2.5 Pro excel at following complex instructions, editing images and maintaining concept consistency. However, they are still evaluated by disjoint toolkits: text-to-image (T2I) benchmarks that lacks multi-modal conditioning, and customized image generation benchmarks that overlook compositional semantics and common knowledge. We propose MMIG-Bench, a comprehensive Multi-Modal Image Generation Benchmark that unifies these tasks by pairing 4,850 richly annotated text prompts with 1,750 multi-view reference images across 380 subjects, spanning humans, animals, objects, and artistic styles. MMIG-Bench is equipped with a three-level evaluation framework: (1) low-level metrics for visual artifacts and identity preservation of objects; (2) novel Aspect Matching Score (AMS): a VQA-based mid-level metric that delivers fine-grained prompt-image alignment and shows strong correlation with human judgments; and (3) high-level metrics for aesthetics and human preference. Using MMIG-Bench, we benchmark 17 state-of-the-art models, including Gemini 2.5 Pro, FLUX, DreamBooth, and IP-Adapter, and validate our metrics with 32k human ratings, yielding in-depth insights into architecture and data design. We will release the dataset and evaluation code to foster rigorous, unified evaluation and accelerate future innovations in multi-modal image generation.
Self-Supervised Large Scale Point Cloud Completion for Archaeological Site Restoration
Mar 06, 2025Point cloud completion helps restore partial incomplete point clouds suffering occlusions. Current self-supervised methods fail to give high fidelity completion for large objects with missing surfaces and unbalanced distribution of available points. In this paper, we present a novel method for restoring large-scale point clouds with limited and imbalanced ground-truth. Using rough boundary annotations for a region of interest, we project the original point clouds into a multiple-center-of-projection (MCOP) image, where fragments are projected to images of 5 channels (RGB, depth, and rotation). Completion of the original point cloud is reduced to inpainting the missing pixels in the MCOP images. Due to lack of complete structures and an unbalanced distribution of existing parts, we develop a self-supervised scheme which learns to infill the MCOP image with points resembling existing "complete" patches. Special losses are applied to further enhance the regularity and consistency of completed MCOP images, which is mapped back to 3D to form final restoration. Extensive experiments demonstrate the superiority of our method in completing 600+ incomplete and unbalanced archaeological structures in Peru.
Refine-by-Align: Reference-Guided Artifacts Refinement through Semantic Alignment
Nov 30, 2024


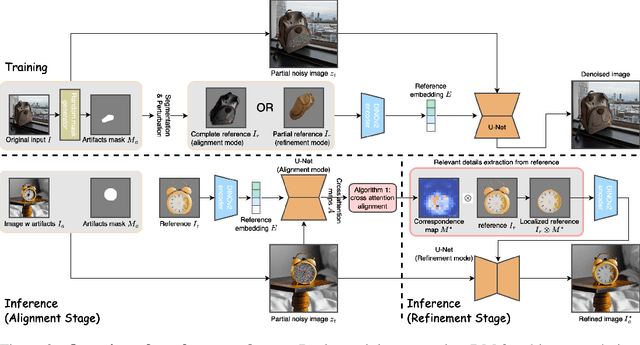
Personalized image generation has emerged from the recent advancements in generative models. However, these generated personalized images often suffer from localized artifacts such as incorrect logos, reducing fidelity and fine-grained identity details of the generated results. Furthermore, there is little prior work tackling this problem. To help improve these identity details in the personalized image generation, we introduce a new task: reference-guided artifacts refinement. We present Refine-by-Align, a first-of-its-kind model that employs a diffusion-based framework to address this challenge. Our model consists of two stages: Alignment Stage and Refinement Stage, which share weights of a unified neural network model. Given a generated image, a masked artifact region, and a reference image, the alignment stage identifies and extracts the corresponding regional features in the reference, which are then used by the refinement stage to fix the artifacts. Our model-agnostic pipeline requires no test-time tuning or optimization. It automatically enhances image fidelity and reference identity in the generated image, generalizing well to existing models on various tasks including but not limited to customization, generative compositing, view synthesis, and virtual try-on. Extensive experiments and comparisons demonstrate that our pipeline greatly pushes the boundary of fine details in the image synthesis models.
Kubrick: Multimodal Agent Collaborations for Synthetic Video Generation
Aug 19, 2024



Text-to-video generation has been dominated by end-to-end diffusion-based or autoregressive models. On one hand, those novel models provide plausible versatility, but they are criticized for physical correctness, shading and illumination, camera motion, and temporal consistency. On the other hand, film industry relies on manually-edited Computer-Generated Imagery (CGI) using 3D modeling software. Human-directed 3D synthetic videos and animations address the aforementioned shortcomings, but it is extremely tedious and requires tight collaboration between movie makers and 3D rendering experts. In this paper, we introduce an automatic synthetic video generation pipeline based on Vision Large Language Model (VLM) agent collaborations. Given a natural language description of a video, multiple VLM agents auto-direct various processes of the generation pipeline. They cooperate to create Blender scripts which render a video that best aligns with the given description. Based on film making inspiration and augmented with Blender-based movie making knowledge, the Director agent decomposes the input text-based video description into sub-processes. For each sub-process, the Programmer agent produces Python-based Blender scripts based on customized function composing and API calling. Then, the Reviewer agent, augmented with knowledge of video reviewing, character motion coordinates, and intermediate screenshots uses its compositional reasoning ability to provide feedback to the Programmer agent. The Programmer agent iteratively improves the scripts to yield the best overall video outcome. Our generated videos show better quality than commercial video generation models in 5 metrics on video quality and instruction-following performance. Moreover, our framework outperforms other approaches in a comprehensive user study on quality, consistency, and rationality.
COHO: Context-Sensitive City-Scale Hierarchical Urban Layout Generation
Jul 16, 2024The generation of large-scale urban layouts has garnered substantial interest across various disciplines. Prior methods have utilized procedural generation requiring manual rule coding or deep learning needing abundant data. However, prior approaches have not considered the context-sensitive nature of urban layout generation. Our approach addresses this gap by leveraging a canonical graph representation for the entire city, which facilitates scalability and captures the multi-layer semantics inherent in urban layouts. We introduce a novel graph-based masked autoencoder (GMAE) for city-scale urban layout generation. The method encodes attributed buildings, city blocks, communities and cities into a unified graph structure, enabling self-supervised masked training for graph autoencoder. Additionally, we employ scheduled iterative sampling for 2.5D layout generation, prioritizing the generation of important city blocks and buildings. Our approach achieves good realism, semantic consistency, and correctness across the heterogeneous urban styles in 330 US cities. Codes and datasets are released at https://github.com/Arking1995/COHO.
IMPRINT: Generative Object Compositing by Learning Identity-Preserving Representation
Mar 15, 2024



Generative object compositing emerges as a promising new avenue for compositional image editing. However, the requirement of object identity preservation poses a significant challenge, limiting practical usage of most existing methods. In response, this paper introduces IMPRINT, a novel diffusion-based generative model trained with a two-stage learning framework that decouples learning of identity preservation from that of compositing. The first stage is targeted for context-agnostic, identity-preserving pretraining of the object encoder, enabling the encoder to learn an embedding that is both view-invariant and conducive to enhanced detail preservation. The subsequent stage leverages this representation to learn seamless harmonization of the object composited to the background. In addition, IMPRINT incorporates a shape-guidance mechanism offering user-directed control over the compositing process. Extensive experiments demonstrate that IMPRINT significantly outperforms existing methods and various baselines on identity preservation and composition quality.
GlobalMapper: Arbitrary-Shaped Urban Layout Generation
Jul 19, 2023Modeling and designing urban building layouts is of significant interest in computer vision, computer graphics, and urban applications. A building layout consists of a set of buildings in city blocks defined by a network of roads. We observe that building layouts are discrete structures, consisting of multiple rows of buildings of various shapes, and are amenable to skeletonization for mapping arbitrary city block shapes to a canonical form. Hence, we propose a fully automatic approach to building layout generation using graph attention networks. Our method generates realistic urban layouts given arbitrary road networks, and enables conditional generation based on learned priors. Our results, including user study, demonstrate superior performance as compared to prior layout generation networks, support arbitrary city block and varying building shapes as demonstrated by generating layouts for 28 large cities.
ObjectStitch: Generative Object Compositing
Dec 05, 2022



Object compositing based on 2D images is a challenging problem since it typically involves multiple processing stages such as color harmonization, geometry correction and shadow generation to generate realistic results. Furthermore, annotating training data pairs for compositing requires substantial manual effort from professionals, and is hardly scalable. Thus, with the recent advances in generative models, in this work, we propose a self-supervised framework for object compositing by leveraging the power of conditional diffusion models. Our framework can hollistically address the object compositing task in a unified model, transforming the viewpoint, geometry, color and shadow of the generated object while requiring no manual labeling. To preserve the input object's characteristics, we introduce a content adaptor that helps to maintain categorical semantics and object appearance. A data augmentation method is further adopted to improve the fidelity of the generator. Our method outperforms relevant baselines in both realism and faithfulness of the synthesized result images in a user study on various real-world images.
Design and Deployment of Photo2Building: A Cloud-based Procedural Modeling Tool as a Service
Aug 04, 2020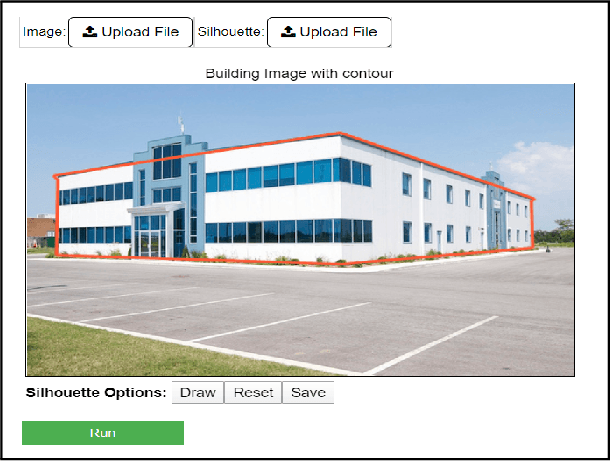
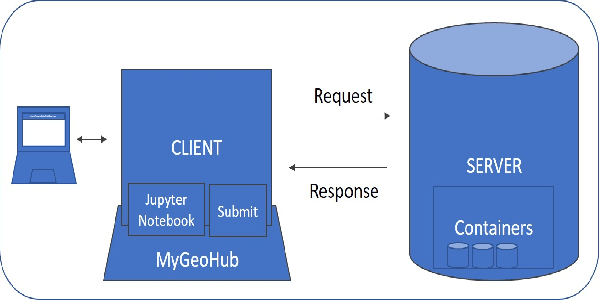
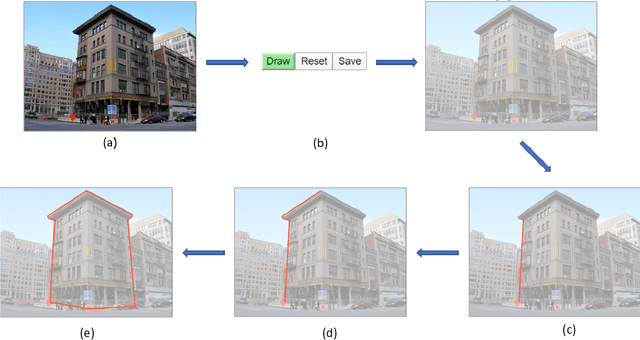
We present a Photo2Building tool to create a plausible 3D model of a building from only a single photograph. Our tool is based on a prior desktop version which, as described in this paper, is converted into a client-server model, with job queuing, web-page support, and support of concurrent usage. The reported cloud-based web-accessible tool can reconstruct a building in 40 seconds on average and costing only 0.60 USD with current pricing. This provides for an extremely scalable and possibly widespread tool for creating building models for use in urban design and planning applications. With the growing impact of rapid urbanization on weather and climate and resource availability, access to such a service is expected to help a wide variety of users such as city planners, urban meteorologists worldwide in the quest to improved prediction of urban weather and designing climate-resilient cities of the future.
* 7 pages, 7 figures, PEARC '20: Practice and Experience in Advanced Research Computing, July 26--30, 2020, Portland, OR, USA