 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTELLAR: Scaling 3D Perception Large Models for Autonomous Driving
May 19, 2026Model scaling has demonstrated remarkable success through large-scale training on diverse datasets. It remains an open question whether the same paradigm would apply to autonomous driving perception systems due to unique challenges, such as fusing heterogeneous sensor data and the need for sophisticated 3D spatial understanding. To bridge this gap, we present a comprehensive study on systematically analyzing the impact of scale on these systems. We develop our STELLAR model based on Sparse Window Transformer, by extending the input modalities to include LiDAR, radar, camera, and map prior. We train the model on a large-scale dataset of 50 million driving examples with up to 500 million parameters. Our large-scale experiments reveal empirical scaling trends that connect model performance to model size, data, and compute. The resulting model establishes a new state-of-the-art on the Waymo Open Dataset challenge, outperforming prior arts by a large margin. Our work demonstrates that large-scale training is a highly promising path for advancing the capabilities of perception models for autonomous driving.
Error Estimation for Random Fourier Features
Feb 22, 2023



Random Fourier Features (RFF) is among the most popular and broadly applicable approaches for scaling up kernel methods. In essence, RFF allows the user to avoid costly computations on a large kernel matrix via a fast randomized approximation. However, a pervasive difficulty in applying RFF is that the user does not know the actual error of the approximation, or how this error will propagate into downstream learning tasks. Up to now, the RFF literature has primarily dealt with these uncertainties using theoretical error bounds, but from a user's standpoint, such results are typically impractical -- either because they are highly conservative or involve unknown quantities. To tackle these general issues in a data-driven way, this paper develops a bootstrap approach to numerically estimate the errors of RFF approximations. Three key advantages of this approach are: (1) The error estimates are specific to the problem at hand, avoiding the pessimism of worst-case bounds. (2) The approach is flexible with respect to different uses of RFF, and can even estimate errors in downstream learning tasks. (3) The approach enables adaptive computation, so that the user can quickly inspect the error of a rough initial kernel approximation and then predict how much extra work is needed. Lastly, in exchange for all of these benefits, the error estimates can be obtained at a modest computational cost.
Deep Learning for Functional Data Analysis with Adaptive Basis Layers
Jun 19, 2021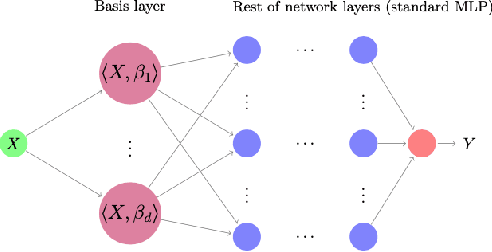
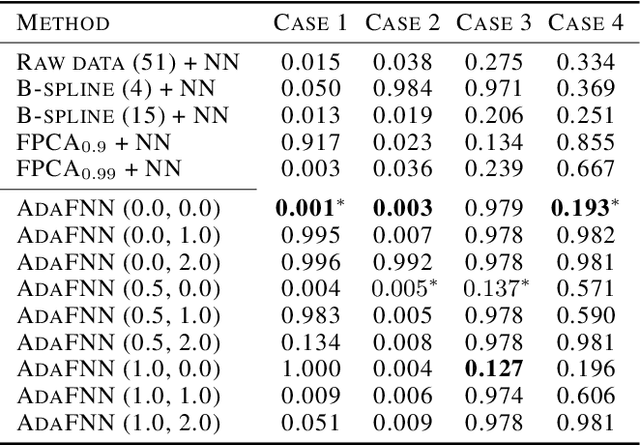
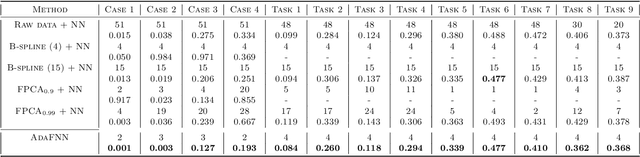
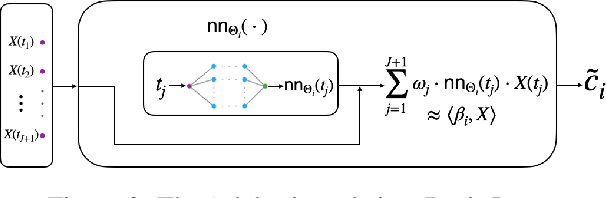
Despite their widespread success, the application of deep neural networks to functional data remains scarce today. The infinite dimensionality of functional data means standard learning algorithms can be applied only after appropriate dimension reduction, typically achieved via basis expansions. Currently, these bases are chosen a priori without the information for the task at hand and thus may not be effective for the designated task. We instead propose to adaptively learn these bases in an end-to-end fashion. We introduce neural networks that employ a new Basis Layer whose hidden units are each basis functions themselves implemented as a micro neural network. Our architecture learns to apply parsimonious dimension reduction to functional inputs that focuses only on information relevant to the target rather than irrelevant variation in the input function. Across numerous classification/regression tasks with functional data, our method empirically outperforms other types of neural networks, and we prove that our approach is statistically consistent with low generalization error. Code is available at: \url{https://github.com/jwyyy/AdaFNN}.