 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming the Thinker: Conditional Entropy Shaping for Adaptive LLM Reasoning
May 19, 2026Entropy-based deep reasoning has emerged as a promising direction for improving the reasoning capabilities of Large Language Models (LLMs), but existing methods often either increase response length indiscriminately or shorten responses at the cost of accuracy. To better balance this trade-off, we introduce Conditional Entropy Shaping (CES), a framework that dynamically controls token-level response entropy, enabling LLMs to produce concise solutions on simple problems while encouraging deeper exploration on hard ones. Built on DAPO, CES uses token-level entropy as an uncertainty signal and applies a conditional bidirectional policy: it penalizes high-entropy "forking point" tokens on correct reasoning paths to improve conciseness, and rewards them on incorrect paths to encourage exploration and error correction. We implement CES on DeepSeek-R1-Distill-7B and evaluate it on 12 mathematical benchmarks. CES consistently improves average accuracy while reducing response length relative to DAPO, and supplementary experiments show similar trends on a smaller 1.5B backbone and on out-of-domain benchmarks.
HEALing Entropy Collapse: Enhancing Exploration in Few-Shot RLVR via Hybrid-Domain Entropy Dynamics Alignment
Apr 20, 2026Reinforcement Learning with Verifiable Reward (RLVR) has proven effective for training reasoning-oriented large language models, but existing methods largely assume high-resource settings with abundant training data. In low-resource scenarios, RLVR is prone to more severe entropy collapse, which substantially limits exploration and degrades reasoning performance. To address this issue, we propose Hybrid-domain Entropy dynamics ALignment (HEAL), a framework tailored for few-shot RLVR. HEAL first selectively incorporates high-value general-domain data to promote more diverse exploration. Then, we introduce Entropy Dynamics Alignment (EDA), a reward mechanism that aligns trajectory-level entropy dynamics between the target and general domains, capturing both entropy magnitude and fine-grained variation. Through this alignment, EDA not only further mitigates entropy collapse but also encourages the policy to acquire more diverse exploration behaviors from the general domain. Experiments across multiple domains show that HEAL consistently improves few-shot RLVR performance. Notably, using only 32 target-domain samples, HEAL matches or even surpasses full-shot RLVR trained with 1K target-domain samples.
Parser-Oriented Structural Refinement for a Stable Layout Interface in Document Parsing
Apr 03, 2026Accurate document parsing requires both robust content recognition and a stable parser interface. In explicit Document Layout Analysis (DLA) pipelines, downstream parsers do not consume the full detector output. Instead, they operate on a retained and serialized set of layout instances. However, on dense pages with overlapping regions and ambiguous boundaries, unstable layout hypotheses can make the retained instance set inconsistent with its parser input order, leading to severe downstream parsing errors. To address this issue, we introduce a lightweight structural refinement stage between a DETR-style detector and the parser to stabilize the parser interface. Treating raw detector outputs as a compact hypothesis pool, the proposed module performs set-level reasoning over query features, semantic cues, box geometry, and visual evidence. From a shared refined structural state, it jointly determines instance retention, refines box localization, and predicts parser input order before handoff. We further introduce retention-oriented supervision and a difficulty-aware ordering objective to better align the retained instance set and its order with the final parser input, especially on structurally complex pages. Extensive experiments on public benchmarks show that our method consistently improves page-level layout quality. When integrated into a standard end-to-end parsing pipeline, the stabilized parser interface also substantially reduces sequence mismatch, achieving a Reading Order Edit of 0.024 on OmniDocBench.
Zipper-LoRA: Dynamic Parameter Decoupling for Speech-LLM based Multilingual Speech Recognition
Mar 19, 2026Speech Large Language Models (Speech-LLMs) have emerged as a powerful approach for automatic speech recognition (ASR) by aligning speech encoders with large language models. However, adapting these systems to multilingual settings with imbalanced data distributions remains challenging. In such scenarios, a stability-plasticity dilemma often arises: fully shared Parameter-Efficient Fine-Tuning (PEFT) can cause negative inter-lingual interference for under-represented languages, while fully language-specific tuning limits the cross-lingual beneficial knowledge transfer needed for low-resource tasks. To address this, we propose Zipper-LoRA, a novel rank-level decoupling framework with three variants (Static, Hard, and Soft) that dynamically synthesizes LoRA updates from shared and language-specific subspaces. By using a lightweight language-conditioned router, Zipper-LoRA dynamically controls the contribution of each subspace at the LoRA rank level, enabling fine-grained sharing where languages are compatible and strict decoupling when conflicts occur. To further stabilize optimization under imbalanced data, we propose a two-stage training strategy with an Initial-B warm start that significantly accelerates convergence. Experiments on a 12-language mixed-resource setting show that Zipper-LoRA consistently outperforms both fully shared and independent baselines, particularly in extremely low-resource scenarios. Moreover, we demonstrate that these gains are robust across both chunked and non-chunked encoder configurations, confirming the framework's reliability for practical, large-scale multilingual ASR. Our code and data will be available at https://github.com/YuCeong-May/Zipper-LoRA for reproducibility.
FocalOrder: Focal Preference Optimization for Reading Order Detection
Jan 12, 2026Reading order detection is the foundation of document understanding. Most existing methods rely on uniform supervision, implicitly assuming a constant difficulty distribution across layout regions. In this work, we challenge this assumption by revealing a critical flaw: \textbf{Positional Disparity}, a phenomenon where models demonstrate mastery over the deterministic start and end regions but suffer a performance collapse in the complex intermediate sections. This degradation arises because standard training allows the massive volume of easy patterns to drown out the learning signals from difficult layouts. To address this, we propose \textbf{FocalOrder}, a framework driven by \textbf{Focal Preference Optimization (FPO)}. Specifically, FocalOrder employs adaptive difficulty discovery with exponential moving average mechanism to dynamically pinpoint hard-to-learn transitions, while introducing a difficulty-calibrated pairwise ranking objective to enforce global logical consistency. Extensive experiments demonstrate that FocalOrder establishes new state-of-the-art results on OmniDocBench v1.0 and Comp-HRDoc. Our compact model not only outperforms competitive specialized baselines but also significantly surpasses large-scale general VLMs. These results demonstrate that aligning the optimization with intrinsic structural ambiguity of documents is critical for mastering complex document structures.
PARL: Position-Aware Relation Learning Network for Document Layout Analysis
Jan 12, 2026Document layout analysis aims to detect and categorize structural elements (e.g., titles, tables, figures) in scanned or digital documents. Popular methods often rely on high-quality Optical Character Recognition (OCR) to merge visual features with extracted text. This dependency introduces two major drawbacks: propagation of text recognition errors and substantial computational overhead, limiting the robustness and practical applicability of multimodal approaches. In contrast to the prevailing multimodal trend, we argue that effective layout analysis depends not on text-visual fusion, but on a deep understanding of documents' intrinsic visual structure. To this end, we propose PARL (Position-Aware Relation Learning Network), a novel OCR-free, vision-only framework that models layout through positional sensitivity and relational structure. Specifically, we first introduce a Bidirectional Spatial Position-Guided Deformable Attention module to embed explicit positional dependencies among layout elements directly into visual features. Second, we design a Graph Refinement Classifier (GRC) to refine predictions by modeling contextual relationships through a dynamically constructed layout graph. Extensive experiments show PARL achieves state-of-the-art results. It establishes a new benchmark for vision-only methods on DocLayNet and, notably, surpasses even strong multimodal models on M6Doc. Crucially, PARL (65M) is highly efficient, using roughly four times fewer parameters than large multimodal models (256M), demonstrating that sophisticated visual structure modeling can be both more efficient and robust than multimodal fusion.
Semantic Pivots Enable Cross-Lingual Transfer in Large Language Models
May 22, 2025Large language models (LLMs) demonstrate remarkable ability in cross-lingual tasks. Understanding how LLMs acquire this ability is crucial for their interpretability. To quantify the cross-lingual ability of LLMs accurately, we propose a Word-Level Cross-Lingual Translation Task. To find how LLMs learn cross-lingual ability, we trace the outputs of LLMs' intermediate layers in the word translation task. We identify and distinguish two distinct behaviors in the forward pass of LLMs: co-occurrence behavior and semantic pivot behavior. We attribute LLMs' two distinct behaviors to the co-occurrence frequency of words and find the semantic pivot from the pre-training dataset. Finally, to apply our findings to improve the cross-lingual ability of LLMs, we reconstruct a semantic pivot-aware pre-training dataset using documents with a high proportion of semantic pivots. Our experiments validate the effectiveness of our approach in enhancing cross-lingual ability. Our research contributes insights into the interpretability of LLMs and offers a method for improving LLMs' cross-lingual ability.
Transparentize the Internal and External Knowledge Utilization in LLMs with Trustworthy Citation
Apr 21, 2025While hallucinations of large language models could been alleviated through retrieval-augmented generation and citation generation, how the model utilizes internal knowledge is still opaque, and the trustworthiness of its generated answers remains questionable. In this work, we introduce Context-Prior Augmented Citation Generation task, requiring models to generate citations considering both external and internal knowledge while providing trustworthy references, with 5 evaluation metrics focusing on 3 aspects: answer helpfulness, citation faithfulness, and trustworthiness. We introduce RAEL, the paradigm for our task, and also design INTRALIGN, an integrated method containing customary data generation and an alignment algorithm. Our experimental results show that our method achieves a better cross-scenario performance with regard to other baselines. Our extended experiments further reveal that retrieval quality, question types, and model knowledge have considerable influence on the trustworthiness in citation generation.
A Multi-Agent Framework with Automated Decision Rule Optimization for Cross-Domain Misinformation Detection
Mar 30, 2025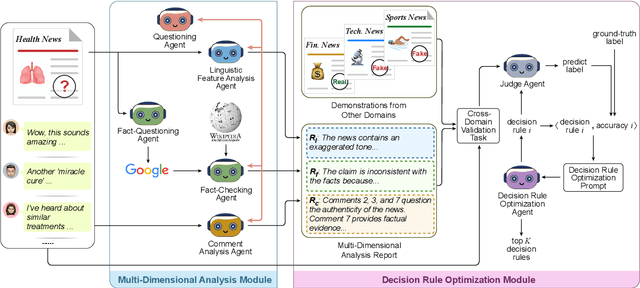
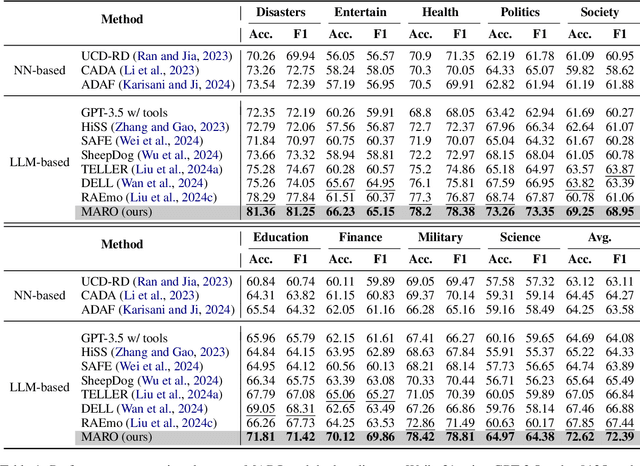
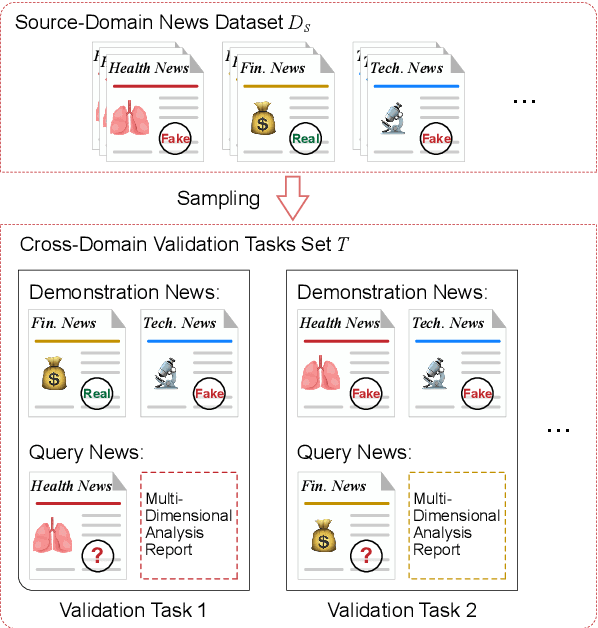
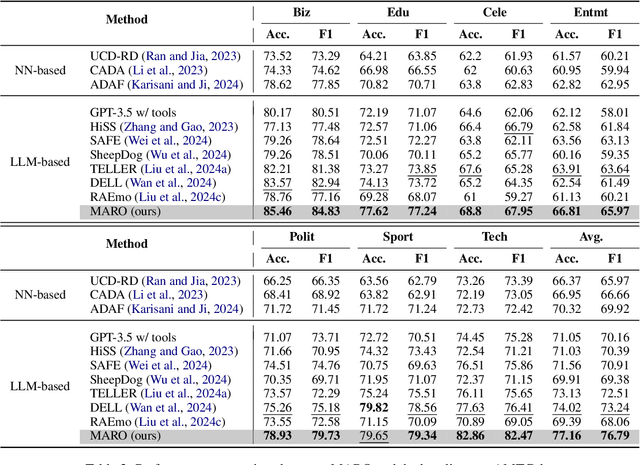
Misinformation spans various domains, but detection methods trained on specific domains often perform poorly when applied to others. With the rapid development of Large Language Models (LLMs), researchers have begun to utilize LLMs for cross-domain misinformation detection. However, existing LLM-based methods often fail to adequately analyze news in the target domain, limiting their detection capabilities. More importantly, these methods typically rely on manually designed decision rules, which are limited by domain knowledge and expert experience, thus limiting the generalizability of decision rules to different domains. To address these issues, we propose a MultiAgent Framework for cross-domain misinformation detection with Automated Decision Rule Optimization (MARO). Under this framework, we first employs multiple expert agents to analyze target-domain news. Subsequently, we introduce a question-reflection mechanism that guides expert agents to facilitate higherquality analysis. Furthermore, we propose a decision rule optimization approach based on carefully-designed cross-domain validation tasks to iteratively enhance the effectiveness of decision rules in different domains. Experimental results and in-depth analysis on commonlyused datasets demonstrate that MARO achieves significant improvements over existing methods.
Contextual Dictionary Lookup for Knowledge Graph Completion
Jun 13, 2023Knowledge graph completion (KGC) aims to solve the incompleteness of knowledge graphs (KGs) by predicting missing links from known triples, numbers of knowledge graph embedding (KGE) models have been proposed to perform KGC by learning embeddings. Nevertheless, most existing embedding models map each relation into a unique vector, overlooking the specific fine-grained semantics of them under different entities. Additionally, the few available fine-grained semantic models rely on clustering algorithms, resulting in limited performance and applicability due to the cumbersome two-stage training process. In this paper, we present a novel method utilizing contextual dictionary lookup, enabling conventional embedding models to learn fine-grained semantics of relations in an end-to-end manner. More specifically, we represent each relation using a dictionary that contains multiple latent semantics. The composition of a given entity and the dictionary's central semantics serves as the context for generating a lookup, thus determining the fine-grained semantics of the relation adaptively. The proposed loss function optimizes both the central and fine-grained semantics simultaneously to ensure their semantic consistency. Besides, we introduce two metrics to assess the validity and accuracy of the dictionary lookup operation. We extend several KGE models with the method, resulting in substantial performance improvements on widely-used benchmark datasets.