 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Semantic Calibration Network for Open-Vocabulary Semantic Segmentation
Jun 06, 2026Semantic image segmentation assigns a predefined category label to each pixel, has achieved significant progress lately. Open-Vocabulary Segmentation (OVS) extends the segmentation task from a fixed set to an open set, enabling the identification and segmentation of novel concepts based on arbitrary text inputs, such as category names or descriptions. In this paper, we propose a novel Semantic Calibration Network (SCN) for open-vocabulary semantic segmentation. Different from prior approaches that focus on feature aggregation or simple fine-tuning of pre-trained models, SCN refines the mask classification process by explicitly modeling the semantic correlations between classes, aiming to enhance the model's discriminative power while effectively preserving the generalization abilities of the pre-trained CLIP model. Specifically, SCN comprises two core components: Class Disambiguation (CD) and Logits Fusion (LF). First, a cross-attention mechanism is utilized to transform the text embeddings into visually aware pseudo-text embeddings, in order to derive an enhanced similarity score that complements the original mask-text similarity score. Subsequently, the Class Disambiguation module captures implicit inter-class dependencies through a residual architecture to effectively resolve semantic ambiguities. Finally, the Logits Fusion module dynamically integrates multifaceted semantic evidence to ensure that the model achieves a robust semantic consensus while maintaining CLIP's inherent generalization capability. Comprehensive experimental results on mainstream benchmarks demonstrate that the proposed method achieves significant performance improvements compared to state-of-the-art algorithms.
RASR: Retrieval-Augmented Semantic Reasoning for Fake News Video Detection
Apr 08, 2026Multimodal fake news video detection is a crucial research direction for maintaining the credibility of online information. Existing studies primarily verify content authenticity by constructing multimodal feature fusion representations or utilizing pre-trained language models to analyze video-text consistency. However, these methods still face the following limitations: (1) lacking cross-instance global semantic correlations, making it difficult to effectively utilize historical associative evidence to verify the current video; (2) semantic discrepancies across domains hinder the transfer of general knowledge, lacking the guidance of domain-specific expert knowledge. To this end, we propose a novel Retrieval-Augmented Semantic Reasoning (RASR) framework. First, a Cross-instance Semantic Parser and Retriever (CSPR) deconstructs the video into high-level semantic primitives and retrieves relevant associative evidence from a dynamic memory bank. Subsequently, a Domain-Guided Multimodal Reasoning (DGMP) module incorporates domain priors to drive an expert multimodal large language model in generating domain-aware, in-depth analysis reports. Finally, a Multi-View Feature Decoupling and Fusion (MVDFF) module integrates multi-dimensional features through an adaptive gating mechanism to achieve robust authenticity determination. Extensive experiments on the FakeSV and FakeTT datasets demonstrate that RASR significantly outperforms state-of-the-art baselines, achieves superior cross-domain generalization, and improves the overall detection accuracy by up to 0.93%.
Mitigating the Negative Impact of Over-association for Conversational Query Production
Sep 29, 2024



Conversational query generation aims at producing search queries from dialogue histories, which are then used to retrieve relevant knowledge from a search engine to help knowledge-based dialogue systems. Trained to maximize the likelihood of gold queries, previous models suffer from the data hunger issue, and they tend to both drop important concepts from dialogue histories and generate irrelevant concepts at inference time. We attribute these issues to the over-association phenomenon where a large number of gold queries are indirectly related to the dialogue topics, because annotators may unconsciously perform reasoning with their background knowledge when generating these gold queries. We carefully analyze the negative effects of this phenomenon on pretrained Seq2seq query producers and then propose effective instance-level weighting strategies for training to mitigate these issues from multiple perspectives. Experiments on two benchmarks, Wizard-of-Internet and DuSinc, show that our strategies effectively alleviate the negative effects and lead to significant performance gains (2%-5% across automatic metrics and human evaluation). Further analysis shows that our model selects better concepts from dialogue histories and is 10 times more data efficient than the baseline. The code is available at https://github.com/DeepLearnXMU/QG-OverAsso.
SensoryT5: Infusing Sensorimotor Norms into T5 for Enhanced Fine-grained Emotion Classification
Mar 22, 2024



In traditional research approaches, sensory perception and emotion classification have traditionally been considered separate domains. Yet, the significant influence of sensory experiences on emotional responses is undeniable. The natural language processing (NLP) community has often missed the opportunity to merge sensory knowledge with emotion classification. To address this gap, we propose SensoryT5, a neuro-cognitive approach that integrates sensory information into the T5 (Text-to-Text Transfer Transformer) model, designed specifically for fine-grained emotion classification. This methodology incorporates sensory cues into the T5's attention mechanism, enabling a harmonious balance between contextual understanding and sensory awareness. The resulting model amplifies the richness of emotional representations. In rigorous tests across various detailed emotion classification datasets, SensoryT5 showcases improved performance, surpassing both the foundational T5 model and current state-of-the-art works. Notably, SensoryT5's success signifies a pivotal change in the NLP domain, highlighting the potential influence of neuro-cognitive data in refining machine learning models' emotional sensitivity.
Edge Data Based Trailer Inception Probabilistic Matrix Factorization for Context-Aware Movie Recommendation
Feb 16, 2022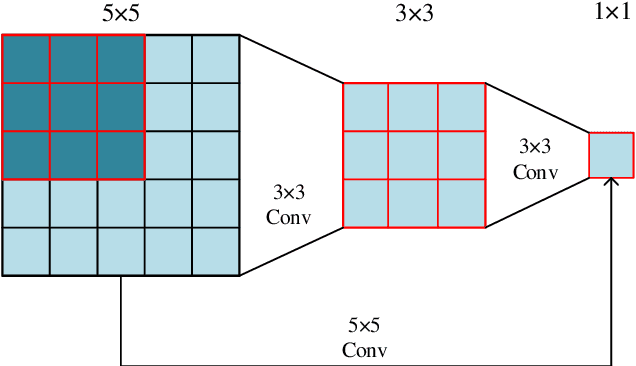

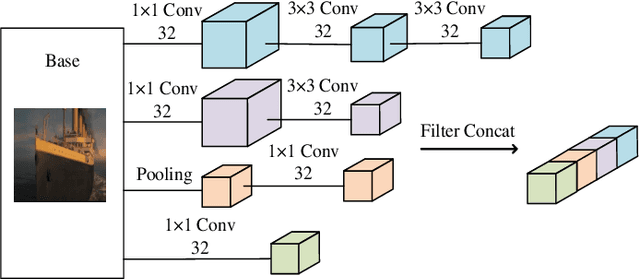
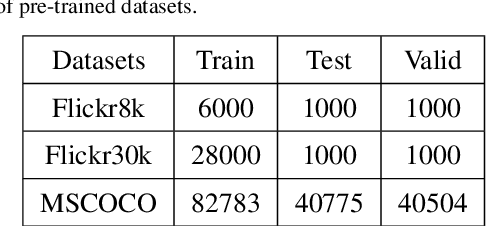
The rapid growth of edge data generated by mobile devices and applications deployed at the edge of the network has exacerbated the problem of information overload. As an effective way to alleviate information overload, recommender system can improve the quality of various services by adding application data generated by users on edge devices, such as visual and textual information, on the basis of sparse rating data. The visual information in the movie trailer is a significant part of the movie recommender system. However, due to the complexity of visual information extraction, data sparsity cannot be remarkably alleviated by merely using the rough visual features to improve the rating prediction accuracy. Fortunately, the convolutional neural network can be used to extract the visual features precisely. Therefore, the end-to-end neural image caption (NIC) model can be utilized to obtain the textual information describing the visual features of movie trailers. This paper proposes a trailer inception probabilistic matrix factorization model called Ti-PMF, which combines NIC, recurrent convolutional neural network, and probabilistic matrix factorization models as the rating prediction model. We implement the proposed Ti-PMF model with extensive experiments on three real-world datasets to validate its effectiveness. The experimental results illustrate that the proposed Ti-PMF outperforms the existing ones.
Distract Your Attention: Multi-head Cross Attention Network for Facial Expression Recognition
Sep 15, 2021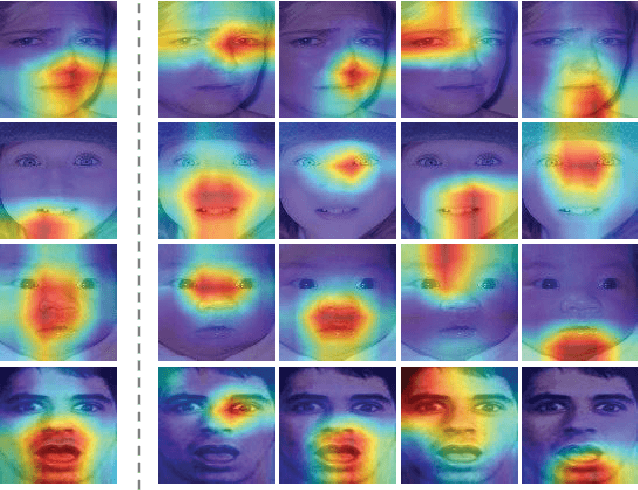
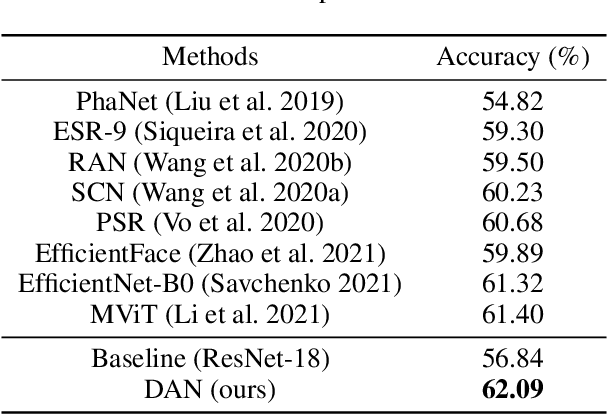
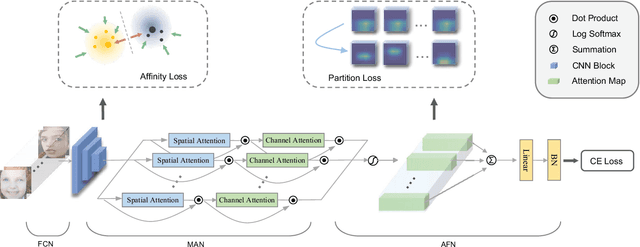
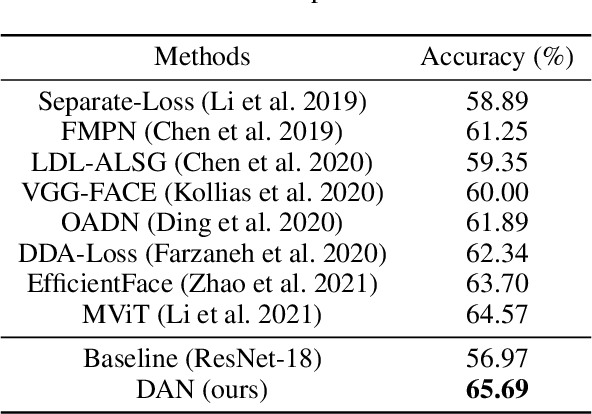
We present a novel facial expression recognition network, called Distract your Attention Network (DAN). Our method is based on two key observations. Firstly, multiple classes share inherently similar underlying facial appearance, and their differences could be subtle. Secondly, facial expressions exhibit themselves through multiple facial regions simultaneously, and the recognition requires a holistic approach by encoding high-order interactions among local features. To address these issues, we propose our DAN with three key components: Feature Clustering Network (FCN), Multi-head cross Attention Network (MAN), and Attention Fusion Network (AFN). The FCN extracts robust features by adopting a large-margin learning objective to maximize class separability. In addition, the MAN instantiates a number of attention heads to simultaneously attend to multiple facial areas and build attention maps on these regions. Further, the AFN distracts these attentions to multiple locations before fusing the attention maps to a comprehensive one. Extensive experiments on three public datasets (including AffectNet, RAF-DB, and SFEW 2.0) verified that the proposed method consistently achieves state-of-the-art facial expression recognition performance. Code will be made available at https://github.com/yaoing/DAN.