 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHATS: Hardness-Aware Trajectory Synthesis for GUI Agents
Mar 12, 2026Graphical user interface (GUI) agents powered by large vision-language models (VLMs) have shown remarkable potential in automating digital tasks, highlighting the need for high-quality trajectory data to support effective agent training. Yet existing trajectory synthesis pipelines often yield agents that fail to generalize beyond simple interactions. We identify this limitation as stemming from the neglect of semantically ambiguous actions, whose meanings are context-dependent, sequentially dependent, or visually ambiguous. Such actions are crucial for real-world robustness but are under-represented and poorly processed in current datasets, leading to semantic misalignment between task instructions and execution. To address these issues, we propose HATS, a Hardness-Aware Trajectory Synthesis framework designed to mitigate the impact of semantic ambiguity. We define hardness as the degree of semantic ambiguity associated with an action and develop two complementary modules: (1) hardness-driven exploration, which guides data collection toward ambiguous yet informative interactions, and (2) alignment-guided refinement, which iteratively validates and repairs instruction-execution alignment. The two modules operate in a closed loop: exploration supplies refinement with challenging trajectories, while refinement feedback updates the hardness signal to guide future exploration. Extensive experiments show that agents trained with HATS consistently outperform state-of-the-art baselines across benchmark GUI environments.
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025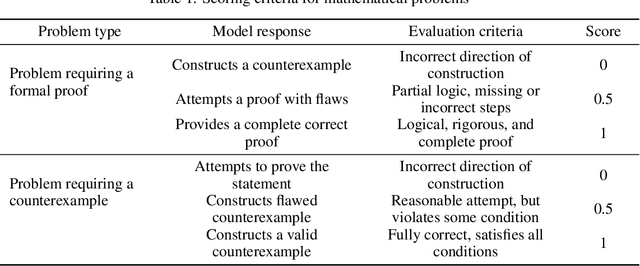
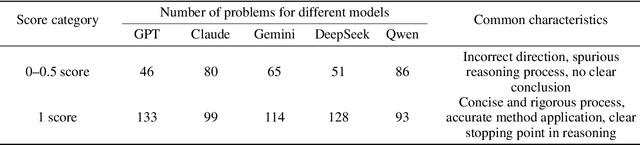
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
DeepOHeat-v1: Efficient Operator Learning for Fast and Trustworthy Thermal Simulation and Optimization in 3D-IC Design
Apr 04, 2025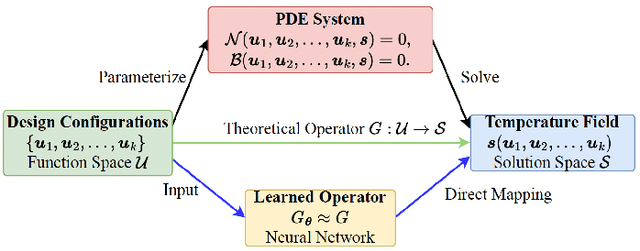

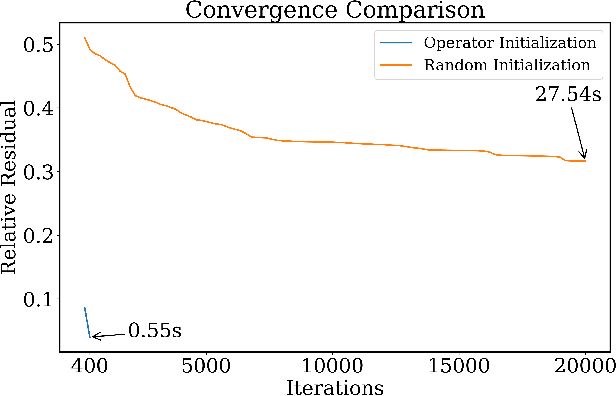

Thermal analysis is crucial in three-dimensional integrated circuit (3D-IC) design due to increased power density and complex heat dissipation paths. Although operator learning frameworks such as DeepOHeat have demonstrated promising preliminary results in accelerating thermal simulation, they face critical limitations in prediction capability for multi-scale thermal patterns, training efficiency, and trustworthiness of results during design optimization. This paper presents DeepOHeat-v1, an enhanced physics-informed operator learning framework that addresses these challenges through three key innovations. First, we integrate Kolmogorov-Arnold Networks with learnable activation functions as trunk networks, enabling an adaptive representation of multi-scale thermal patterns. This approach achieves a $1.25\times$ and $6.29\times$ reduction in error in two representative test cases. Second, we introduce a separable training method that decomposes the basis function along the coordinate axes, achieving $62\times$ training speedup and $31\times$ GPU memory reduction in our baseline case, and enabling thermal analysis at resolutions previously infeasible due to GPU memory constraints. Third, we propose a confidence score to evaluate the trustworthiness of the predicted results, and further develop a hybrid optimization workflow that combines operator learning with finite difference (FD) using Generalized Minimal Residual (GMRES) method for incremental solution refinement, enabling efficient and trustworthy thermal optimization. Experimental results demonstrate that DeepOHeat-v1 achieves accuracy comparable to optimization using high-fidelity finite difference solvers, while speeding up the entire optimization process by $70.6\times$ in our test cases, effectively minimizing the peak temperature through optimal placement of heat-generating components.
TransMamba: Flexibly Switching between Transformer and Mamba
Mar 31, 2025Transformers are the cornerstone of modern large language models, but their quadratic computational complexity limits efficiency in long-sequence processing. Recent advancements in Mamba, a state space model (SSM) with linear complexity, offer promising efficiency gains but suffer from unstable contextual learning and multitask generalization. This paper proposes TransMamba, a novel framework that unifies Transformer and Mamba through shared parameter matrices (e.g., QKV and CBx), and thus could dynamically switch between attention and SSM mechanisms at different token lengths and layers. We design the Memory converter to bridge Transformer and Mamba by converting attention outputs into SSM-compatible states, ensuring seamless information flow at TransPoints where the transformation happens. The TransPoint scheduling is also thoroughly explored for further improvements. We conducted extensive experiments demonstrating that TransMamba achieves superior training efficiency and performance compared to baselines, and validated the deeper consistency between Transformer and Mamba paradigms, offering a scalable solution for next-generation sequence modeling.
Scaling Laws for Floating Point Quantization Training
Jan 05, 2025



Low-precision training is considered an effective strategy for reducing both training and downstream inference costs. Previous scaling laws for precision mainly focus on integer quantization, which pay less attention to the constituents in floating-point quantization and thus cannot well fit the LLM losses in this scenario. In contrast, while floating-point quantization training is more commonly implemented in production, the research on it has been relatively superficial. In this paper, we thoroughly explore the effects of floating-point quantization targets, exponent bits, mantissa bits, and the calculation granularity of the scaling factor in floating-point quantization training performance of LLM models. While presenting an accurate floating-point quantization unified scaling law, we also provide valuable suggestions for the community: (1) Exponent bits contribute slightly more to the model performance than mantissa bits. We provide the optimal exponent-mantissa bit ratio for different bit numbers, which is available for future reference by hardware manufacturers; (2) We discover the formation of the critical data size in low-precision LLM training. Too much training data exceeding the critical data size will inversely bring in degradation of LLM performance; (3) The optimal floating-point quantization precision is directly proportional to the computational power, but within a wide computational power range, we estimate that the best cost-performance precision lies between 4-8 bits.
Continuous Speech Tokenizer in Text To Speech
Oct 22, 2024The fusion of speech and language in the era of large language models has garnered significant attention. Discrete speech token is often utilized in text-to-speech tasks for speech compression and portability, which is convenient for joint training with text and have good compression efficiency. However, we found that the discrete speech tokenizer still suffers from information loss. Therefore, we propose a simple yet effective continuous speech tokenizer and a text-to-speech model based on continuous speech tokens. Our results show that the speech language model based on the continuous speech tokenizer has better continuity and higher estimated Mean Opinion Scores (MoS). This enhancement is attributed to better information preservation rate of the continuous speech tokenizer across both low and high frequencies in the frequency domain.
Alignment Between the Decision-Making Logic of LLMs and Human Cognition: A Case Study on Legal LLMs
Oct 06, 2024



This paper presents a method to evaluate the alignment between the decision-making logic of Large Language Models (LLMs) and human cognition in a case study on legal LLMs. Unlike traditional evaluations on language generation results, we propose to evaluate the correctness of the detailed decision-making logic of an LLM behind its seemingly correct outputs, which represents the core challenge for an LLM to earn human trust. To this end, we quantify the interactions encoded by the LLM as primitive decision-making logic, because recent theoretical achievements have proven several mathematical guarantees of the faithfulness of the interaction-based explanation. We design a set of metrics to evaluate the detailed decision-making logic of LLMs. Experiments show that even when the language generation results appear correct, a significant portion of the internal inference logic contains notable issues.
Direct Preference Knowledge Distillation for Large Language Models
Jun 28, 2024



In the field of large language models (LLMs), Knowledge Distillation (KD) is a critical technique for transferring capabilities from teacher models to student models. However, existing KD methods face limitations and challenges in distillation of LLMs, including efficiency and insufficient measurement capabilities of traditional KL divergence. It is shown that LLMs can serve as an implicit reward function, which we define as a supplement to KL divergence. In this work, we propose Direct Preference Knowledge Distillation (DPKD) for LLMs. DPKD utilizes distribution divergence to represent the preference loss and implicit reward function. We re-formulate KD of LLMs into two stages: first optimizing and objective consisting of implicit reward and reverse KL divergence and then improving the preference probability of teacher outputs over student outputs. We conducted experiments and analysis on various datasets with LLM parameters ranging from 120M to 13B and demonstrate the broad applicability and effectiveness of our DPKD approach. Meanwhile, we prove the value and effectiveness of the introduced implicit reward and output preference in KD through experiments and theoretical analysis. The DPKD method outperforms the baseline method in both output response precision and exact match percentage. Code and data are available at https://aka.ms/dpkd.
From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding
Apr 04, 2023



Action understanding matters and attracts attention. It can be formed as the mapping from the action physical space to the semantic space. Typically, researchers built action datasets according to idiosyncratic choices to define classes and push the envelope of benchmarks respectively. Thus, datasets are incompatible with each other like "Isolated Islands" due to semantic gaps and various class granularities, e.g., do housework in dataset A and wash plate in dataset B. We argue that a more principled semantic space is an urgent need to concentrate the community efforts and enable us to use all datasets together to pursue generalizable action learning. To this end, we design a Poincare action semantic space given verb taxonomy hierarchy and covering massive actions. By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i.e., bridging "isolated islands" into a "Pangea". Accordingly, we propose a bidirectional mapping model between physical and semantic space to fully use Pangea. In extensive experiments, our system shows significant superiority, especially in transfer learning. Code and data will be made publicly available.
DeepOHeat: Operator Learning-based Ultra-fast Thermal Simulation in 3D-IC Design
Feb 25, 2023



Thermal issue is a major concern in 3D integrated circuit (IC) design. Thermal optimization of 3D IC often requires massive expensive PDE simulations. Neural network-based thermal prediction models can perform real-time prediction for many unseen new designs. However, existing works either solve 2D temperature fields only or do not generalize well to new designs with unseen design configurations (e.g., heat sources and boundary conditions). In this paper, for the first time, we propose DeepOHeat, a physics-aware operator learning framework to predict the temperature field of a family of heat equations with multiple parametric or non-parametric design configurations. This framework learns a functional map from the function space of multiple key PDE configurations (e.g., boundary conditions, power maps, heat transfer coefficients) to the function space of the corresponding solution (i.e., temperature fields), enabling fast thermal analysis and optimization by changing key design configurations (rather than just some parameters). We test DeepOHeat on some industrial design cases and compare it against Celsius 3D from Cadence Design Systems. Our results show that, for the unseen testing cases, a well-trained DeepOHeat can produce accurate results with $1000\times$ to $300000\times$ speedup.