 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Reconstruction as Mapping Priors for 3D Detection
May 21, 2026In autonomous driving, mapping is critical for motion planning but remains an under-utilized resource for perception tasks such as 3D object detection. Maps can provide robust structural priors of the static environment, helping resolve ambiguities and correct for sensor data sparsity or noise, especially for distant objects or under adverse weather conditions. However, conventional High-Definition (HD) maps are resource-intensive to obtain and maintain, which presents a challenge for efficient, large-scale deployment. In this paper, we propose a scalable solution to systematically leverage mapping to improve 3D detection by overcoming two primary challenges. First, we introduce a pipeline to automatically build dense mapping priors from aggregated sensor data, eliminating the need for human labeling. Second, we design a novel Mapping Priors Augmented 3D Detection (MPA3D) framework to effectively integrate mapping priors with different sensor modalities. Extensive experiments on the Waymo Open Dataset demonstrate that our approach achieves new state-of-the-art results, proving the effectiveness of scalable reconstructed scene priors for enhancing 3D detection.
STELLAR: Scaling 3D Perception Large Models for Autonomous Driving
May 19, 2026Model scaling has demonstrated remarkable success through large-scale training on diverse datasets. It remains an open question whether the same paradigm would apply to autonomous driving perception systems due to unique challenges, such as fusing heterogeneous sensor data and the need for sophisticated 3D spatial understanding. To bridge this gap, we present a comprehensive study on systematically analyzing the impact of scale on these systems. We develop our STELLAR model based on Sparse Window Transformer, by extending the input modalities to include LiDAR, radar, camera, and map prior. We train the model on a large-scale dataset of 50 million driving examples with up to 500 million parameters. Our large-scale experiments reveal empirical scaling trends that connect model performance to model size, data, and compute. The resulting model establishes a new state-of-the-art on the Waymo Open Dataset challenge, outperforming prior arts by a large margin. Our work demonstrates that large-scale training is a highly promising path for advancing the capabilities of perception models for autonomous driving.
WOD-E2E: Waymo Open Dataset for End-to-End Driving in Challenging Long-tail Scenarios
Oct 30, 2025Vision-based end-to-end (E2E) driving has garnered significant interest in the research community due to its scalability and synergy with multimodal large language models (MLLMs). However, current E2E driving benchmarks primarily feature nominal scenarios, failing to adequately test the true potential of these systems. Furthermore, existing open-loop evaluation metrics often fall short in capturing the multi-modal nature of driving or effectively evaluating performance in long-tail scenarios. To address these gaps, we introduce the Waymo Open Dataset for End-to-End Driving (WOD-E2E). WOD-E2E contains 4,021 driving segments (approximately 12 hours), specifically curated for challenging long-tail scenarios that that are rare in daily life with an occurring frequency of less than 0.03%. Concretely, each segment in WOD-E2E includes the high-level routing information, ego states, and 360-degree camera views from 8 surrounding cameras. To evaluate the E2E driving performance on these long-tail situations, we propose a novel open-loop evaluation metric: Rater Feedback Score (RFS). Unlike conventional metrics that measure the distance between predicted way points and the logs, RFS measures how closely the predicted trajectory matches rater-annotated trajectory preference labels. We have released rater preference labels for all WOD-E2E validation set segments, while the held out test set labels have been used for the 2025 WOD-E2E Challenge. Through our work, we aim to foster state of the art research into generalizable, robust, and safe end-to-end autonomous driving agents capable of handling complex real-world situations.
SceneCrafter: Controllable Multi-View Driving Scene Editing
Jun 24, 2025Simulation is crucial for developing and evaluating autonomous vehicle (AV) systems. Recent literature builds on a new generation of generative models to synthesize highly realistic images for full-stack simulation. However, purely synthetically generated scenes are not grounded in reality and have difficulty in inspiring confidence in the relevance of its outcomes. Editing models, on the other hand, leverage source scenes from real driving logs, and enable the simulation of different traffic layouts, behaviors, and operating conditions such as weather and time of day. While image editing is an established topic in computer vision, it presents fresh sets of challenges in driving simulation: (1) the need for cross-camera 3D consistency, (2) learning ``empty street" priors from driving data with foreground occlusions, and (3) obtaining paired image tuples of varied editing conditions while preserving consistent layout and geometry. To address these challenges, we propose SceneCrafter, a versatile editor for realistic 3D-consistent manipulation of driving scenes captured from multiple cameras. We build on recent advancements in multi-view diffusion models, using a fully controllable framework that scales seamlessly to multi-modality conditions like weather, time of day, agent boxes and high-definition maps. To generate paired data for supervising the editing model, we propose a novel framework on top of Prompt-to-Prompt to generate geometrically consistent synthetic paired data with global edits. We also introduce an alpha-blending framework to synthesize data with local edits, leveraging a model trained on empty street priors through novel masked training and multi-view repaint paradigm. SceneCrafter demonstrates powerful editing capabilities and achieves state-of-the-art realism, controllability, 3D consistency, and scene editing quality compared to existing baselines.
Differentially Private Video Activity Recognition
Jun 27, 2023



In recent years, differential privacy has seen significant advancements in image classification; however, its application to video activity recognition remains under-explored. This paper addresses the challenges of applying differential privacy to video activity recognition, which primarily stem from: (1) a discrepancy between the desired privacy level for entire videos and the nature of input data processed by contemporary video architectures, which are typically short, segmented clips; and (2) the complexity and sheer size of video datasets relative to those in image classification, which render traditional differential privacy methods inadequate. To tackle these issues, we propose Multi-Clip DP-SGD, a novel framework for enforcing video-level differential privacy through clip-based classification models. This method samples multiple clips from each video, averages their gradients, and applies gradient clipping in DP-SGD without incurring additional privacy loss. Moreover, we incorporate a parameter-efficient transfer learning strategy to make the model scalable for large-scale video datasets. Through extensive evaluations on the UCF-101 and HMDB-51 datasets, our approach exhibits impressive performance, achieving 81% accuracy with a privacy budget of epsilon=5 on UCF-101, marking a 76% improvement compared to a direct application of DP-SGD. Furthermore, we demonstrate that our transfer learning strategy is versatile and can enhance differentially private image classification across an array of datasets including CheXpert, ImageNet, CIFAR-10, and CIFAR-100.
Learning Instance-Specific Adaptation for Cross-Domain Segmentation
Mar 30, 2022
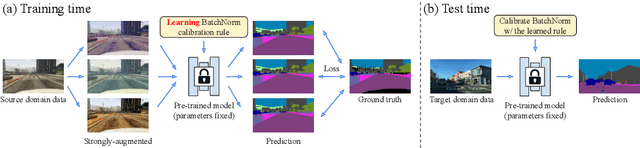
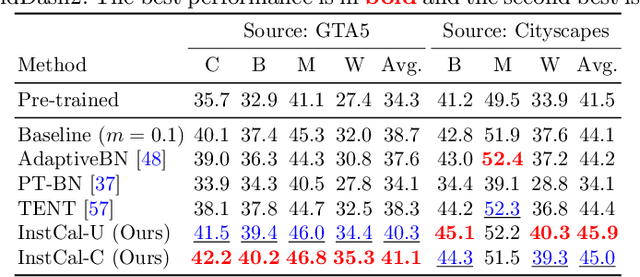

We propose a test-time adaptation method for cross-domain image segmentation. Our method is simple: Given a new unseen instance at test time, we adapt a pre-trained model by conducting instance-specific BatchNorm (statistics) calibration. Our approach has two core components. First, we replace the manually designed BatchNorm calibration rule with a learnable module. Second, we leverage strong data augmentation to simulate random domain shifts for learning the calibration rule. In contrast to existing domain adaptation methods, our method does not require accessing the target domain data at training time or conducting computationally expensive test-time model training/optimization. Equipping our method with models trained by standard recipes achieves significant improvement, comparing favorably with several state-of-the-art domain generalization and one-shot unsupervised domain adaptation approaches. Combining our method with the domain generalization methods further improves performance, reaching a new state of the art.
Learning Representational Invariances for Data-Efficient Action Recognition
Mar 30, 2021

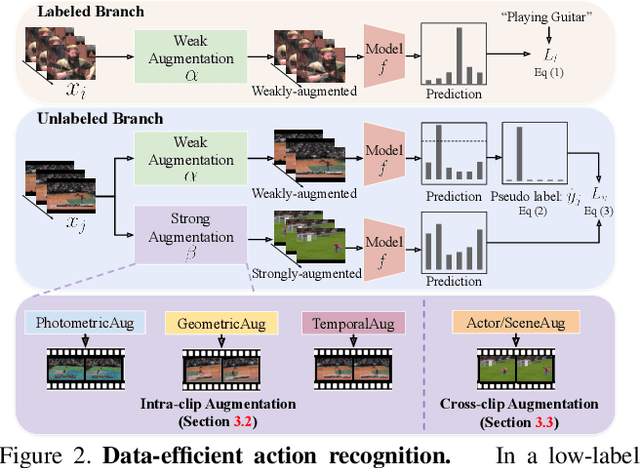
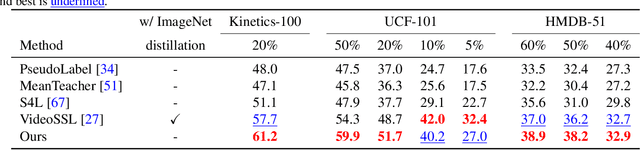
Data augmentation is a ubiquitous technique for improving image classification when labeled data is scarce. Constraining the model predictions to be invariant to diverse data augmentations effectively injects the desired representational invariances to the model (e.g., invariance to photometric variations), leading to improved accuracy. Compared to image data, the appearance variations in videos are far more complex due to the additional temporal dimension. Yet, data augmentation methods for videos remain under-explored. In this paper, we investigate various data augmentation strategies that capture different video invariances, including photometric, geometric, temporal, and actor/scene augmentations. When integrated with existing consistency-based semi-supervised learning frameworks, we show that our data augmentation strategy leads to promising performance on the Kinetics-100, UCF-101, and HMDB-51 datasets in the low-label regime. We also validate our data augmentation strategy in the fully supervised setting and demonstrate improved performance.
PseudoSeg: Designing Pseudo Labels for Semantic Segmentation
Oct 19, 2020
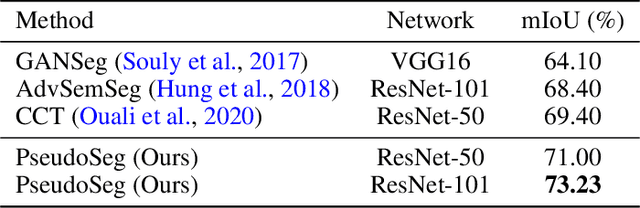

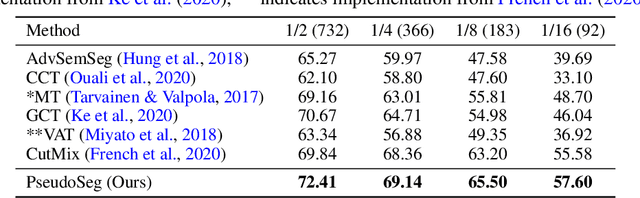
Recent advances in semi-supervised learning (SSL) demonstrate that a combination of consistency regularization and pseudo-labeling can effectively improve image classification accuracy in the low-data regime. Compared to classification, semantic segmentation tasks require much more intensive labeling costs. Thus, these tasks greatly benefit from data-efficient training methods. However, structured outputs in segmentation render particular difficulties (e.g., designing pseudo-labeling and augmentation) to apply existing SSL strategies. To address this problem, we present a simple and novel re-design of pseudo-labeling to generate well-calibrated structured pseudo labels for training with unlabeled or weakly-labeled data. Our proposed pseudo-labeling strategy is network structure agnostic to apply in a one-stage consistency training framework. We demonstrate the effectiveness of the proposed pseudo-labeling strategy in both low-data and high-data regimes. Extensive experiments have validated that pseudo labels generated from wisely fusing diverse sources and strong data augmentation are crucial to consistency training for segmentation. The source code is available at https://github.com/googleinterns/wss.
DRG: Dual Relation Graph for Human-Object Interaction Detection
Aug 26, 2020

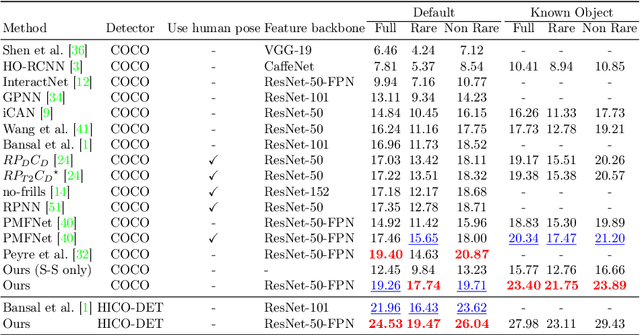
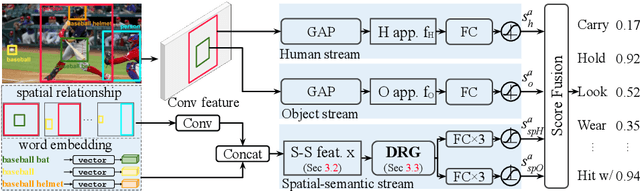
We tackle the challenging problem of human-object interaction (HOI) detection. Existing methods either recognize the interaction of each human-object pair in isolation or perform joint inference based on complex appearance-based features. In this paper, we leverage an abstract spatial-semantic representation to describe each human-object pair and aggregate the contextual information of the scene via a dual relation graph (one human-centric and one object-centric). Our proposed dual relation graph effectively captures discriminative cues from the scene to resolve ambiguity from local predictions. Our model is conceptually simple and leads to favorable results compared to the state-of-the-art HOI detection algorithms on two large-scale benchmark datasets.
Learning Monocular Visual Odometry via Self-Supervised Long-Term Modeling
Jul 21, 2020
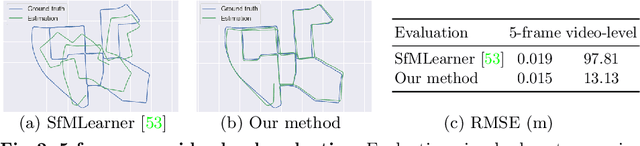
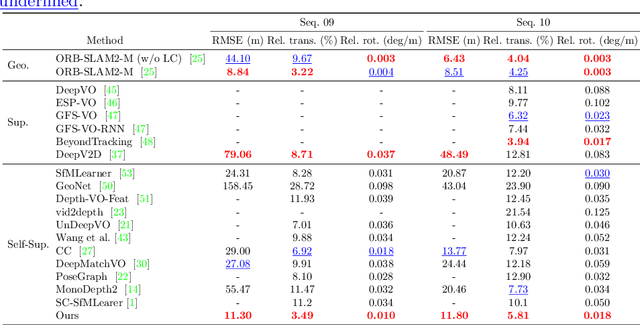
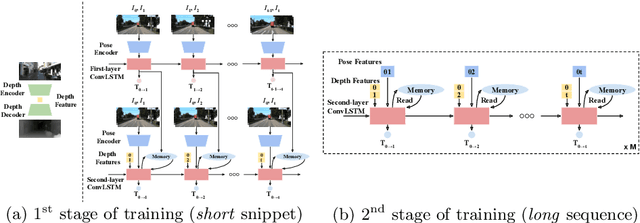
Monocular visual odometry (VO) suffers severely from error accumulation during frame-to-frame pose estimation. In this paper, we present a self-supervised learning method for VO with special consideration for consistency over longer sequences. To this end, we model the long-term dependency in pose prediction using a pose network that features a two-layer convolutional LSTM module. We train the networks with purely self-supervised losses, including a cycle consistency loss that mimics the loop closure module in geometric VO. Inspired by prior geometric systems, we allow the networks to see beyond a small temporal window during training, through a novel a loss that incorporates temporally distant (e.g., O(100)) frames. Given GPU memory constraints, we propose a stage-wise training mechanism, where the first stage operates in a local time window and the second stage refines the poses with a "global" loss given the first stage features. We demonstrate competitive results on several standard VO datasets, including KITTI and TUM RGB-D.