 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Biased Nonnegative Block Term Tensor Decomposition Model for Dynamic QoS Prediction
May 06, 2026With the rapid development of cloud computing and Web services, Quality of Service (QoS) has become a key criterion for service selection and recommendation. Tensor latent feature analysis provides an effective way to model multidimensional QoS data, and most existing QoS prediction methods are mainly based on Canonical Polyadic (CP) decomposition or Tucker decomposition. However, constrained by their inherent structural properties, these methods cannot accurately capture the complex and dynamic dependencies in user-service interactions, which limits their prediction performance. To address this issue, this paper proposes a dynamic QoS prediction framework based on the Biased Nonnegative Block Term Tensor Decomposition Model, termed BNBT. Specifically, the proposed framework is developed from three aspects: (1) block term tensor decomposition is employed to enhance the representation capability of latent feature learning; (2) linear bias terms are incorporated to further improve prediction accuracy; and (3) a tensor-oriented single-element-dependent nonnegative multiplicative update algorithm, called SLF-NMUT, is designed for efficient parameter estimation. Extensive experiments on real-world QoS datasets demonstrate that the proposed BNBT framework consistently outperforms several state-of-the-art QoS prediction methods in terms of prediction accuracy.
Prototype-Based Test-Time Adaptation of Vision-Language Models
Apr 23, 2026Test-time adaptation (TTA) has emerged as a promising paradigm for vision-language models (VLMs) to bridge the distribution gap between pre-training and test data. Recent works have focused on backpropagation-free TTA methods that rely on cache-based designs, but these introduce two key limitations. First, inference latency increases as the cache grows with the number of classes, leading to inefficiencies in large-scale settings. Second, suboptimal performance occurs when the cache contains insufficient or incorrect samples. In this paper, we present Prototype-Based Test-Time Adaptation (PTA), an efficient and effective TTA paradigm that uses a set of class-specific knowledge prototypes to accumulate knowledge from test samples. Particularly, knowledge prototypes are adaptively weighted based on the zero-shot class confidence of each test sample, incorporating the sample's visual features into the corresponding class-specific prototype. It is worth highlighting that the knowledge from past test samples is integrated and utilized solely in the prototypes, eliminating the overhead of cache population and retrieval that hinders the efficiency of existing TTA methods. This endows PTA with extremely high efficiency while achieving state-of-the-art performance on 15 image recognition benchmarks and 4 robust point cloud analysis benchmarks. For example, PTA improves CLIP's accuracy from 65.64% to 69.38% on 10 cross-domain benchmarks, while retaining 92% of CLIP's inference speed on large-scale ImageNet-1K. In contrast, the cache-based TDA achieves a lower accuracy of 67.97% and operates at only 50% of CLIP's inference speed.
ID-Selection: Importance-Diversity Based Visual Token Selection for Efficient LVLM Inference
Apr 07, 2026Recent advances have explored visual token pruning to accelerate the inference of large vision-language models (LVLMs). However, existing methods often struggle to balance token importance and diversity: importance-based methods tend to retain redundant tokens, whereas diversity-based methods may overlook informative ones. This trade-off becomes especially problematic under high reduction ratios, where preserving only a small subset of visual tokens is critical. To address this issue, we propose ID-Selection, a simple yet effective token selection strategy for efficient LVLM inference. The key idea is to couple importance estimation with diversity-aware iterative selection: each token is first assigned an importance score, after which high-scoring tokens are selected one by one while the scores of similar tokens are progressively suppressed. In this way, ID-Selection preserves informative tokens while reducing redundancy in a unified selection process. Extensive experiments across 5 LVLM backbones and 16 main benchmarks demonstrate that ID-Selection consistently achieves superior performance and efficiency, especially under extreme pruning ratios. For example, on LLaVA-1.5-7B, ID-Selection prunes 97.2% of visual tokens, retaining only 16 tokens, while reducing inference FLOPs by over 97% and preserving 91.8% of the original performance, all without additional training.
Establishing Rigorous and Cost-effective Clinical Trials for Artificial Intelligence Models
Jul 11, 2024



A profound gap persists between artificial intelligence (AI) and clinical practice in medicine, primarily due to the lack of rigorous and cost-effective evaluation methodologies. State-of-the-art and state-of-the-practice AI model evaluations are limited to laboratory studies on medical datasets or direct clinical trials with no or solely patient-centered controls. Moreover, the crucial role of clinicians in collaborating with AI, pivotal for determining its impact on clinical practice, is often overlooked. For the first time, we emphasize the critical necessity for rigorous and cost-effective evaluation methodologies for AI models in clinical practice, featuring patient/clinician-centered (dual-centered) AI randomized controlled trials (DC-AI RCTs) and virtual clinician-based in-silico trials (VC-MedAI) as an effective proxy for DC-AI RCTs. Leveraging 7500 diagnosis records from two-phase inaugural DC-AI RCTs across 14 medical centers with 125 clinicians, our results demonstrate the necessity of DC-AI RCTs and the effectiveness of VC-MedAI. Notably, VC-MedAI performs comparably to human clinicians, replicating insights and conclusions from prospective DC-AI RCTs. We envision DC-AI RCTs and VC-MedAI as pivotal advancements, presenting innovative and transformative evaluation methodologies for AI models in clinical practice, offering a preclinical-like setting mirroring conventional medicine, and reshaping development paradigms in a cost-effective and fast-iterative manner. Chinese Clinical Trial Registration: ChiCTR2400086816.
OpenClinicalAI: An Open and Dynamic Model for Alzheimer's Disease Diagnosis
Jul 03, 2023



Although Alzheimer's disease (AD) cannot be reversed or cured, timely diagnosis can significantly reduce the burden of treatment and care. Current research on AD diagnosis models usually regards the diagnosis task as a typical classification task with two primary assumptions: 1) All target categories are known a priori; 2) The diagnostic strategy for each patient is consistent, that is, the number and type of model input data for each patient are the same. However, real-world clinical settings are open, with complexity and uncertainty in terms of both subjects and the resources of the medical institutions. This means that diagnostic models may encounter unseen disease categories and need to dynamically develop diagnostic strategies based on the subject's specific circumstances and available medical resources. Thus, the AD diagnosis task is tangled and coupled with the diagnosis strategy formulation. To promote the application of diagnostic systems in real-world clinical settings, we propose OpenClinicalAI for direct AD diagnosis in complex and uncertain clinical settings. This is the first powerful end-to-end model to dynamically formulate diagnostic strategies and provide diagnostic results based on the subject's conditions and available medical resources. OpenClinicalAI combines reciprocally coupled deep multiaction reinforcement learning (DMARL) for diagnostic strategy formulation and multicenter meta-learning (MCML) for open-set recognition. The experimental results show that OpenClinicalAI achieves better performance and fewer clinical examinations than the state-of-the-art model. Our method provides an opportunity to embed the AD diagnostic system into the current health care system to cooperate with clinicians to improve current health care.
OpenAPMax: Abnormal Patterns-based Model for Real-World Alzheimer's Disease Diagnosis
Jul 03, 2023



Alzheimer's disease (AD) cannot be reversed, but early diagnosis will significantly benefit patients' medical treatment and care. In recent works, AD diagnosis has the primary assumption that all categories are known a prior -- a closed-set classification problem, which contrasts with the open-set recognition problem. This assumption hinders the application of the model in natural clinical settings. Although many open-set recognition technologies have been proposed in other fields, they are challenging to use for AD diagnosis directly since 1) AD is a degenerative disease of the nervous system with similar symptoms at each stage, and it is difficult to distinguish from its pre-state, and 2) diversified strategies for AD diagnosis are challenging to model uniformly. In this work, inspired by the concerns of clinicians during diagnosis, we propose an open-set recognition model, OpenAPMax, based on the anomaly pattern to address AD diagnosis in real-world settings. OpenAPMax first obtains the abnormal pattern of each patient relative to each known category through statistics or a literature search, clusters the patients' abnormal pattern, and finally, uses extreme value theory (EVT) to model the distance between each patient's abnormal pattern and the center of their category and modify the classification probability. We evaluate the performance of the proposed method with recent open-set recognition, where we obtain state-of-the-art results.
Addressing Class Variable Imbalance in Federated Semi-supervised Learning
Mar 21, 2023



Federated Semi-supervised Learning (FSSL) combines techniques from both fields of federated and semi-supervised learning to improve the accuracy and performance of models in a distributed environment by using a small fraction of labeled data and a large amount of unlabeled data. Without the need to centralize all data in one place for training, it collect updates of model training after devices train models at local, and thus can protect the privacy of user data. However, during the federal training process, some of the devices fail to collect enough data for local training, while new devices will be included to the group training. This leads to an unbalanced global data distribution and thus affect the performance of the global model training. Most of the current research is focusing on class imbalance with a fixed number of classes, while little attention is paid to data imbalance with a variable number of classes. Therefore, in this paper, we propose Federated Semi-supervised Learning for Class Variable Imbalance (FCVI) to solve class variable imbalance. The class-variable learning algorithm is used to mitigate the data imbalance due to changes of the number of classes. Our scheme is proved to be significantly better than baseline methods, while maintaining client privacy.
An Efficient Ratio Detector for Ambient Backscatter Communication
Oct 18, 2022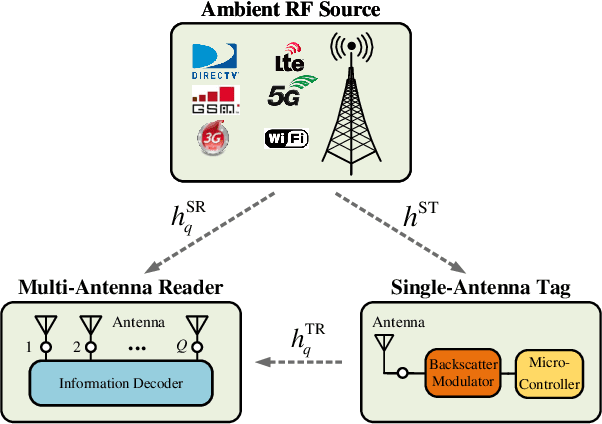
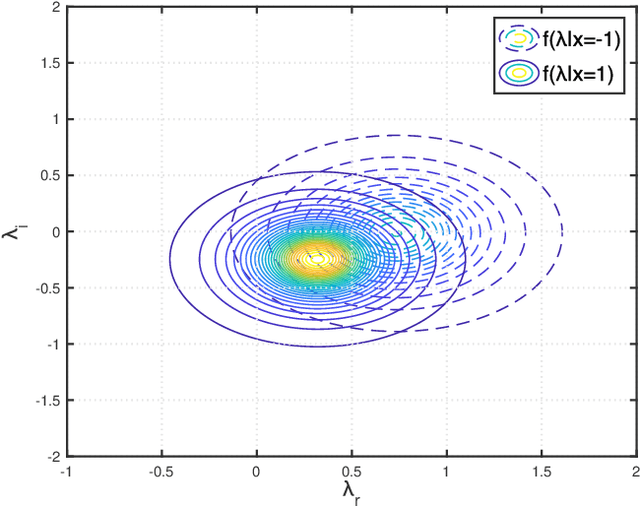
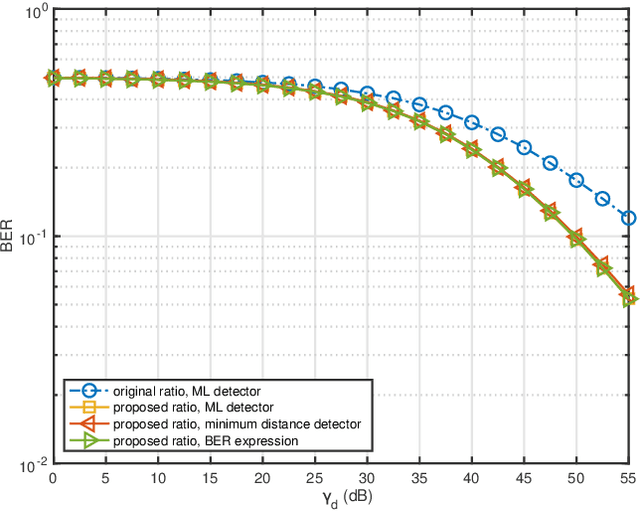
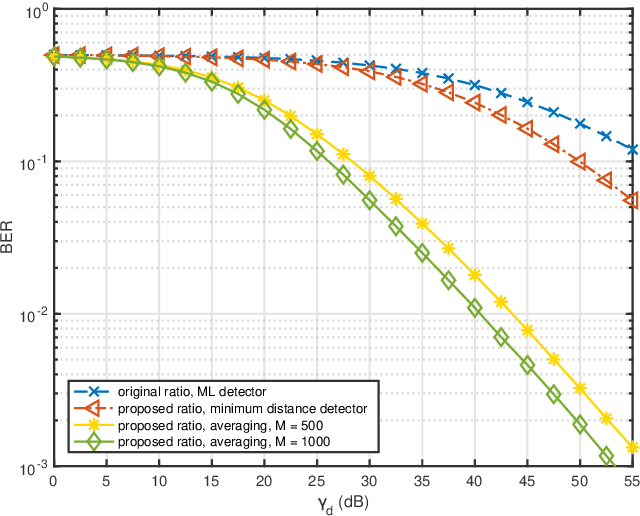
Ambient backscatter communication (AmBC) leverages the existing ambient radio frequency (RF) environment to implement communication with battery-free devices. One critical challenge of AmBC systems is signal recovery because the transmitted information bits are embedded in the ambient RF signals and these are unknown and uncontrollable. To address this problem, most existing approaches use averaging-based energy detectors and consequently the data rate is low and there is an error floor. Here we propose a new detection strategy based on the ratio between signals received from a multiple-antenna Reader. The advantage of using the ratio is that ambient RF signals are removed directly from the embedded signals without averaging and hence it can increase data rates and avoid the error floor. Different from original ratio detectors that use the magnitude ratio of the signals between two Reader antennas, in our proposed approach, we utilize the complex ratio so that phase information is preserved and propose an accurate linear channel model approximation. This allows the application of existing linear detection techniques from which we can obtain a minimum distance detector and closed-form expressions for bit error rate (BER). In addition, averaging, coding and interleaving can also be included to further enhance the BER. The results are also general, allowing any number of Reader antennas to be utilized in the approach. Numerical results demonstrate that the proposed approach performs better than approaches based on energy detection and original ratio detectors.