 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompass: Navigating Global Marine Lead Data Integration through Expert-Guided LLM Agent
May 28, 2026Marine lead (Pb) and its isotopes are critical tracers for ocean circulation and anthropogenic pollution, yet in-situ observations remain costly and sparse. While vast historical records exist, they lie buried within the unstructured content of academic papers, creating "data silos" inaccessible to comprehensive analysis. Manual extraction is unscalable, while general-purpose Large Language Models (LLMs) lack the necessary domain-specific knowledge, leading to hallucinations and scientifically invalid outputs. To address this, we introduce an expert-guided adaptation approach that enables LLMs to perform rigorous scientific data extraction without fine-tuning. We operationalize this approach through Compass, an LLM agent framework enhanced by a Knowledge Tree co-designed with marine scientists, which decomposes complex tasks into verifiable steps, guiding the agent's reasoning to ensure scientific validity. Deploying Compass across a corpus of over 230,000 relevant open-access papers, we successfully extract 3,751 previously unincorporated Pb records. This effort establishes the largest integrated marine Pb database to date. Beyond standard metrics, Compass demonstrates superior reliability through multi-layered validation, achieving 92% accuracy as confirmed through expert manual verification. The newly integrated data expand coverage in previously under-sampled regions such as the East China Sea and the Southern Ocean, providing an enriched data foundation for future scientific discoveries. We release an interactive visualization platform to facilitate open scientific access. Our work demonstrates that expert-guided agents can effectively bridge the gap between general-purpose LLMs and high-stakes scientific domains, enabling scalable data discovery in geosciences.
Rethinking Efficient Graph Coarsening via a Non-Selfishness Principle
May 13, 2026Graph coarsening is a graph dimensionality reduction technique that aims to construct a smaller and more tractable graph while preserving the essential structural and semantic properties of the original graph. However, most existing methods rely on pair-wise similarity matching, where each node independently searches for its best partner based on global information. This selfishness matching paradigm incurs substantial computational and memory overhead. To address this problem, we shift to a non-selfishness principle that prioritizes the collective interference of neighborhood in coarsening, and propose an efficient method named NOPE, which achieves linear memory consumption and near-linear computational complexity in the number of nodes. Furthermore, we derive a faster variant NOPE*, which reduces O(δ\dot d) interference evaluation to O(d) based on the local isotropy assumption, and consequently alleviates the computational bottleneck for high-degree nodes. Experimental results show that NOPE* achieves 1.8-10\times speedup over NOPE and surpass almost all baselines with 1-3 orders of magnitude acceleration. Meanwhile, learning on coarsened graphs yields comparable performance to original graphs, and can even show superior performance over LLM-based graph reasoning owing to compact graph information. The code can be available at https://github.com/dazonglian/NOPE-main.
SLASH the Sink: Sharpening Structural Attention Inside LLMs
May 11, 2026Large Language Models (LLMs) show remarkable semantic understanding but often struggle with structural understanding when processing graph topologies in a serialized format. Existing solutions rely on training external graph-based adapters or fine-tuning, which incur high costs and lost generalizability. In this work, we investigate the internal mechanisms of LLMs and present a critical finding: LLMs spontaneously reconstruct the graph's topology internally, evidenced by a distinct "sawtooth" pattern in their attention maps that structurally aligns with the "token-level adjacency matrix". However, this intrinsic structural understanding is diluted by the attention sink. We theoretically formalize this dilution as a representation bottleneck, stemming from a fundamental conflict: the model's anisotropic bias, essential for language tasks, suppresses the topology-aware local aggregation required for graph reasoning. To address this, we propose a training-free solution, named StructuraL Attention SHarpening (Slash), which amplifies this internal structural understanding via a plug-and-play attention redistribution. Experiments on pure graph tasks and molecular prediction validate Slash delivers significant and consistent performance gains across diverse LLMs.
Inductive Reasoning for Temporal Knowledge Graphs with Emerging Entities
Apr 11, 2026Reasoning on Temporal Knowledge Graphs (TKGs) is essential for predicting future events and time-aware facts. While existing methods are effective at capturing relational dynamics, their performance is limited by a closed-world assumption, which fails to account for emerging entities not present in the training. Notably, these entities continuously join the network without historical interactions. Empirical study reveals that emerging entities are widespread in TKGs, comprising roughly 25\% of all entities. The absence of historical interactions of these entities leads to significant performance degradation in reasoning tasks. Whereas, we observe that entities with semantic similarities often exhibit comparable interaction histories, suggesting the presence of transferable temporal patterns. Inspired by this insight, we propose TransFIR (Transferable Inductive Reasoning), a novel framework that leverages historical interaction sequences from semantically similar known entities to support inductive reasoning. Specifically, we propose a codebook-based classifier that categorizes emerging entities into latent semantic clusters, allowing them to adopt reasoning patterns from similar entities. Experimental results demonstrate that TransFIR outperforms all baselines in reasoning on emerging entities, achieving an average improvement of 28.6% in Mean Reciprocal Rank (MRR) across multiple datasets. The implementations are available at https://github.com/zhaodazhuang2333/TransFIR.
<SOG_k>: One LLM Token for Explicit Graph Structural Understanding
Feb 02, 2026Large language models show great potential in unstructured data understanding, but still face significant challenges with graphs due to their structural hallucination. Existing approaches mainly either verbalize graphs into natural language, which leads to excessive token consumption and scattered attention, or transform graphs into trainable continuous embeddings (i.e., soft prompt), but exhibit severe misalignment with original text tokens. To solve this problem, we propose to incorporate one special token <SOG_k> to fully represent the Structure Of Graph within a unified token space, facilitating explicit topology input and structural information sharing. Specifically, we propose a topology-aware structural tokenizer that maps each graph topology into a highly selective single token. Afterwards, we construct a set of hybrid structure Question-Answering corpora to align new structural tokens with existing text tokens. With this approach, <SOG_k> empowers LLMs to understand, generate, and reason in a concise and accurate manner. Extensive experiments on five graph-level benchmarks demonstrate the superiority of our method, achieving a performance improvement of 9.9% to 41.4% compared to the baselines while exhibiting interpretability and consistency. Furthermore, our method provides a flexible extension to node-level tasks, enabling both global and local structural understanding. The codebase is publicly available at https://github.com/Jingyao-Wu/SOG.
Improving LLM Reasoning with Homophily-aware Structural and Semantic Text-Attributed Graph Compression
Jan 13, 2026Large language models (LLMs) have demonstrated promising capabilities in Text-Attributed Graph (TAG) understanding. Recent studies typically focus on verbalizing the graph structures via handcrafted prompts, feeding the target node and its neighborhood context into LLMs. However, constrained by the context window, existing methods mainly resort to random sampling, often implemented via dropping node/edge randomly, which inevitably introduces noise and cause reasoning instability. We argue that graphs inherently contain rich structural and semantic information, and that their effective exploitation can unlock potential gains in LLMs reasoning performance. To this end, we propose Homophily-aware Structural and Semantic Compression for LLMs (HS2C), a framework centered on exploiting graph homophily. Structurally, guided by the principle of Structural Entropy minimization, we perform a global hierarchical partition that decodes the graph's essential topology. This partition identifies naturally cohesive, homophilic communities, while discarding stochastic connectivity noise. Semantically, we deliver the detected structural homophily to the LLM, empowering it to perform differentiated semantic aggregation based on predefined community type. This process compresses redundant background contexts into concise community-level consensus, selectively preserving semantically homophilic information aligned with the target nodes. Extensive experiments on 10 node-level benchmarks across LLMs of varying sizes and families demonstrate that, by feeding LLMs with structurally and semantically compressed inputs, HS2C simultaneously enhances the compression rate and downstream inference accuracy, validating its superiority and scalability. Extensions to 7 diverse graph-level benchmarks further consolidate HS2C's task generalizability.
FedBook: A Unified Federated Graph Foundation Codebook with Intra-domain and Inter-domain Knowledge Modeling
Oct 09, 2025Foundation models have shown remarkable cross-domain generalization in language and vision, inspiring the development of graph foundation models (GFMs). However, existing GFMs typically assume centralized access to multi-domain graphs, which is often infeasible due to privacy and institutional constraints. Federated Graph Foundation Models (FedGFMs) address this limitation, but their effectiveness fundamentally hinges on constructing a robust global codebook that achieves intra-domain coherence by consolidating mutually reinforcing semantics within each domain, while also maintaining inter-domain diversity by retaining heterogeneous knowledge across domains. To this end, we propose FedBook, a unified federated graph foundation codebook that systematically aggregates clients' local codebooks during server-side federated pre-training. FedBook follows a two-phase process: (1) Intra-domain Collaboration, where low-frequency tokens are refined by referencing more semantically reliable high-frequency tokens across clients to enhance domain-specific coherence; and (2) Inter-domain Integration, where client contributions are weighted by the semantic distinctiveness of their codebooks during the aggregation of the global GFM, thereby preserving cross-domain diversity. Extensive experiments on 8 benchmarks across multiple domains and tasks demonstrate that FedBook consistently outperforms 21 baselines, including isolated supervised learning, FL/FGL, federated adaptations of centralized GFMs, and FedGFM techniques.
Unaligned RGB Guided Hyperspectral Image Super-Resolution with Spatial-Spectral Concordance
May 04, 2025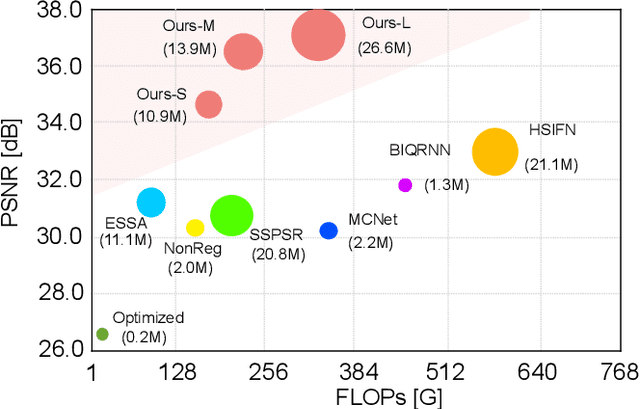
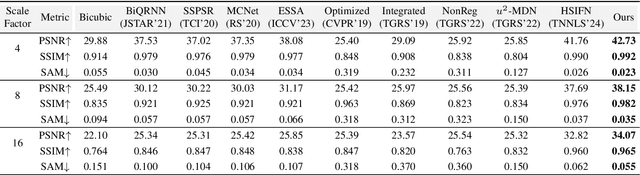
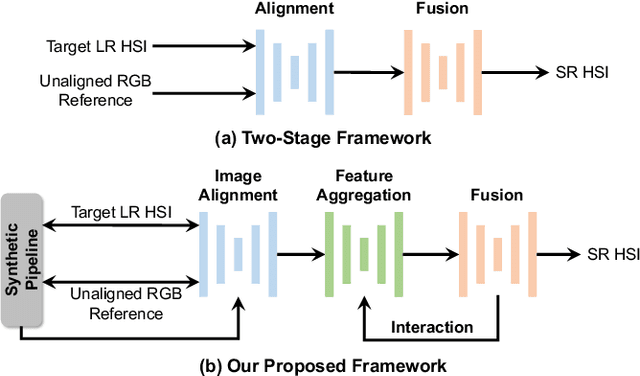
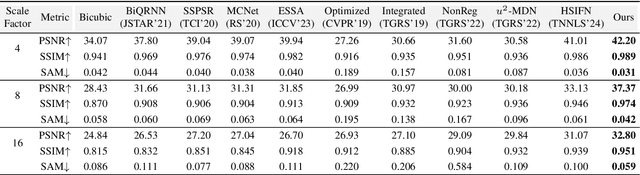
Hyperspectral images super-resolution aims to improve the spatial resolution, yet its performance is often limited at high-resolution ratios. The recent adoption of high-resolution reference images for super-resolution is driven by the poor spatial detail found in low-resolution HSIs, presenting it as a favorable method. However, these approaches cannot effectively utilize information from the reference image, due to the inaccuracy of alignment and its inadequate interaction between alignment and fusion modules. In this paper, we introduce a Spatial-Spectral Concordance Hyperspectral Super-Resolution (SSC-HSR) framework for unaligned reference RGB guided HSI SR to address the issues of inaccurate alignment and poor interactivity of the previous approaches. Specifically, to ensure spatial concordance, i.e., align images more accurately across resolutions and refine textures, we construct a Two-Stage Image Alignment with a synthetic generation pipeline in the image alignment module, where the fine-tuned optical flow model can produce a more accurate optical flow in the first stage and warp model can refine damaged textures in the second stage. To enhance the interaction between alignment and fusion modules and ensure spectral concordance during reconstruction, we propose a Feature Aggregation module and an Attention Fusion module. In the feature aggregation module, we introduce an Iterative Deformable Feature Aggregation block to achieve significant feature matching and texture aggregation with the fusion multi-scale results guidance, iteratively generating learnable offset. Besides, we introduce two basic spectral-wise attention blocks in the attention fusion module to model the inter-spectra interactions. Extensive experiments on three natural or remote-sensing datasets show that our method outperforms state-of-the-art approaches on both quantitative and qualitative evaluations.
Bayesian Cross-Modal Alignment Learning for Few-Shot Out-of-Distribution Generalization
Apr 22, 2025



Recent advances in large pre-trained models showed promising results in few-shot learning. However, their generalization ability on two-dimensional Out-of-Distribution (OoD) data, i.e., correlation shift and diversity shift, has not been thoroughly investigated. Researches have shown that even with a significant amount of training data, few methods can achieve better performance than the standard empirical risk minimization method (ERM) in OoD generalization. This few-shot OoD generalization dilemma emerges as a challenging direction in deep neural network generalization research, where the performance suffers from overfitting on few-shot examples and OoD generalization errors. In this paper, leveraging a broader supervision source, we explore a novel Bayesian cross-modal image-text alignment learning method (Bayes-CAL) to address this issue. Specifically, the model is designed as only text representations are fine-tuned via a Bayesian modelling approach with gradient orthogonalization loss and invariant risk minimization (IRM) loss. The Bayesian approach is essentially introduced to avoid overfitting the base classes observed during training and improve generalization to broader unseen classes. The dedicated loss is introduced to achieve better image-text alignment by disentangling the causal and non-casual parts of image features. Numerical experiments demonstrate that Bayes-CAL achieved state-of-the-art OoD generalization performances on two-dimensional distribution shifts. Moreover, compared with CLIP-like models, Bayes-CAL yields more stable generalization performances on unseen classes. Our code is available at https://github.com/LinLLLL/BayesCAL.
Towards Unbiased Federated Graph Learning: Label and Topology Perspectives
Apr 14, 2025Federated Graph Learning (FGL) enables privacy-preserving, distributed training of graph neural networks without sharing raw data. Among its approaches, subgraph-FL has become the dominant paradigm, with most work focused on improving overall node classification accuracy. However, these methods often overlook fairness due to the complexity of node features, labels, and graph structures. In particular, they perform poorly on nodes with disadvantaged properties, such as being in the minority class within subgraphs or having heterophilous connections (neighbors with dissimilar labels or misleading features). This reveals a critical issue: high accuracy can mask degraded performance on structurally or semantically marginalized nodes. To address this, we advocate for two fairness goals: (1) improving representation of minority class nodes for class-wise fairness and (2) mitigating topological bias from heterophilous connections for topology-aware fairness. We propose FairFGL, a novel framework that enhances fairness through fine-grained graph mining and collaborative learning. On the client side, the History-Preserving Module prevents overfitting to dominant local classes, while the Majority Alignment Module refines representations of heterophilous majority-class nodes. The Gradient Modification Module transfers minority-class knowledge from structurally favorable clients to improve fairness. On the server side, FairFGL uploads only the most influenced subset of parameters to reduce communication costs and better reflect local distributions. A cluster-based aggregation strategy reconciles conflicting updates and curbs global majority dominance . Extensive evaluations on eight benchmarks show FairFGL significantly improves minority-group performance , achieving up to a 22.62 percent Macro-F1 gain while enhancing convergence over state-of-the-art baselines.