 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepOHeat-v1: Efficient Operator Learning for Fast and Trustworthy Thermal Simulation and Optimization in 3D-IC Design
Apr 04, 2025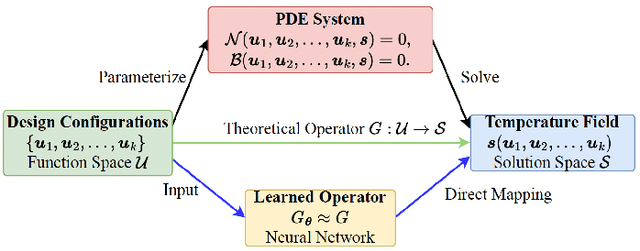

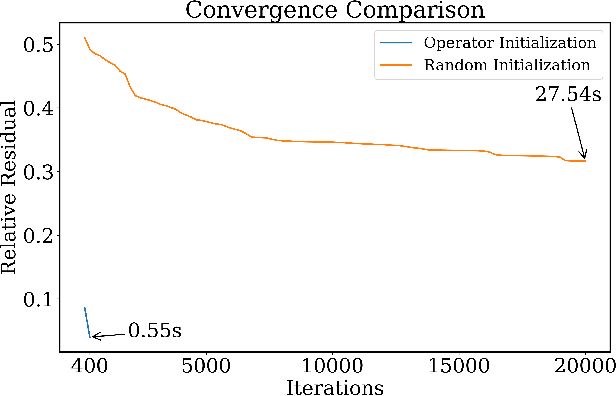

Thermal analysis is crucial in three-dimensional integrated circuit (3D-IC) design due to increased power density and complex heat dissipation paths. Although operator learning frameworks such as DeepOHeat have demonstrated promising preliminary results in accelerating thermal simulation, they face critical limitations in prediction capability for multi-scale thermal patterns, training efficiency, and trustworthiness of results during design optimization. This paper presents DeepOHeat-v1, an enhanced physics-informed operator learning framework that addresses these challenges through three key innovations. First, we integrate Kolmogorov-Arnold Networks with learnable activation functions as trunk networks, enabling an adaptive representation of multi-scale thermal patterns. This approach achieves a $1.25\times$ and $6.29\times$ reduction in error in two representative test cases. Second, we introduce a separable training method that decomposes the basis function along the coordinate axes, achieving $62\times$ training speedup and $31\times$ GPU memory reduction in our baseline case, and enabling thermal analysis at resolutions previously infeasible due to GPU memory constraints. Third, we propose a confidence score to evaluate the trustworthiness of the predicted results, and further develop a hybrid optimization workflow that combines operator learning with finite difference (FD) using Generalized Minimal Residual (GMRES) method for incremental solution refinement, enabling efficient and trustworthy thermal optimization. Experimental results demonstrate that DeepOHeat-v1 achieves accuracy comparable to optimization using high-fidelity finite difference solvers, while speeding up the entire optimization process by $70.6\times$ in our test cases, effectively minimizing the peak temperature through optimal placement of heat-generating components.
Ultra Memory-Efficient On-FPGA Training of Transformers via Tensor-Compressed Optimization
Jan 11, 2025Transformer models have achieved state-of-the-art performance across a wide range of machine learning tasks. There is growing interest in training transformers on resource-constrained edge devices due to considerations such as privacy, domain adaptation, and on-device scientific machine learning. However, the significant computational and memory demands required for transformer training often exceed the capabilities of an edge device. Leveraging low-rank tensor compression, this paper presents the first on-FPGA accelerator for end-to-end transformer training. On the algorithm side, we present a bi-directional contraction flow for tensorized transformer training, significantly reducing the computational FLOPS and intra-layer memory costs compared to existing tensor operations. On the hardware side, we store all highly compressed model parameters and gradient information on chip, creating an on-chip-memory-only framework for each stage in training. This reduces off-chip communication and minimizes latency and energy costs. Additionally, we implement custom computing kernels for each training stage and employ intra-layer parallelism and pipe-lining to further enhance run-time and memory efficiency. Through experiments on transformer models within $36.7$ to $93.5$ MB using FP-32 data formats on the ATIS dataset, our tensorized FPGA accelerator could conduct single-batch end-to-end training on the AMD Alevo U50 FPGA, with a memory budget of less than $6$-MB BRAM and $22.5$-MB URAM. Compared to uncompressed training on the NVIDIA RTX 3090 GPU, our on-FPGA training achieves a memory reduction of $30\times$ to $51\times$. Our FPGA accelerator also achieves up to $3.6\times$ less energy cost per epoch compared with tensor Transformer training on an NVIDIA RTX 3090 GPU.
Poor Man's Training on MCUs: A Memory-Efficient Quantized Back-Propagation-Free Approach
Nov 07, 2024



Back propagation (BP) is the default solution for gradient computation in neural network training. However, implementing BP-based training on various edge devices such as FPGA, microcontrollers (MCUs), and analog computing platforms face multiple major challenges, such as the lack of hardware resources, long time-to-market, and dramatic errors in a low-precision setting. This paper presents a simple BP-free training scheme on an MCU, which makes edge training hardware design as easy as inference hardware design. We adopt a quantized zeroth-order method to estimate the gradients of quantized model parameters, which can overcome the error of a straight-through estimator in a low-precision BP scheme. We further employ a few dimension reduction methods (e.g., node perturbation, sparse training) to improve the convergence of zeroth-order training. Experiment results show that our BP-free training achieves comparable performance as BP-based training on adapting a pre-trained image classifier to various corrupted data on resource-constrained edge devices (e.g., an MCU with 1024-KB SRAM for dense full-model training, or an MCU with 256-KB SRAM for sparse training). This method is most suitable for application scenarios where memory cost and time-to-market are the major concerns, but longer latency can be tolerated.