 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIceCache: Memory-efficient KV-cache Management for Long-Sequence LLMs
Apr 12, 2026Key-Value (KV) cache plays a crucial role in accelerating inference in large language models (LLMs) by storing intermediate attention states and avoiding redundant computation during autoregressive generation. However, its memory footprint scales linearly with sequence length, often leading to severe memory bottlenecks on resource-constrained hardware. Prior work has explored offloading KV cache to the CPU while retaining only a subset on the GPU, but these approaches often rely on imprecise token selection and suffer performance degradation in long-generation tasks such as chain-of-thought reasoning. In this paper, we propose a novel KV cache management strategy, IceCache, which integrates semantic token clustering with PagedAttention. By organizing semantically related tokens into contiguous memory regions managed by a hierarchical, dynamically updatable data structure, our method enables more efficient token selection and better utilization of memory bandwidth during CPU-GPU transfers. Experimental results on LongBench show that, with a 256-token budget, IceCache maintains 99% of the original accuracy achieved by the full KV cache model. Moreover, compared to other offloading-based methods, IceCache attains competitive or even superior latency and accuracy while using only 25% of the KV cache token budget, demonstrating its effectiveness in long-sequence scenarios. The code is available on our project website at https://yuzhenmao.github.io/IceCache/.
SEAnet: A Deep Learning Architecture for Data Series Similarity Search
Mar 02, 2026A key operation for massive data series collection analysis is similarity search. According to recent studies, SAX-based indexes offer state-of-the-art performance for similarity search tasks. However, their performance lags under high-frequency, weakly correlated, excessively noisy, or other dataset-specific properties. In this work, we propose Deep Embedding Approximation (DEA), a novel family of data series summarization techniques based on deep neural networks. Moreover, we describe SEAnet, a novel architecture especially designed for learning DEA, that introduces the Sum of Squares preservation property into the deep network design. We further enhance SEAnet with SEAtrans encoder. Finally, we propose novel sampling strategies, SEAsam and SEAsamE, that allow SEAnet to effectively train on massive datasets. Comprehensive experiments on 7 diverse synthetic and real datasets verify the advantages of DEA learned using SEAnet in providing high-quality data series summarizations and similarity search results.
* This paper was published in IEEE Transactions on Knowledge and Data Engineering (Volume: 35, Issue: 12, Page(s): 12972 - 12986, 01 December 2023). Date of Publication: 25 April 2023
Decoder-based Sense Knowledge Distillation
Feb 25, 2026Large language models (LLMs) learn contextual embeddings that capture rich semantic information, yet they often overlook structured lexical knowledge such as word senses and relationships. Prior work has shown that incorporating sense dictionaries can improve knowledge distillation for encoder models, but their application to decoder as generative models remains challenging. In this paper, we introduce Decoder-based Sense Knowledge Distillation (DSKD), a framework that integrates lexical resources into the training of decoder-style LLMs without requiring dictionary lookup at inference time. Extensive experiments on diverse benchmarks demonstrate that DSKD significantly enhances knowledge distillation performance for decoders, enabling generative models to inherit structured semantics while maintaining efficient training.
SEMixer: Semantics Enhanced MLP-Mixer for Multiscale Mixing and Long-term Time Series Forecasting
Feb 18, 2026Modeling multiscale patterns is crucial for long-term time series forecasting (TSF). However, redundancy and noise in time series, together with semantic gaps between non-adjacent scales, make the efficient alignment and integration of multi-scale temporal dependencies challenging. To address this, we propose SEMixer, a lightweight multiscale model designed for long-term TSF. SEMixer features two key components: a Random Attention Mechanism (RAM) and a Multiscale Progressive Mixing Chain (MPMC). RAM captures diverse time-patch interactions during training and aggregates them via dropout ensemble at inference, enhancing patch-level semantics and enabling MLP-Mixer to better model multi-scale dependencies. MPMC further stacks RAM and MLP-Mixer in a memory-efficient manner, achieving more effective temporal mixing. It addresses semantic gaps across scales and facilitates better multiscale modeling and forecasting performance. We not only validate the effectiveness of SEMixer on 10 public datasets, but also on the \textit{2025 CCF AlOps Challenge} based on 21GB real wireless network data, where SEMixer achieves third place. The code is available at the link https://github.com/Meteor-Stars/SEMixer.
ParisKV: Fast and Drift-Robust KV-Cache Retrieval for Long-Context LLMs
Feb 07, 2026KV-cache retrieval is essential for long-context LLM inference, yet existing methods struggle with distribution drift and high latency at scale. We introduce ParisKV, a drift-robust, GPU-native KV-cache retrieval framework based on collision-based candidate selection, followed by a quantized inner-product reranking estimator. For million-token contexts, ParisKV supports CPU-offloaded KV caches via Unified Virtual Addressing (UVA), enabling on-demand top-$k$ fetching with minimal overhead. ParisKV matches or outperforms full attention quality on long-input and long-generation benchmarks. It achieves state-of-the-art long-context decoding efficiency: it matches or exceeds full attention speed even at batch size 1 for long contexts, delivers up to 2.8$\times$ higher throughput within full attention's runnable range, and scales to million-token contexts where full attention runs out of memory. At million-token scale, ParisKV reduces decode latency by 17$\times$ and 44$\times$ compared to MagicPIG and PQCache, respectively, two state-of-the-art KV-cache Top-$k$ retrieval baselines.
A Lightweight Sparse Interaction Network for Time Series Forecasting
Feb 02, 2026Recent work shows that linear models can outperform several transformer models in long-term time-series forecasting (TSF). However, instead of explicitly performing temporal interaction through self-attention, linear models implicitly perform it based on stacked MLP structures, which may be insufficient in capturing the complex temporal dependencies and their performance still has potential for improvement. To this end, we propose a Lightweight Sparse Interaction Network (LSINet) for TSF task. Inspired by the sparsity of self-attention, we propose a Multihead Sparse Interaction Mechanism (MSIM). Different from self-attention, MSIM learns the important connections between time steps through sparsity-induced Bernoulli distribution to capture temporal dependencies for TSF. The sparsity is ensured by the proposed self-adaptive regularization loss. Moreover, we observe the shareability of temporal interactions and propose to perform Shared Interaction Learning (SIL) for MSIM to further enhance efficiency and improve convergence. LSINet is a linear model comprising only MLP structures with low overhead and equipped with explicit temporal interaction mechanisms. Extensive experiments on public datasets show that LSINet achieves both higher accuracy and better efficiency than advanced linear models and transformer models in TSF tasks. The code is available at the link https://github.com/Meteor-Stars/LSINet.
Multi-period Learning for Financial Time Series Forecasting
Nov 07, 2025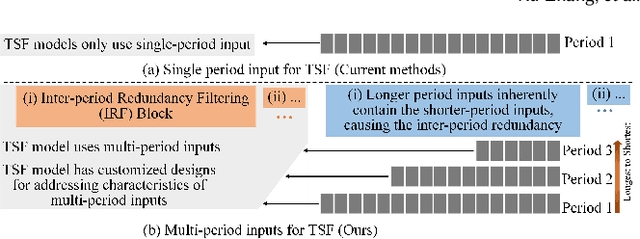
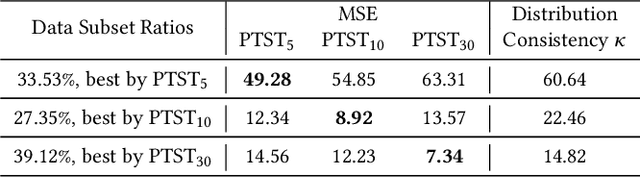
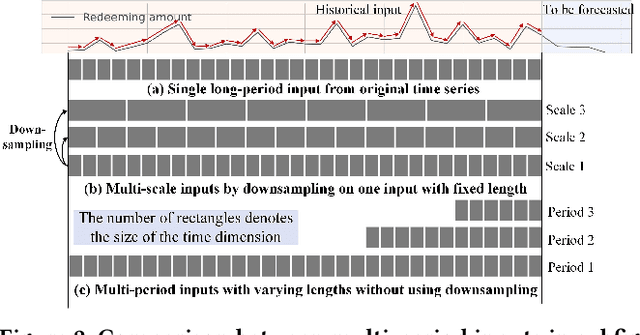
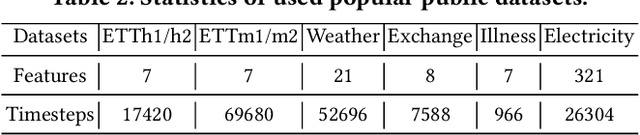
Time series forecasting is important in finance domain. Financial time series (TS) patterns are influenced by both short-term public opinions and medium-/long-term policy and market trends. Hence, processing multi-period inputs becomes crucial for accurate financial time series forecasting (TSF). However, current TSF models either use only single-period input, or lack customized designs for addressing multi-period characteristics. In this paper, we propose a Multi-period Learning Framework (MLF) to enhance financial TSF performance. MLF considers both TSF's accuracy and efficiency requirements. Specifically, we design three new modules to better integrate the multi-period inputs for improving accuracy: (i) Inter-period Redundancy Filtering (IRF), that removes the information redundancy between periods for accurate self-attention modeling, (ii) Learnable Weighted-average Integration (LWI), that effectively integrates multi-period forecasts, (iii) Multi-period self-Adaptive Patching (MAP), that mitigates the bias towards certain periods by setting the same number of patches across all periods. Furthermore, we propose a Patch Squeeze module to reduce the number of patches in self-attention modeling for maximized efficiency. MLF incorporates multiple inputs with varying lengths (periods) to achieve better accuracy and reduces the costs of selecting input lengths during training. The codes and datasets are available at https://github.com/Meteor-Stars/MLF.
Multi-Sense Embeddings for Language Models and Knowledge Distillation
Apr 08, 2025Transformer-based large language models (LLMs) rely on contextual embeddings which generate different (continuous) representations for the same token depending on its surrounding context. Nonetheless, words and tokens typically have a limited number of senses (or meanings). We propose multi-sense embeddings as a drop-in replacement for each token in order to capture the range of their uses in a language. To construct a sense embedding dictionary, we apply a clustering algorithm to embeddings generated by an LLM and consider the cluster centers as representative sense embeddings. In addition, we propose a novel knowledge distillation method that leverages the sense dictionary to learn a smaller student model that mimics the senses from the much larger base LLM model, offering significant space and inference time savings, while maintaining competitive performance. Via thorough experiments on various benchmarks, we showcase the effectiveness of our sense embeddings and knowledge distillation approach. We share our code at https://github.com/Qitong-Wang/SenseDict
Beyond Accuracy: On the Effects of Fine-tuning Towards Vision-Language Model's Prediction Rationality
Dec 17, 2024



Vision-Language Models (VLMs), such as CLIP, have already seen widespread applications. Researchers actively engage in further fine-tuning VLMs in safety-critical domains. In these domains, prediction rationality is crucial: the prediction should be correct and based on valid evidence. Yet, for VLMs, the impact of fine-tuning on prediction rationality is seldomly investigated. To study this problem, we proposed two new metrics called Prediction Trustworthiness and Inference Reliability. We conducted extensive experiments on various settings and observed some interesting phenomena. On the one hand, we found that the well-adopted fine-tuning methods led to more correct predictions based on invalid evidence. This potentially undermines the trustworthiness of correct predictions from fine-tuned VLMs. On the other hand, having identified valid evidence of target objects, fine-tuned VLMs were more likely to make correct predictions. Moreover, the findings are also consistent under distributional shifts and across various experimental settings. We hope our research offer fresh insights to VLM fine-tuning.
Enhancing Adaptive Deep Networks for Image Classification via Uncertainty-aware Decision Fusion
Aug 25, 2024



Handling varying computational resources is a critical issue in modern AI applications. Adaptive deep networks, featuring the dynamic employment of multiple classifier heads among different layers, have been proposed to address classification tasks under varying computing resources. Existing approaches typically utilize the last classifier supported by the available resources for inference, as they believe that the last classifier always performs better across all classes. However, our findings indicate that earlier classifier heads can outperform the last head for certain classes. Based on this observation, we introduce the Collaborative Decision Making (CDM) module, which fuses the multiple classifier heads to enhance the inference performance of adaptive deep networks. CDM incorporates an uncertainty-aware fusion method based on evidential deep learning (EDL), that utilizes the reliability (uncertainty values) from the first c-1 classifiers to improve the c-th classifier' accuracy. We also design a balance term that reduces fusion saturation and unfairness issues caused by EDL constraints to improve the fusion quality of CDM. Finally, a regularized training strategy that uses the last classifier to guide the learning process of early classifiers is proposed to further enhance the CDM module's effect, called the Guided Collaborative Decision Making (GCDM) framework. The experimental evaluation demonstrates the effectiveness of our approaches. Results on ImageNet datasets show CDM and GCDM obtain 0.4% to 2.8% accuracy improvement (under varying computing resources) on popular adaptive networks. The code is available at the link https://github.com/Meteor-Stars/GCDM_AdaptiveNet.