 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEALing Entropy Collapse: Enhancing Exploration in Few-Shot RLVR via Hybrid-Domain Entropy Dynamics Alignment
Apr 20, 2026Reinforcement Learning with Verifiable Reward (RLVR) has proven effective for training reasoning-oriented large language models, but existing methods largely assume high-resource settings with abundant training data. In low-resource scenarios, RLVR is prone to more severe entropy collapse, which substantially limits exploration and degrades reasoning performance. To address this issue, we propose Hybrid-domain Entropy dynamics ALignment (HEAL), a framework tailored for few-shot RLVR. HEAL first selectively incorporates high-value general-domain data to promote more diverse exploration. Then, we introduce Entropy Dynamics Alignment (EDA), a reward mechanism that aligns trajectory-level entropy dynamics between the target and general domains, capturing both entropy magnitude and fine-grained variation. Through this alignment, EDA not only further mitigates entropy collapse but also encourages the policy to acquire more diverse exploration behaviors from the general domain. Experiments across multiple domains show that HEAL consistently improves few-shot RLVR performance. Notably, using only 32 target-domain samples, HEAL matches or even surpasses full-shot RLVR trained with 1K target-domain samples.
RASR: Retrieval-Augmented Semantic Reasoning for Fake News Video Detection
Apr 08, 2026Multimodal fake news video detection is a crucial research direction for maintaining the credibility of online information. Existing studies primarily verify content authenticity by constructing multimodal feature fusion representations or utilizing pre-trained language models to analyze video-text consistency. However, these methods still face the following limitations: (1) lacking cross-instance global semantic correlations, making it difficult to effectively utilize historical associative evidence to verify the current video; (2) semantic discrepancies across domains hinder the transfer of general knowledge, lacking the guidance of domain-specific expert knowledge. To this end, we propose a novel Retrieval-Augmented Semantic Reasoning (RASR) framework. First, a Cross-instance Semantic Parser and Retriever (CSPR) deconstructs the video into high-level semantic primitives and retrieves relevant associative evidence from a dynamic memory bank. Subsequently, a Domain-Guided Multimodal Reasoning (DGMP) module incorporates domain priors to drive an expert multimodal large language model in generating domain-aware, in-depth analysis reports. Finally, a Multi-View Feature Decoupling and Fusion (MVDFF) module integrates multi-dimensional features through an adaptive gating mechanism to achieve robust authenticity determination. Extensive experiments on the FakeSV and FakeTT datasets demonstrate that RASR significantly outperforms state-of-the-art baselines, achieves superior cross-domain generalization, and improves the overall detection accuracy by up to 0.93%.
Dogfight Search: A Swarm-Based Optimization Algorithm for Complex Engineering Optimization and Mountainous Terrain Path Planning
Mar 30, 2026Dogfight is a tactical behavior of cooperation between fighters. Inspired by this, this paper proposes a novel metaphor-free metaheuristic algorithm called Dogfight Search (DoS). Unlike traditional algorithms, DoS draws algorithmic framework from the inspiration, but its search mechanism is constructed based on the displacement integration equations in kinematics. Through experimental validation on CEC2017 and CEC2022 benchmark test functions, 10 real-world constrained optimization problems and mountainous terrain path planning tasks, DoS significantly outperforms 7 advanced competitors in overall performance and ranks first in the Friedman ranking. Furthermore, this paper compares the performance of DoS with 3 SOTA algorithms on the CEC2017 and CEC2022 benchmark test functions. The results show that DoS continues to maintain its lead, demonstrating strong competitiveness. The source code of DoS is available at https://ww2.mathworks.cn/matlabcentral/fileexchange/183519-dogfight-search.
STMI: Segmentation-Guided Token Modulation with Cross-Modal Hypergraph Interaction for Multi-Modal Object Re-Identification
Feb 28, 2026Multi-modal object Re-Identification (ReID) aims to exploit complementary information from different modalities to retrieve specific objects. However, existing methods often rely on hard token filtering or simple fusion strategies, which can lead to the loss of discriminative cues and increased background interference. To address these challenges, we propose STMI, a novel multi-modal learning framework consisting of three key components: (1) Segmentation-Guided Feature Modulation (SFM) module leverages SAM-generated masks to enhance foreground representations and suppress background noise through learnable attention modulation; (2) Semantic Token Reallocation (STR) module employs learnable query tokens and an adaptive reallocation mechanism to extract compact and informative representations without discarding any tokens; (3) Cross-Modal Hypergraph Interaction (CHI) module constructs a unified hypergraph across modalities to capture high-order semantic relationships. Extensive experiments on public benchmarks (i.e., RGBNT201, RGBNT100, and MSVR310) demonstrate the effectiveness and robustness of our proposed STMI framework in multi-modal ReID scenarios.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025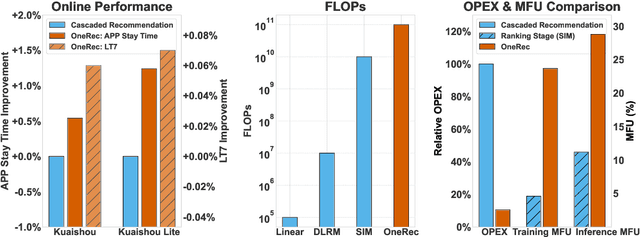

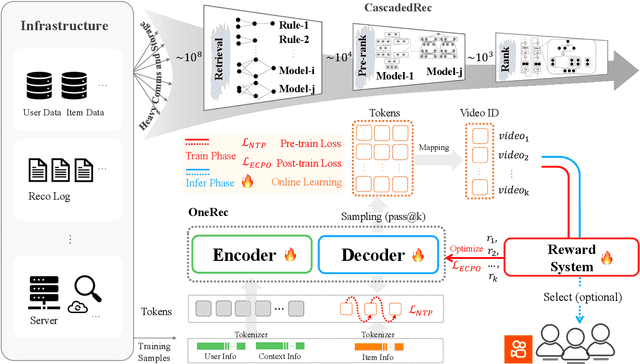
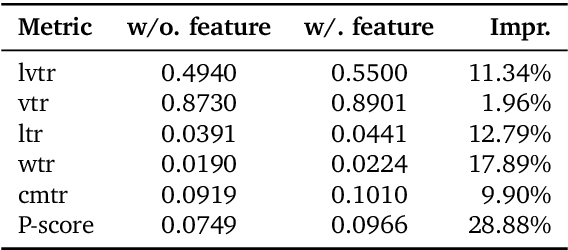
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
C-Mamba: Channel Correlation Enhanced State Space Models for Multivariate Time Series Forecasting
Jun 08, 2024



In recent years, significant progress has been made in multivariate time series forecasting using Linear-based, Transformer-based, and Convolution-based models. However, these approaches face notable limitations: linear forecasters struggle with representation capacities, attention mechanisms suffer from quadratic complexity, and convolutional models have a restricted receptive field. These constraints impede their effectiveness in modeling complex time series, particularly those with numerous variables. Additionally, many models adopt the Channel-Independent (CI) strategy, treating multivariate time series as uncorrelated univariate series while ignoring their correlations. For models considering inter-channel relationships, whether through the self-attention mechanism, linear combination, or convolution, they all incur high computational costs and focus solely on weighted summation relationships, neglecting potential proportional relationships between channels. In this work, we address these issues by leveraging the newly introduced state space model and propose \textbf{C-Mamba}, a novel approach that captures cross-channel dependencies while maintaining linear complexity without losing the global receptive field. Our model consists of two key components: (i) channel mixup, where two channels are mixed to enhance the training sets; (ii) channel attention enhanced patch-wise Mamba encoder that leverages the ability of the state space models to capture cross-time dependencies and models correlations between channels by mining their weight relationships. Our model achieves state-of-the-art performance on seven real-world time series datasets. Moreover, the proposed mixup and attention strategy exhibits strong generalizability across other frameworks.
Frequency Enhanced Pre-training for Cross-city Few-shot Traffic Forecasting
Jun 06, 2024



The field of Intelligent Transportation Systems (ITS) relies on accurate traffic forecasting to enable various downstream applications. However, developing cities often face challenges in collecting sufficient training traffic data due to limited resources and outdated infrastructure. Recognizing this obstacle, the concept of cross-city few-shot forecasting has emerged as a viable approach. While previous cross-city few-shot forecasting methods ignore the frequency similarity between cities, we have made an observation that the traffic data is more similar in the frequency domain between cities. Based on this fact, we propose a \textbf{F}requency \textbf{E}nhanced \textbf{P}re-training Framework for \textbf{Cross}-city Few-shot Forecasting (\textbf{FEPCross}). FEPCross has a pre-training stage and a fine-tuning stage. In the pre-training stage, we propose a novel Cross-Domain Spatial-Temporal Encoder that incorporates the information of the time and frequency domain and trains it with self-supervised tasks encompassing reconstruction and contrastive objectives. In the fine-tuning stage, we design modules to enrich training samples and maintain a momentum-updated graph structure, thereby mitigating the risk of overfitting to the few-shot training data. Empirical evaluations performed on real-world traffic datasets validate the exceptional efficacy of FEPCross, outperforming existing approaches of diverse categories and demonstrating characteristics that foster the progress of cross-city few-shot forecasting.
MagiNet: Mask-Aware Graph Imputation Network for Incomplete Traffic Data
Jun 05, 2024



Due to detector malfunctions and communication failures, missing data is ubiquitous during the collection of traffic data. Therefore, it is of vital importance to impute the missing values to facilitate data analysis and decision-making for Intelligent Transportation System (ITS). However, existing imputation methods generally perform zero pre-filling techniques to initialize missing values, introducing inevitable noises. Moreover, we observe prevalent over-smoothing interpolations, falling short in revealing the intrinsic spatio-temporal correlations of incomplete traffic data. To this end, we propose Mask-Aware Graph imputation Network: MagiNet. Our method designs an adaptive mask spatio-temporal encoder to learn the latent representations of incomplete data, eliminating the reliance on pre-filling missing values. Furthermore, we devise a spatio-temporal decoder that stacks multiple blocks to capture the inherent spatial and temporal dependencies within incomplete traffic data, alleviating over-smoothing imputation. Extensive experiments demonstrate that our method outperforms state-of-the-art imputation methods on five real-world traffic datasets, yielding an average improvement of 4.31% in RMSE and 3.72% in MAPE.