 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexus : An Agentic Framework for Time Series Forecasting
May 14, 2026Time series forecasting is not just numerical extrapolation, but often requires reasoning with unstructured contextual data such as news or events. While specialized Time Series Foundation Models (TSFMs) excel at forecasting based on numerical patterns, they remain unaware to real-world textual signals. Conversely, while LLMs are emerging as zero-shot forecasters, their performance remains uneven across domains and contextual grounding. To bridge this gap, we introduce Nexus, a multi-agent forecasting framework that decomposes prediction into specialized stages: isolating macro-level and micro-level temporal fluctuations, and integrating contextual information when available before synthesizing a final forecast. This decomposition enables Nexus to adapt from seasonal signals to volatile, event-driven information without relying on external statistical anchors or monolithic prompting. We show that current-generation LLMs possess substantially stronger intrinsic forecasting ability than previously recognized, depending critically on how numerical and contextual reasoning are organized. Evaluated on data strictly succeeding LLM knowledge cutoffs spanning Zillow real estate metrics and volatile stock market equities, Nexus consistently matches or outperforms state-of-the-art TSFMs and strong LLM baselines. Beyond numerical accuracy, Nexus produces high-quality reasoning traces that explicitly show the fundamental drivers behind each forecast. Our results establish that real-world forecasting is an agentic reasoning problem extending well beyond only sequence modeling.
RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards
May 11, 2026Training deep research agents, namely systems that plan, search, evaluate evidence, and synthesize long-form reports, pushes reinforcement learning beyond the regime of verifiable rewards. Their outputs lack ground-truth answers, their trajectories span many tool-augmented decisions, and standard post-training offers little mechanism for turning past attempts into reusable experience. In this work, we argue that rubrics should serve not merely as final-answer evaluators, but as the shared interface that structures policy execution, judge feedback, and agent memory. Based on this view, we introduce RubricEM, a rubric-guided reinforcement learning framework that combines stagewise policy decomposition with reflection-based meta-policy evolution. RubricEM first makes research trajectories stage-aware by conditioning planning, evidence gathering, review, and synthesis on self-generated rubrics. It then assigns credit with Stage-Structured GRPO, which uses stagewise rubric judgments to provide denser semantic feedback for long-horizon optimization. In parallel, RubricEM trains a shared-backbone reflection meta-policy that distills judged trajectories into reusable rubric-grounded guidance for future attempts. The resulting RubricEM-8B achieves strong performance across four long-form research benchmarks, outperforming comparable open models and approaching proprietary deep-research systems. Beyond final performance, we perform thorough analyses to understand the key ingredients of RubricEM.
SkillOS: Learning Skill Curation for Self-Evolving Agents
May 07, 2026LLM-based agents are increasingly deployed to handle streaming tasks, yet they often remain one-off problem solvers that fail to learn from past interactions. Reusable skills distilled from experience provide a natural substrate for self-evolution, where high-quality skill curation serves as the key bottleneck. Existing approaches either rely on manual skill curation, prescribe heuristic skill operations, or train for short-horizon skill operations. However, they still struggle to learn complex long-term curation policies from indirect and delayed feedback. To tackle this challenge, we propose SkillOS, an experience-driven RL training recipe for learning skill curation in self-evolving agents. SkillOS pairs a frozen agent executor that retrieves and applies skills with a trainable skill curator that updates an external SkillRepo from accumulated experience. To provide learning signals for curation, we design composite rewards and train on grouped task streams based on skill-relevant task dependencies, where earlier trajectories update the SkillRepo, and later related tasks evaluate these updates. Across multi-turn agentic tasks and single-turn reasoning tasks, SkillOS consistently outperforms memory-free and strong memory-based baselines in both effectiveness and efficiency, with the learned skill curator generalizing across different executor backbones and task domains. Further analyses show that the learned curator produces more targeted skill use, while the skills in SkillRepo evolve into more richly structured Markdown files that encode higher-level meta-skills over time.
VSAS-BENCH: Real-Time Evaluation of Visual Streaming Assistant Models
Apr 08, 2026Streaming vision-language models (VLMs) continuously generate responses given an instruction prompt and an online stream of input frames. This is a core mechanism for real-time visual assistants. Existing VLM frameworks predominantly assess models in offline settings. In contrast, the performance of a streaming VLM depends on additional metrics beyond pure video understanding, including proactiveness, which reflects the timeliness of the model's responses, and consistency, which captures the robustness of its responses over time. To address this limitation, we propose VSAS-Bench, a new framework and benchmark for Visual Streaming Assistants. In contrast to prior benchmarks that primarily employ single-turn question answering on video inputs, VSAS-Bench features temporally dense annotations with over 18,000 annotations across diverse input domains and task types. We introduce standardized synchronous and asynchronous evaluation protocols, along with metrics that isolate and measure distinct capabilities of streaming VLMs. Using this framework, we conduct large-scale evaluations of recent video and streaming VLMs, analyzing the accuracy-latency trade-off under key design factors such as memory buffer length, memory access policy, and input resolution, yielding several practical insights. Finally, we show empirically that conventional VLMs can be adapted to streaming settings without additional training, and demonstrate that these adapted models outperform recent streaming VLMs. For example, Qwen3-VL-4B surpasses Dispider, the best streaming VLM on our benchmark, by 3% under the asynchronous protocol. The benchmark and code will be available at https://github.com/apple/ml-vsas-bench.
TFRBench: A Reasoning Benchmark for Evaluating Forecasting Systems
Apr 07, 2026We introduce TFRBench, the first benchmark designed to evaluate the reasoning capabilities of forecasting systems. Traditionally, time-series forecasting has been evaluated solely on numerical accuracy, treating foundation models as ``black boxes.'' Unlike existing benchmarks, TFRBench provides a protocol for evaluating the reasoning generated by forecasting systems--specifically their analysis of cross-channel dependencies, trends, and external events. To enable this, we propose a systematic multi-agent framework that utilizes an iterative verification loop to synthesize numerically grounded reasoning traces. Spanning ten datasets across five domains, our evaluation confirms that this reasoning is causally effective; useful for evaluation; and prompting LLMs with our generated traces significantly improves forecasting accuracy compared to direct numerical prediction (e.g., avg. $\sim40.2\%\to56.6\%)$, validating the quality of our reasoning. Conversely, benchmarking experiments reveal that off-the-shelf LLMs consistently struggle with both reasoning (lower LLM-as-a-Judge scores) and numerical forecasting, frequently failing to capture domain-specific dynamics. TFRBench thus establishes a new standard for interpretable, reasoning-based evaluation in time-series forecasting. Our benchmark is available at: https://tfrbench.github.io
TrajTok: Learning Trajectory Tokens enables better Video Understanding
Feb 26, 2026Tokenization in video models, typically through patchification, generates an excessive and redundant number of tokens. This severely limits video efficiency and scalability. While recent trajectory-based tokenizers offer a promising solution by decoupling video duration from token count, they rely on complex external segmentation and tracking pipelines that are slow and task-agnostic. We propose TrajTok, an end-to-end video tokenizer module that is fully integrated and co-trained with video models for a downstream objective, dynamically adapting its token granularity to semantic complexity, independent of video duration. TrajTok contains a unified segmenter that performs implicit clustering over pixels in both space and time to directly produce object trajectories in a single forward pass. By prioritizing downstream adaptability over pixel-perfect segmentation fidelity, TrajTok is lightweight and efficient, yet empirically improves video understanding performance. With TrajTok, we implement a video CLIP model trained from scratch (TrajViT2). It achieves the best accuracy at scale across both classification and retrieval benchmarks, while maintaining efficiency comparable to the best token-merging methods. TrajTok also proves to be a versatile component beyond its role as a tokenizer. We show that it can be seamlessly integrated as either a probing head for pretrained visual features (TrajAdapter) or an alignment connector in vision-language models (TrajVLM) with especially strong performance in long-video reasoning.
Beyond a Single Extractor: Re-thinking HTML-to-Text Extraction for LLM Pretraining
Feb 23, 2026One of the first pre-processing steps for constructing web-scale LLM pretraining datasets involves extracting text from HTML. Despite the immense diversity of web content, existing open-source datasets predominantly apply a single fixed extractor to all webpages. In this work, we investigate whether this practice leads to suboptimal coverage and utilization of Internet data. We first show that while different extractors may lead to similar model performance on standard language understanding tasks, the pages surviving a fixed filtering pipeline can differ substantially. This suggests a simple intervention: by taking a Union over different extractors, we can increase the token yield of DCLM-Baseline by up to 71% while maintaining benchmark performance. We further show that for structured content such as tables and code blocks, extractor choice can significantly impact downstream task performance, with differences of up to 10 percentage points (p.p.) on WikiTQ and 3 p.p. on HumanEval.
AMUSE: Audio-Visual Benchmark and Alignment Framework for Agentic Multi-Speaker Understanding
Dec 18, 2025

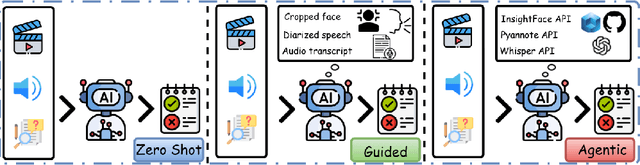
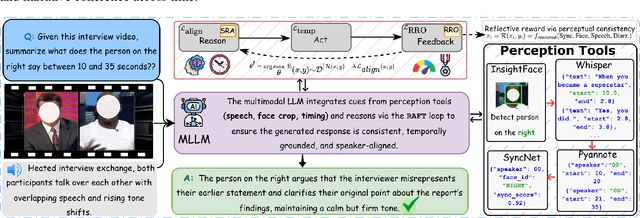
Recent multimodal large language models (MLLMs) such as GPT-4o and Qwen3-Omni show strong perception but struggle in multi-speaker, dialogue-centric settings that demand agentic reasoning tracking who speaks, maintaining roles, and grounding events across time. These scenarios are central to multimodal audio-video understanding, where models must jointly reason over audio and visual streams in applications such as conversational video assistants and meeting analytics. We introduce AMUSE, a benchmark designed around tasks that are inherently agentic, requiring models to decompose complex audio-visual interactions into planning, grounding, and reflection steps. It evaluates MLLMs across three modes zero-shot, guided, and agentic and six task families, including spatio-temporal speaker grounding and multimodal dialogue summarization. Across all modes, current models exhibit weak multi-speaker reasoning and inconsistent behavior under both non-agentic and agentic evaluation. Motivated by the inherently agentic nature of these tasks and recent advances in LLM agents, we propose RAFT, a data-efficient agentic alignment framework that integrates reward optimization with intrinsic multimodal self-evaluation as reward and selective parameter adaptation for data and parameter efficient updates. Using RAFT, we achieve up to 39.52\% relative improvement in accuracy on our benchmark. Together, AMUSE and RAFT provide a practical platform for examining agentic reasoning in multimodal models and improving their capabilities.
The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains
Jul 08, 2025Improvements in language models are often driven by improving the quality of the data we train them on, which can be limiting when strong supervision is scarce. In this work, we show that paired preference data consisting of individually weak data points can enable gains beyond the strength of each individual data point. We formulate the delta learning hypothesis to explain this phenomenon, positing that the relative quality delta between points suffices to drive learning via preference tuning--even when supervised finetuning on the weak data hurts. We validate our hypothesis in controlled experiments and at scale, where we post-train 8B models on preference data generated by pairing a small 3B model's responses with outputs from an even smaller 1.5B model to create a meaningful delta. Strikingly, on a standard 11-benchmark evaluation suite (MATH, MMLU, etc.), our simple recipe matches the performance of Tulu 3, a state-of-the-art open model tuned from the same base model while relying on much stronger supervisors (e.g., GPT-4o). Thus, delta learning enables simpler and cheaper open recipes for state-of-the-art post-training. To better understand delta learning, we prove in logistic regression that the performance gap between two weak teacher models provides useful signal for improving a stronger student. Overall, our work shows that models can learn surprisingly well from paired data that might typically be considered weak.
FocalLens: Instruction Tuning Enables Zero-Shot Conditional Image Representations
Apr 11, 2025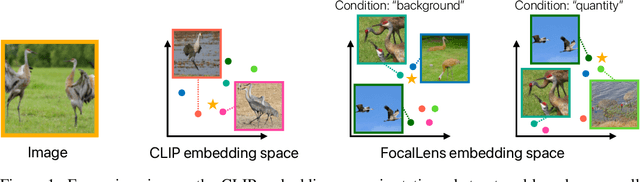
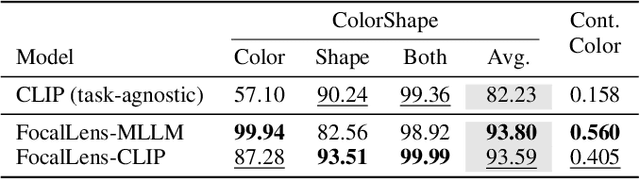
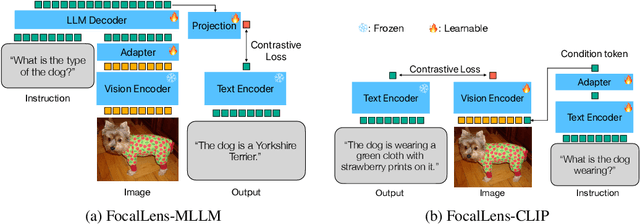
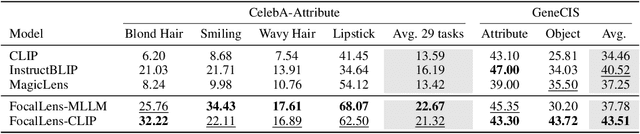
Visual understanding is inherently contextual -- what we focus on in an image depends on the task at hand. For instance, given an image of a person holding a bouquet of flowers, we may focus on either the person such as their clothing, or the type of flowers, depending on the context of interest. Yet, most existing image encoding paradigms represent an image as a fixed, generic feature vector, overlooking the potential needs of prioritizing varying visual information for different downstream use cases. In this work, we introduce FocalLens, a conditional visual encoding method that produces different representations for the same image based on the context of interest, expressed flexibly through natural language. We leverage vision instruction tuning data and contrastively finetune a pretrained vision encoder to take natural language instructions as additional inputs for producing conditional image representations. Extensive experiments validate that conditional image representation from FocalLens better pronounce the visual features of interest compared to generic features produced by standard vision encoders like CLIP. In addition, we show FocalLens further leads to performance improvements on a range of downstream tasks including image-image retrieval, image classification, and image-text retrieval, with an average gain of 5 and 10 points on the challenging SugarCrepe and MMVP-VLM benchmarks, respectively.