 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASE: Token Awareness and Structured Evaluation for Multilingual Language Models
Aug 07, 2025While large language models (LLMs) have demonstrated remarkable performance on high-level semantic tasks, they often struggle with fine-grained, token-level understanding and structural reasoning--capabilities that are essential for applications requiring precision and control. We introduce TASE, a comprehensive benchmark designed to evaluate LLMs' ability to perceive and reason about token-level information across languages. TASE covers 10 tasks under two core categories: token awareness and structural understanding, spanning Chinese, English, and Korean, with a 35,927-instance evaluation set and a scalable synthetic data generation pipeline for training. Tasks include character counting, token alignment, syntactic structure parsing, and length constraint satisfaction. We evaluate over 30 leading commercial and open-source LLMs, including O3, Claude 4, Gemini 2.5 Pro, and DeepSeek-R1, and train a custom Qwen2.5-14B model using the GRPO training method. Results show that human performance significantly outpaces current LLMs, revealing persistent weaknesses in token-level reasoning. TASE sheds light on these limitations and provides a new diagnostic lens for future improvements in low-level language understanding and cross-lingual generalization. Our code and dataset are publicly available at https://github.com/cyzcz/Tase .
AsFT: Anchoring Safety During LLM Fine-Tuning Within Narrow Safety Basin
Jun 11, 2025



Large language models (LLMs) are vulnerable to safety risks during fine-tuning, where small amounts of malicious or harmless data can compromise safeguards. In this paper, building on the concept of alignment direction -- defined by the weight difference between aligned and unaligned models -- we observe that perturbations along this direction preserve model safety. In contrast, perturbations along directions orthogonal to this alignment are strongly linked to harmful direction perturbations, rapidly degrading safety and framing the parameter space as a narrow safety basin. Based on this insight, we propose a methodology for safety fine-tuning called AsFT (Anchoring Safety in Fine-Tuning), which integrates a regularization term into the training objective. This term uses the alignment direction as an anchor to suppress updates in harmful directions, ensuring that fine-tuning is constrained within the narrow safety basin. Extensive experiments on multiple datasets show that AsFT outperforms Safe LoRA, reducing harmful behavior by 7.60 percent, improving model performance by 3.44 percent, and maintaining robust performance across various experimental settings. Code is available at https://github.com/PKU-YuanGroup/AsFT
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline
Jun 05, 2025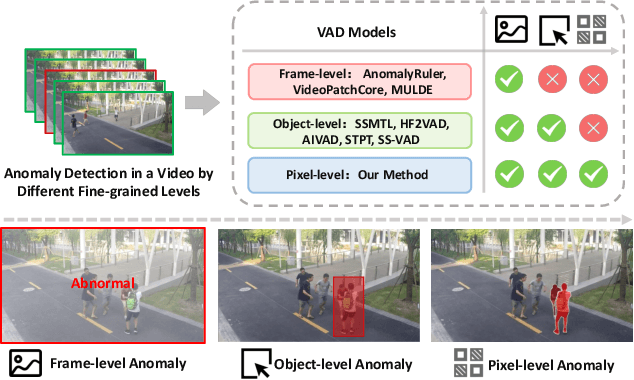
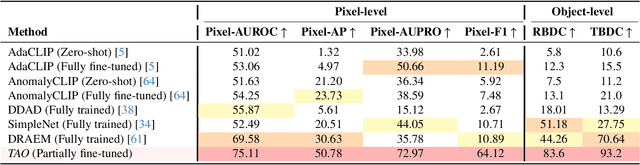
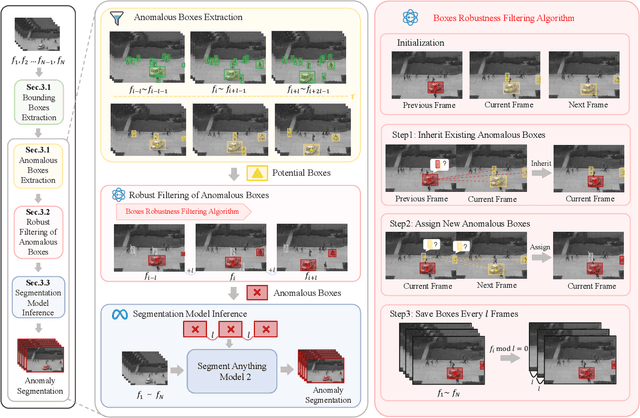
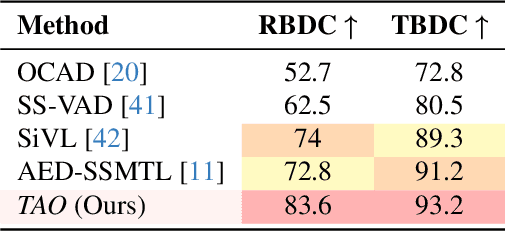
Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving, where timely detection of unexpected activities is essential. Although existing methods have primarily focused on detecting anomalous objects in videos -- either by identifying anomalous frames or objects -- they often neglect finer-grained analysis, such as anomalous pixels, which limits their ability to capture a broader range of anomalies. To address this challenge, we propose a new framework called Track Any Anomalous Object (TAO), which introduces a granular video anomaly detection pipeline that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework. Unlike methods that assign anomaly scores to every pixel, our approach transforms the problem into pixel-level tracking of anomalous objects. By linking anomaly scores to downstream tasks such as segmentation and tracking, our method removes the need for threshold tuning and achieves more precise anomaly localization in long and complex video sequences. Experiments demonstrate that TAO sets new benchmarks in accuracy and robustness. Project page available online.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025



Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
Cross-Lingual Pitfalls: Automatic Probing Cross-Lingual Weakness of Multilingual Large Language Models
May 24, 2025Large Language Models (LLMs) have achieved remarkable success in Natural Language Processing (NLP), yet their cross-lingual performance consistency remains a significant challenge. This paper introduces a novel methodology for efficiently identifying inherent cross-lingual weaknesses in LLMs. Our approach leverages beam search and LLM-based simulation to generate bilingual question pairs that expose performance discrepancies between English and target languages. We construct a new dataset of over 6,000 bilingual pairs across 16 languages using this methodology, demonstrating its effectiveness in revealing weaknesses even in state-of-the-art models. The extensive experiments demonstrate that our method precisely and cost-effectively pinpoints cross-lingual weaknesses, consistently revealing over 50\% accuracy drops in target languages across a wide range of models. Moreover, further experiments investigate the relationship between linguistic similarity and cross-lingual weaknesses, revealing that linguistically related languages share similar performance patterns and benefit from targeted post-training. Code is available at https://github.com/xzx34/Cross-Lingual-Pitfalls.
PCMamba: Physics-Informed Cross-Modal State Space Model for Dual-Camera Compressive Hyperspectral Imaging
May 22, 2025



Panchromatic (PAN) -assisted Dual-Camera Compressive Hyperspectral Imaging (DCCHI) is a key technology in snapshot hyperspectral imaging. Existing research primarily focuses on exploring spectral information from 2D compressive measurements and spatial information from PAN images in an explicit manner, leading to a bottleneck in HSI reconstruction. Various physical factors, such as temperature, emissivity, and multiple reflections between objects, play a critical role in the process of a sensor acquiring hyperspectral thermal signals. Inspired by this, we attempt to investigate the interrelationships between physical properties to provide deeper theoretical insights for HSI reconstruction. In this paper, we propose a Physics-Informed Cross-Modal State Space Model Network (PCMamba) for DCCHI, which incorporates the forward physical imaging process of HSI into the linear complexity of Mamba to facilitate lightweight and high-quality HSI reconstruction. Specifically, we analyze the imaging process of hyperspectral thermal signals to enable the network to disentangle the three key physical properties-temperature, emissivity, and texture. By fully exploiting the potential information embedded in 2D measurements and PAN images, the HSIs are reconstructed through a physics-driven synthesis process. Furthermore, we design a Cross-Modal Scanning Mamba Block (CSMB) that introduces inter-modal pixel-wise interaction with positional inductive bias by cross-scanning the backbone features and PAN features. Extensive experiments conducted on both real and simulated datasets demonstrate that our method significantly outperforms SOTA methods in both quantitative and qualitative metrics.
AdaReasoner: Adaptive Reasoning Enables More Flexible Thinking
May 22, 2025LLMs often need effective configurations, like temperature and reasoning steps, to handle tasks requiring sophisticated reasoning and problem-solving, ranging from joke generation to mathematical reasoning. Existing prompting approaches usually adopt general-purpose, fixed configurations that work 'well enough' across tasks but seldom achieve task-specific optimality. To address this gap, we introduce AdaReasoner, an LLM-agnostic plugin designed for any LLM to automate adaptive reasoning configurations for tasks requiring different types of thinking. AdaReasoner is trained using a reinforcement learning (RL) framework, combining a factorized action space with a targeted exploration strategy, along with a pretrained reward model to optimize the policy model for reasoning configurations with only a few-shot guide. AdaReasoner is backed by theoretical guarantees and experiments of fast convergence and a sublinear policy gap. Across six different LLMs and a variety of reasoning tasks, it consistently outperforms standard baselines, preserves out-of-distribution robustness, and yield gains on knowledge-intensive tasks through tailored prompts.
FRN: Fractal-Based Recursive Spectral Reconstruction Network
May 21, 2025



Generating hyperspectral images (HSIs) from RGB images through spectral reconstruction can significantly reduce the cost of HSI acquisition. In this paper, we propose a Fractal-Based Recursive Spectral Reconstruction Network (FRN), which differs from existing paradigms that attempt to directly integrate the full-spectrum information from the R, G, and B channels in a one-shot manner. Instead, it treats spectral reconstruction as a progressive process, predicting from broad to narrow bands or employing a coarse-to-fine approach for predicting the next wavelength. Inspired by fractals in mathematics, FRN establishes a novel spectral reconstruction paradigm by recursively invoking an atomic reconstruction module. In each invocation, only the spectral information from neighboring bands is used to provide clues for the generation of the image at the next wavelength, which follows the low-rank property of spectral data. Moreover, we design a band-aware state space model that employs a pixel-differentiated scanning strategy at different stages of the generation process, further suppressing interference from low-correlation regions caused by reflectance differences. Through extensive experimentation across different datasets, FRN achieves superior reconstruction performance compared to state-of-the-art methods in both quantitative and qualitative evaluations.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
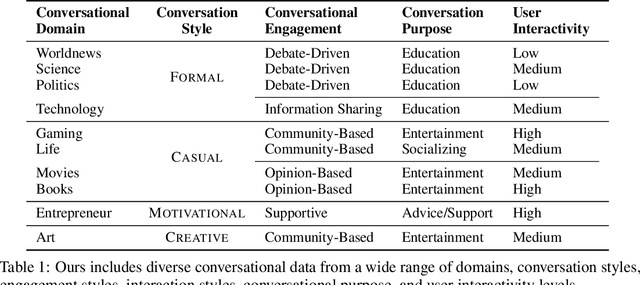


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.