 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Metacognition via Cognitive Pairwise Training
May 30, 2026Reinforcement learning with verifiable rewards (RLVR) has become central to LLM reasoning, but its outcome-level rewards can make models more willing to give confident answers when evidence or reasoning is unreliable. Existing SFT or RL methods mainly teach LLMs to refuse or express uncertainty at the response level, which can overfit abstention behavior rather than improve reasoning reliability. To address this limitation, we propose Cognitive Pairwise Training (CPT), a cognitive mid-training alignment stage that turns pairwise comparisons over reasoning traces into a reusable alignment signal. By learning to distinguish trustworthy from flawed reasoning, CPT encourages the model to internalize a reasoning-quality discrimination boundary rather than memorize surface refusal patterns. Across five model scales and three model families, CPT improves the reasoning--metacognition trade-off. At 14B, CPT+RL outperforms the standard SFT+RL pipeline by +2.2 math-average points and +5.2 abstention-F1 points. Further analyses show that CPT improves trace quality and exhibits strong robustness and scalability across evaluation and training settings. Code and models are released at https://github.com/Tsinghua-dhy/CPT.
HEALing Entropy Collapse: Enhancing Exploration in Few-Shot RLVR via Hybrid-Domain Entropy Dynamics Alignment
Apr 20, 2026Reinforcement Learning with Verifiable Reward (RLVR) has proven effective for training reasoning-oriented large language models, but existing methods largely assume high-resource settings with abundant training data. In low-resource scenarios, RLVR is prone to more severe entropy collapse, which substantially limits exploration and degrades reasoning performance. To address this issue, we propose Hybrid-domain Entropy dynamics ALignment (HEAL), a framework tailored for few-shot RLVR. HEAL first selectively incorporates high-value general-domain data to promote more diverse exploration. Then, we introduce Entropy Dynamics Alignment (EDA), a reward mechanism that aligns trajectory-level entropy dynamics between the target and general domains, capturing both entropy magnitude and fine-grained variation. Through this alignment, EDA not only further mitigates entropy collapse but also encourages the policy to acquire more diverse exploration behaviors from the general domain. Experiments across multiple domains show that HEAL consistently improves few-shot RLVR performance. Notably, using only 32 target-domain samples, HEAL matches or even surpasses full-shot RLVR trained with 1K target-domain samples.
Countering the Over-Reliance Trap: Mitigating Object Hallucination for LVLMs via a Self-Validation Framework
Jan 30, 2026Despite progress in Large Vision Language Models (LVLMs), object hallucination remains a critical issue in image captioning task, where models generate descriptions of non-existent objects, compromising their reliability. Previous work attributes this to LVLMs' over-reliance on language priors and attempts to mitigate it through logits calibration. However, they still lack a thorough analysis of the over-reliance. To gain a deeper understanding of over-reliance, we conduct a series of preliminary experiments, indicating that as the generation length increases, LVLMs' over-reliance on language priors leads to inflated probability of hallucinated object tokens, consequently exacerbating object hallucination. To circumvent this issue, we propose Language-Prior-Free Verification to enable LVLMs to faithfully verify the confidence of object existence. Based on this, we propose a novel training-free Self-Validation Framework to counter the over-reliance trap. It first validates objects' existence in sampled candidate captions and further mitigates object hallucination via caption selection or aggregation. Experiment results demonstrate that our framework mitigates object hallucination significantly in image captioning task (e.g., 65.6% improvement on CHAIRI metric with LLaVA-v1.5-7B), surpassing the previous SOTA methods. This result highlights a novel path towards mitigating hallucination by unlocking the inherent potential within LVLMs themselves.
Orchestrating Tokens and Sequences: Dynamic Hybrid Policy Optimization for RLVR
Jan 09, 2026Reinforcement Learning with Verifiable Rewards (RLVR) offers a promising framework for optimizing large language models in reasoning tasks. However, existing RLVR algorithms focus on different granularities, and each has complementary strengths and limitations. Group Relative Policy Optimization (GRPO) updates the policy with token-level importance ratios, which preserves fine-grained credit assignment but often suffers from high variance and instability. In contrast, Group Sequence Policy Optimization (GSPO) applies single sequence-level importance ratios across all tokens in a response that better matches sequence-level rewards, but sacrifices token-wise credit assignment. In this paper, we propose Dynamic Hybrid Policy Optimization (DHPO) to bridge GRPO and GSPO within a single clipped surrogate objective. DHPO combines token-level and sequence-level importance ratios using weighting mechanisms. We explore two variants of the mixing mechanism, including an averaged mixing and an entropy-guided mixing. To further stabilize training, we employ a branch-specific clipping strategy that constrains token-level and sequence-level ratios within separate trust regions before mixing, preventing outliers in either branch from dominating the update. Across seven challenging mathematical reasoning benchmarks, experiments on both dense and MoE models from the Qwen3 series show that DHPO consistently outperforms GRPO and GSPO. We will release our code upon acceptance of this paper.
Can LLMs Track Their Output Length? A Dynamic Feedback Mechanism for Precise Length Regulation
Jan 07, 2026Precisely controlling the length of generated text is a common requirement in real-world applications. However, despite significant advancements in following human instructions, Large Language Models (LLMs) still struggle with this task. In this work, we demonstrate that LLMs often fail to accurately measure their response lengths, leading to poor adherence to length constraints. To address this issue, we propose a novel length regulation approach that incorporates dynamic length feedback during generation, enabling adaptive adjustments to meet target lengths. Experiments on summarization and biography tasks show our training-free approach significantly improves precision in achieving target token, word, or sentence counts without compromising quality. Additionally, we demonstrate that further supervised fine-tuning allows our method to generalize effectively to broader text-generation tasks.
Don't Miss the Forest for the Trees: In-Depth Confidence Estimation for LLMs via Reasoning over the Answer Space
Nov 18, 2025Knowing the reliability of a model's response is essential in application. With the strong generation capabilities of LLMs, research has focused on generating verbalized confidence. This is further enhanced by combining chain-of-thought reasoning, which provides logical and transparent estimation. However, how reasoning strategies affect the estimated confidence is still under-explored. In this work, we demonstrate that predicting a verbalized probability distribution can effectively encourage in-depth reasoning for confidence estimation. Intuitively, it requires an LLM to consider all candidates within the answer space instead of basing on a single guess, and to carefully assign confidence scores to meet the requirements of a distribution. This method shows an advantage across different models and various tasks, regardless of whether the answer space is known. Its advantage is maintained even after reinforcement learning, and further analysis shows its reasoning patterns are aligned with human expectations.
A Multi-Agent Framework with Automated Decision Rule Optimization for Cross-Domain Misinformation Detection
Mar 30, 2025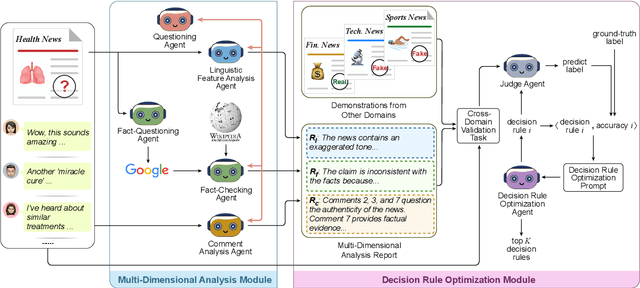
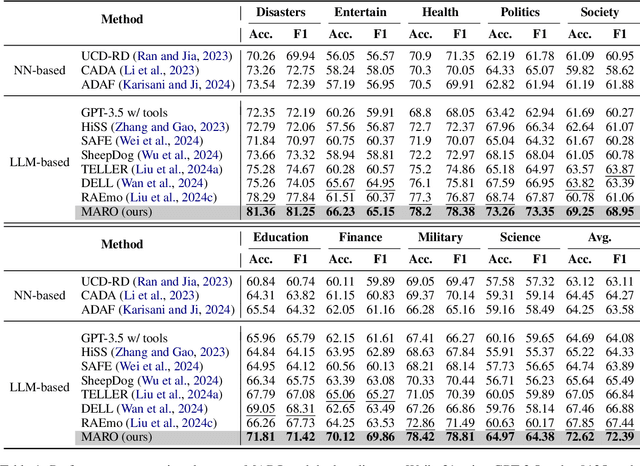
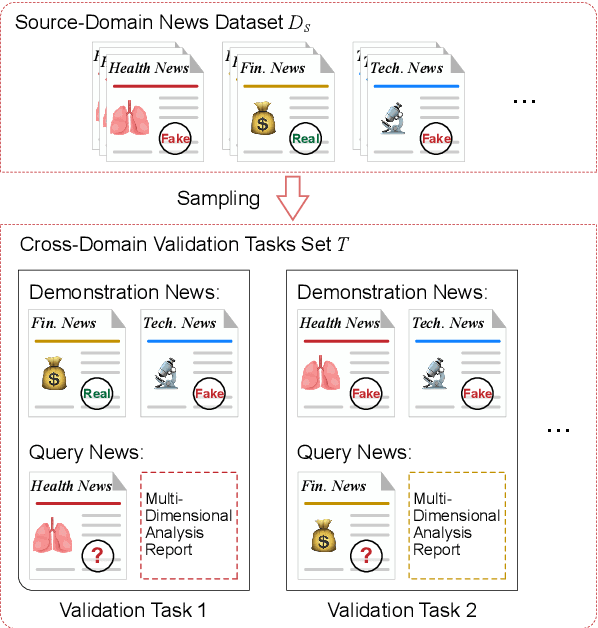
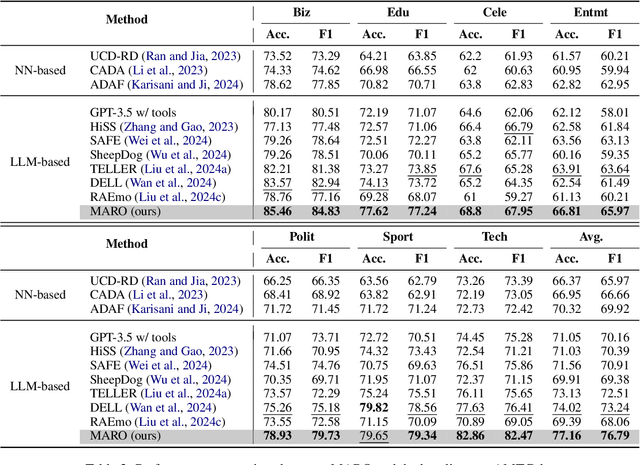
Misinformation spans various domains, but detection methods trained on specific domains often perform poorly when applied to others. With the rapid development of Large Language Models (LLMs), researchers have begun to utilize LLMs for cross-domain misinformation detection. However, existing LLM-based methods often fail to adequately analyze news in the target domain, limiting their detection capabilities. More importantly, these methods typically rely on manually designed decision rules, which are limited by domain knowledge and expert experience, thus limiting the generalizability of decision rules to different domains. To address these issues, we propose a MultiAgent Framework for cross-domain misinformation detection with Automated Decision Rule Optimization (MARO). Under this framework, we first employs multiple expert agents to analyze target-domain news. Subsequently, we introduce a question-reflection mechanism that guides expert agents to facilitate higherquality analysis. Furthermore, we propose a decision rule optimization approach based on carefully-designed cross-domain validation tasks to iteratively enhance the effectiveness of decision rules in different domains. Experimental results and in-depth analysis on commonlyused datasets demonstrate that MARO achieves significant improvements over existing methods.
Investigating Inference-time Scaling for Chain of Multi-modal Thought: A Preliminary Study
Feb 17, 2025



Recently, inference-time scaling of chain-of-thought (CoT) has been demonstrated as a promising approach for addressing multi-modal reasoning tasks. While existing studies have predominantly centered on text-based thinking, the integration of both visual and textual modalities within the reasoning process remains unexplored. In this study, we pioneer the exploration of inference-time scaling with multi-modal thought, aiming to bridge this gap. To provide a comprehensive analysis, we systematically investigate popular sampling-based and tree search-based inference-time scaling methods on 10 challenging tasks spanning various domains. Besides, we uniformly adopt a consistency-enhanced verifier to ensure effective guidance for both methods across different thought paradigms. Results show that multi-modal thought promotes better performance against conventional text-only thought, and blending the two types of thought fosters more diverse thinking. Despite these advantages, multi-modal thoughts necessitate higher token consumption for processing richer visual inputs, which raises concerns in practical applications. We hope that our findings on the merits and drawbacks of this research line will inspire future works in the field.
A Dual-Perspective Metaphor Detection Framework Using Large Language Models
Dec 23, 2024



Metaphor detection, a critical task in natural language processing, involves identifying whether a particular word in a sentence is used metaphorically. Traditional approaches often rely on supervised learning models that implicitly encode semantic relationships based on metaphor theories. However, these methods often suffer from a lack of transparency in their decision-making processes, which undermines the reliability of their predictions. Recent research indicates that LLMs (large language models) exhibit significant potential in metaphor detection. Nevertheless, their reasoning capabilities are constrained by predefined knowledge graphs. To overcome these limitations, we propose DMD, a novel dual-perspective framework that harnesses both implicit and explicit applications of metaphor theories to guide LLMs in metaphor detection and adopts a self-judgment mechanism to validate the responses from the aforementioned forms of guidance. In comparison to previous methods, our framework offers more transparent reasoning processes and delivers more reliable predictions. Experimental results prove the effectiveness of DMD, demonstrating state-of-the-art performance across widely-used datasets.
Not All Languages are Equal: Insights into Multilingual Retrieval-Augmented Generation
Oct 29, 2024



RALMs (Retrieval-Augmented Language Models) broaden their knowledge scope by incorporating external textual resources. However, the multilingual nature of global knowledge necessitates RALMs to handle diverse languages, a topic that has received limited research focus. In this work, we propose \textit{Futurepedia}, a carefully crafted benchmark containing parallel texts across eight representative languages. We evaluate six multilingual RALMs using our benchmark to explore the challenges of multilingual RALMs. Experimental results reveal linguistic inequalities: 1) high-resource languages stand out in Monolingual Knowledge Extraction; 2) Indo-European languages lead RALMs to provide answers directly from documents, alleviating the challenge of expressing answers across languages; 3) English benefits from RALMs' selection bias and speaks louder in multilingual knowledge selection. Based on these findings, we offer advice for improving multilingual Retrieval Augmented Generation. For monolingual knowledge extraction, careful attention must be paid to cascading errors from translating low-resource languages into high-resource ones. In cross-lingual knowledge transfer, encouraging RALMs to provide answers within documents in different languages can improve transfer performance. For multilingual knowledge selection, incorporating more non-English documents and repositioning English documents can help mitigate RALMs' selection bias. Through comprehensive experiments, we underscore the complexities inherent in multilingual RALMs and offer valuable insights for future research.