 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWOD-E2E: Waymo Open Dataset for End-to-End Driving in Challenging Long-tail Scenarios
Oct 30, 2025Vision-based end-to-end (E2E) driving has garnered significant interest in the research community due to its scalability and synergy with multimodal large language models (MLLMs). However, current E2E driving benchmarks primarily feature nominal scenarios, failing to adequately test the true potential of these systems. Furthermore, existing open-loop evaluation metrics often fall short in capturing the multi-modal nature of driving or effectively evaluating performance in long-tail scenarios. To address these gaps, we introduce the Waymo Open Dataset for End-to-End Driving (WOD-E2E). WOD-E2E contains 4,021 driving segments (approximately 12 hours), specifically curated for challenging long-tail scenarios that that are rare in daily life with an occurring frequency of less than 0.03%. Concretely, each segment in WOD-E2E includes the high-level routing information, ego states, and 360-degree camera views from 8 surrounding cameras. To evaluate the E2E driving performance on these long-tail situations, we propose a novel open-loop evaluation metric: Rater Feedback Score (RFS). Unlike conventional metrics that measure the distance between predicted way points and the logs, RFS measures how closely the predicted trajectory matches rater-annotated trajectory preference labels. We have released rater preference labels for all WOD-E2E validation set segments, while the held out test set labels have been used for the 2025 WOD-E2E Challenge. Through our work, we aim to foster state of the art research into generalizable, robust, and safe end-to-end autonomous driving agents capable of handling complex real-world situations.
Saliency-Aware Quantized Imitation Learning for Efficient Robotic Control
May 21, 2025



Deep neural network (DNN)-based policy models, such as vision-language-action (VLA) models, excel at automating complex decision-making from multi-modal inputs. However, scaling these models greatly increases computational overhead, complicating deployment in resource-constrained settings like robot manipulation and autonomous driving. To address this, we propose Saliency-Aware Quantized Imitation Learning (SQIL), which combines quantization-aware training with a selective loss-weighting strategy for mission-critical states. By identifying these states via saliency scores and emphasizing them in the training loss, SQIL preserves decision fidelity under low-bit precision. We validate SQIL's generalization capability across extensive simulation benchmarks with environment variations, real-world tasks, and cross-domain tasks (self-driving, physics simulation), consistently recovering full-precision performance. Notably, a 4-bit weight-quantized VLA model for robotic manipulation achieves up to 2.5x speedup and 2.5x energy savings on an edge GPU with minimal accuracy loss. These results underline SQIL's potential for efficiently deploying large IL-based policy models on resource-limited devices.
Quantization-Aware Imitation-Learning for Resource-Efficient Robotic Control
Dec 02, 2024



Deep neural network (DNN)-based policy models like vision-language-action (VLA) models are transformative in automating complex decision-making across applications by interpreting multi-modal data. However, scaling these models greatly increases computational costs, which presents challenges in fields like robot manipulation and autonomous driving that require quick, accurate responses. To address the need for deployment on resource-limited hardware, we propose a new quantization framework for IL-based policy models that fine-tunes parameters to enhance robustness against low-bit precision errors during training, thereby maintaining efficiency and reliability under constrained conditions. Our evaluations with representative robot manipulation for 4-bit weight-quantization on a real edge GPU demonstrate that our framework achieves up to 2.5x speedup and 2.5x energy savings while preserving accuracy. For 4-bit weight and activation quantized self-driving models, the framework achieves up to 3.7x speedup and 3.1x energy saving on a low-end GPU. These results highlight the practical potential of deploying IL-based policy models on resource-constrained devices.
AdaEDL: Early Draft Stopping for Speculative Decoding of Large Language Models via an Entropy-based Lower Bound on Token Acceptance Probability
Oct 24, 2024



Speculative decoding is a powerful technique that attempts to circumvent the autoregressive constraint of modern Large Language Models (LLMs). The aim of speculative decoding techniques is to improve the average inference time of a large, target model without sacrificing its accuracy, by using a more efficient draft model to propose draft tokens which are then verified in parallel. The number of draft tokens produced in each drafting round is referred to as the draft length and is often a static hyperparameter chosen based on the acceptance rate statistics of the draft tokens. However, setting a static draft length can negatively impact performance, especially in scenarios where drafting is expensive and there is a high variance in the number of tokens accepted. Adaptive Entropy-based Draft Length (AdaEDL) is a simple, training and parameter-free criteria which allows for early stopping of the token drafting process by approximating a lower bound on the expected acceptance probability of the drafted token based on the currently observed entropy of the drafted logits. We show that AdaEDL consistently outperforms static draft-length speculative decoding by 10%-57% as well as other training-free draft-stopping techniques by upto 10% in a variety of settings and datasets. At the same time, we show that AdaEDL is more robust than these techniques and preserves performance in high-sampling-temperature scenarios. Since it is training-free, in contrast to techniques that rely on the training of dataset-specific draft-stopping predictors, AdaEDL can seamlessly be integrated into a variety of pre-existing LLM systems.
On Speculative Decoding for Multimodal Large Language Models
Apr 13, 2024



Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$\times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
Direct Alignment of Draft Model for Speculative Decoding with Chat-Fine-Tuned LLMs
Mar 08, 2024



Text generation with Large Language Models (LLMs) is known to be memory bound due to the combination of their auto-regressive nature, huge parameter counts, and limited memory bandwidths, often resulting in low token rates. Speculative decoding has been proposed as a solution for LLM inference acceleration. However, since draft models are often unavailable in the modern open-source LLM families, e.g., for Llama 2 7B, training a high-quality draft model is required to enable inference acceleration via speculative decoding. In this paper, we propose a simple draft model training framework for direct alignment to chat-capable target models. With the proposed framework, we train Llama 2 Chat Drafter 115M, a draft model for Llama 2 Chat 7B or larger, with only 1.64\% of the original size. Our training framework only consists of pretraining, distillation dataset generation, and finetuning with knowledge distillation, with no additional alignment procedure. For the finetuning step, we use instruction-response pairs generated by target model for distillation in plausible data distribution, and propose a new Total Variation Distance++ (TVD++) loss that incorporates variance reduction techniques inspired from the policy gradient method in reinforcement learning. Our empirical results show that Llama 2 Chat Drafter 115M with speculative decoding achieves up to 2.3 block efficiency and 2.4$\times$ speed-up relative to autoregressive decoding on various tasks with no further task-specific fine-tuning.
Recursive Speculative Decoding: Accelerating LLM Inference via Sampling Without Replacement
Mar 05, 2024



Speculative decoding is an inference-acceleration method for large language models (LLMs) where a small language model generates a draft-token sequence which is further verified by the target LLM in parallel. Recent works have advanced this method by establishing a draft-token tree, achieving superior performance over a single-sequence speculative decoding. However, those works independently generate tokens at each level of the tree, not leveraging the tree's entire diversifiability. Besides, their empirical superiority has been shown for fixed length of sequences, implicitly granting more computational resource to LLM for the tree-based methods. None of the existing works has conducted empirical studies with fixed target computational budgets despite its importance to resource-bounded devices. We present Recursive Speculative Decoding (RSD), a novel tree-based method that samples draft tokens without replacement and maximizes the diversity of the tree. During RSD's drafting, the tree is built by either Gumbel-Top-$k$ trick that draws tokens without replacement in parallel or Stochastic Beam Search that samples sequences without replacement while early-truncating unlikely draft sequences and reducing the computational cost of LLM. We empirically evaluate RSD with Llama 2 and OPT models, showing that RSD outperforms the baseline methods, consistently for fixed draft sequence length and in most cases for fixed computational budgets at LLM.
Local Metric Learning for Off-Policy Evaluation in Contextual Bandits with Continuous Actions
Oct 25, 2022



We consider local kernel metric learning for off-policy evaluation (OPE) of deterministic policies in contextual bandits with continuous action spaces. Our work is motivated by practical scenarios where the target policy needs to be deterministic due to domain requirements, such as prescription of treatment dosage and duration in medicine. Although importance sampling (IS) provides a basic principle for OPE, it is ill-posed for the deterministic target policy with continuous actions. Our main idea is to relax the target policy and pose the problem as kernel-based estimation, where we learn the kernel metric in order to minimize the overall mean squared error (MSE). We present an analytic solution for the optimal metric, based on the analysis of bias and variance. Whereas prior work has been limited to scalar action spaces or kernel bandwidth selection, our work takes a step further being capable of vector action spaces and metric optimization. We show that our estimator is consistent, and significantly reduces the MSE compared to baseline OPE methods through experiments on various domains.
Neural Topological Ordering for Computation Graphs
Jul 13, 2022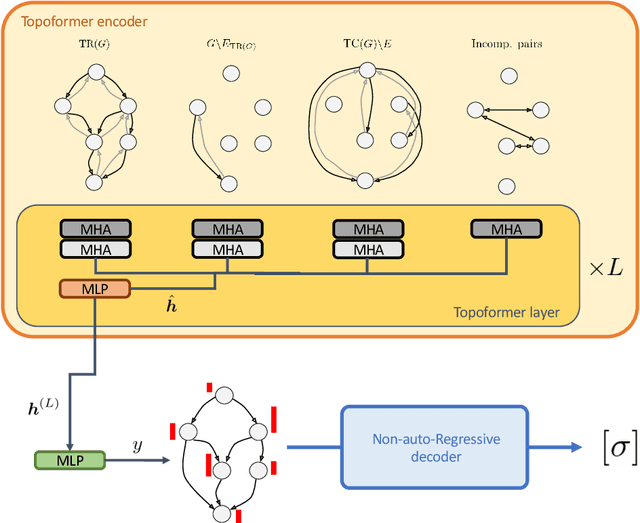
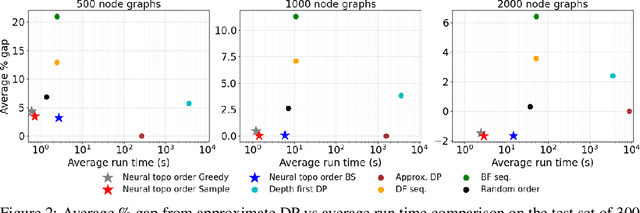
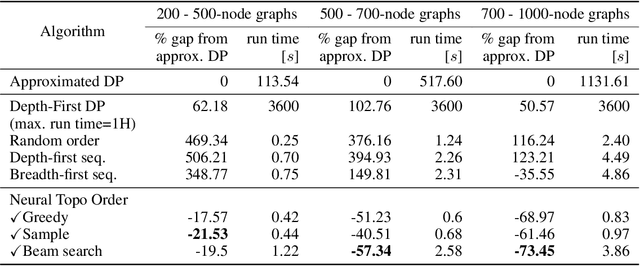
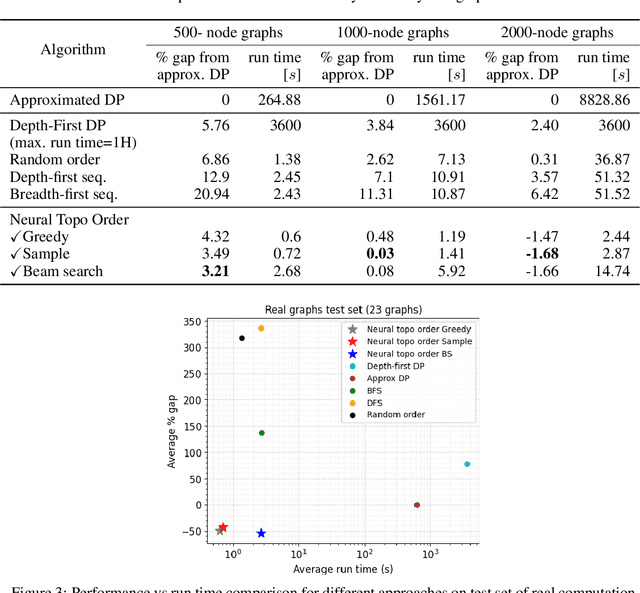
Recent works on machine learning for combinatorial optimization have shown that learning based approaches can outperform heuristic methods in terms of speed and performance. In this paper, we consider the problem of finding an optimal topological order on a directed acyclic graph with focus on the memory minimization problem which arises in compilers. We propose an end-to-end machine learning based approach for topological ordering using an encoder-decoder framework. Our encoder is a novel attention based graph neural network architecture called \emph{Topoformer} which uses different topological transforms of a DAG for message passing. The node embeddings produced by the encoder are converted into node priorities which are used by the decoder to generate a probability distribution over topological orders. We train our model on a dataset of synthetically generated graphs called layered graphs. We show that our model outperforms, or is on-par, with several topological ordering baselines while being significantly faster on synthetic graphs with up to 2k nodes. We also train and test our model on a set of real-world computation graphs, showing performance improvements.
OptiDICE: Offline Policy Optimization via Stationary Distribution Correction Estimation
Jun 21, 2021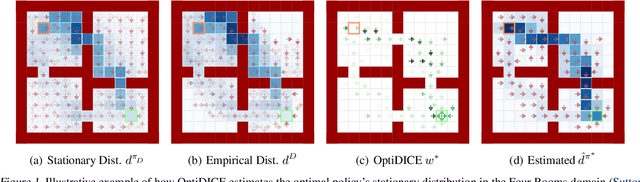

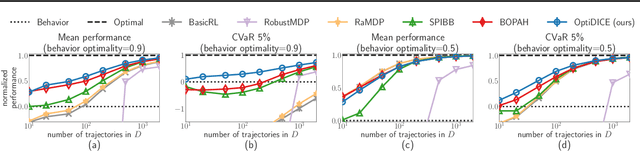
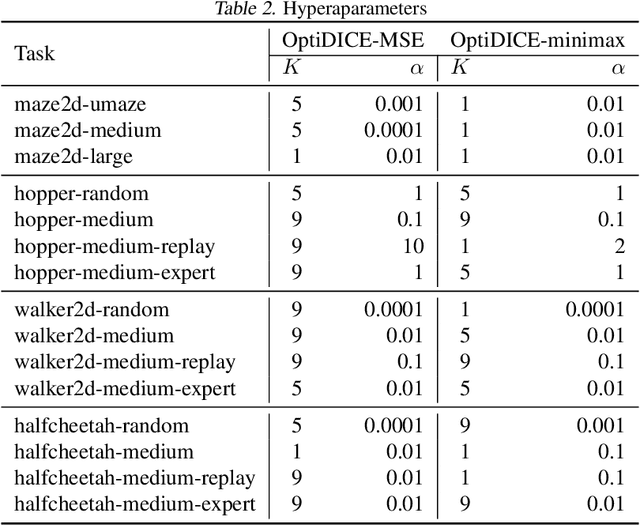
We consider the offline reinforcement learning (RL) setting where the agent aims to optimize the policy solely from the data without further environment interactions. In offline RL, the distributional shift becomes the primary source of difficulty, which arises from the deviation of the target policy being optimized from the behavior policy used for data collection. This typically causes overestimation of action values, which poses severe problems for model-free algorithms that use bootstrapping. To mitigate the problem, prior offline RL algorithms often used sophisticated techniques that encourage underestimation of action values, which introduces an additional set of hyperparameters that need to be tuned properly. In this paper, we present an offline RL algorithm that prevents overestimation in a more principled way. Our algorithm, OptiDICE, directly estimates the stationary distribution corrections of the optimal policy and does not rely on policy-gradients, unlike previous offline RL algorithms. Using an extensive set of benchmark datasets for offline RL, we show that OptiDICE performs competitively with the state-of-the-art methods.